Clear Sky Science · pl
Nowy superpikselowy Vision Transformer poprawiający interpretowalność w przesiewowym badaniu jaskry
Dlaczego skany oczu i inteligentne maszyny mają znaczenie
Jaskra to cicha choroba oka, która może odebrać wzrok, zanim pacjent dostrzeże jakiekolwiek objawy. Lekarze potrafią wykryć wczesne sygnały ostrzegawcze na kolorowych fotografiach tylnej części oka, ale dokładne przejrzenie każdego obrazu jest czasochłonne i wymaga specjalistycznej wiedzy. Sztuczna inteligencja (SI) może pomóc, jednak wiele potężnych systemów działa jak „czarne skrzynki”, dając niewiele wskazówek, jak dochodzą do decyzji. W tym badaniu przedstawiono nowe podejście SI, które ma utrzymać wysoką dokładność, jednocześnie ułatwiając specjalistom okulistyki zrozumienie i zaufanie do procesu podejmowania decyzji.
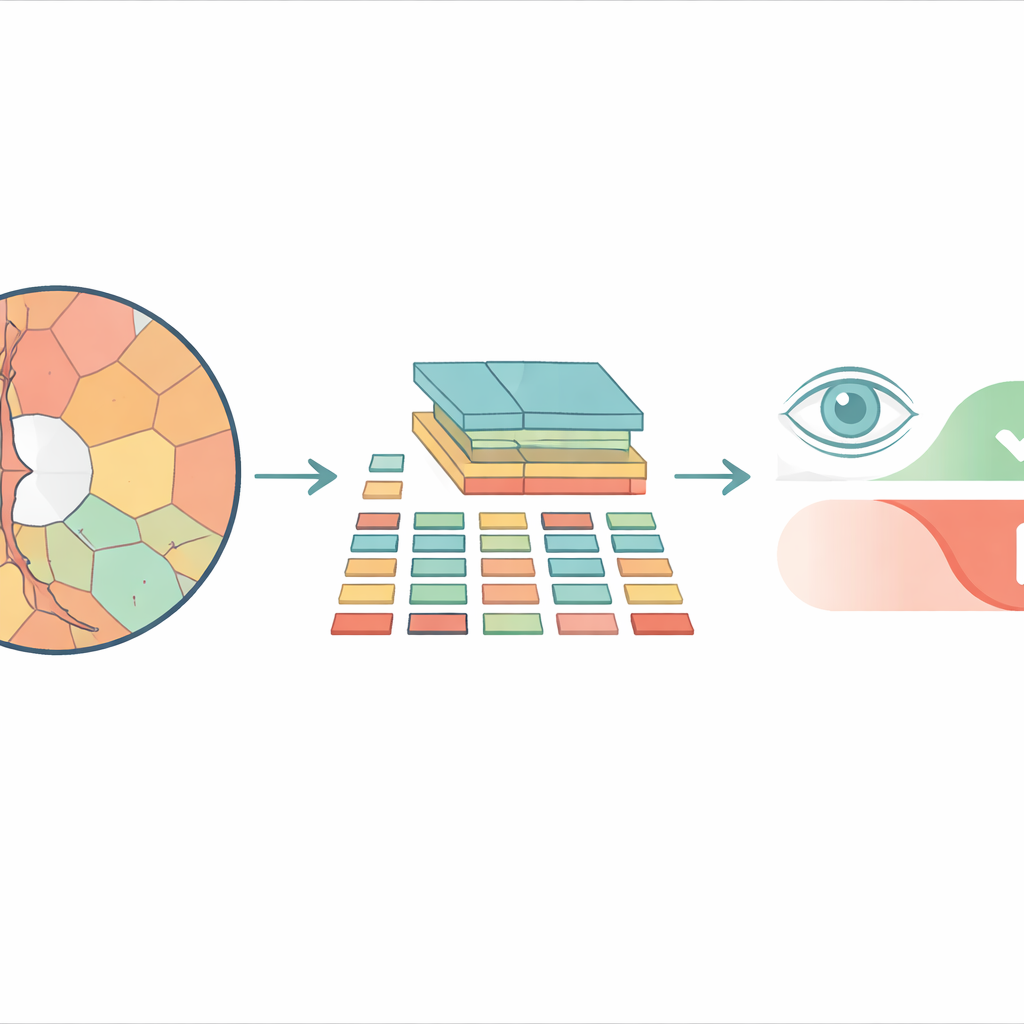
Od kwadratowych płytek do bardziej naturalnych obszarów
Większość nowoczesnych systemów analizy obrazu opartych na vision transformerach dzieli obraz na szachownicę identycznych kwadratowych płytek przed przetworzeniem. To może działać dobrze w przypadku zwykłych zdjęć, ale pomija to kształty rzeczywistych struktur oka. Tarcza nerwu wzrokowego i wewnętrzne zagłębienie zwane kubkiem mają zaokrąglone, nieregularne obrysy, a wtłaczanie ich w sztywne kwadraty miesza razem ważne i nieważne szczegóły. Badacze zamiast tego używają „superpikseli” — grup sąsiadujących pikseli o podobnym kolorze lub teksturze — aby podzielić obraz siatkówki na fragmenty podążające za rzeczywistymi granicami anatomicznymi. Te superpiksele stają się następnie podstawowymi jednostkami, czyli „tokenami”, które analizuje transformer.
Nowy sposób podawania obrazów do transformerów
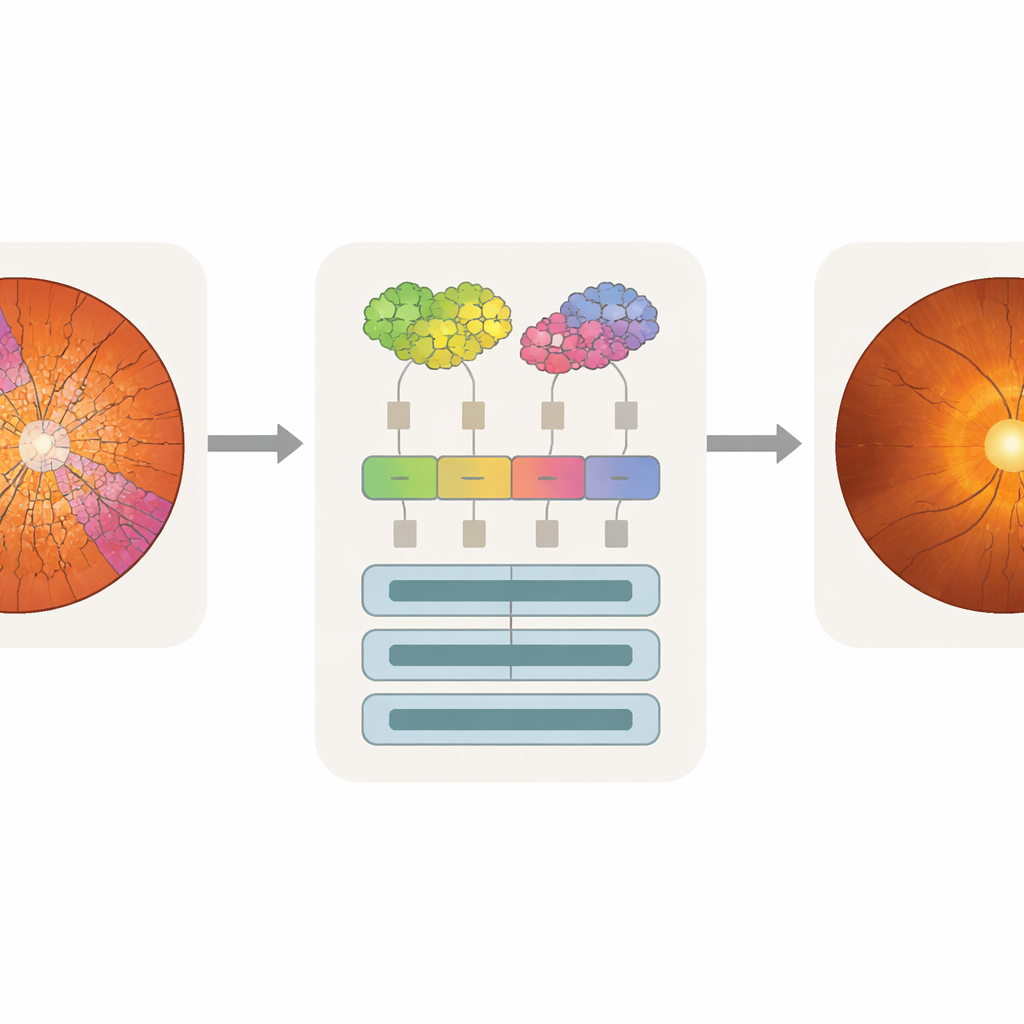
Proponowany model, nazwany Superpixel‑based Vision Transformer (SpxViT), pozostawia wewnętrzne mechanizmy standardowego vision transformera niemal bez zmian i koncentruje się na przeprojektowaniu frontendu. Zanim obraz trafi do transformera, istniejący algorytm (SLIC) dzieli go na 196 superpikseli, co mniej więcej odpowiada liczbie płytek używanych w powszechnym modelu odniesienia ViT‑B/16. Każdy nieregularny obszar jest konwertowany na numeryczny opis o stałej długości, aby można było traktować go jak zwykłą płytkę. Przetestowano dwie warianty: jeden używający stałego ustawienia sprzyjającego bardziej naturalnym kształtom (SpxViT_fix) oraz drugi, który dopasowuje to ustawienie dla każdego obrazu, aby zawsze uzyskać dokładnie 196 regionów (SpxViT_var). Poza tym krokiem tokenizacji warstwy transformera i procedura treningowa są takie same jak w klasycznym modelu, co umożliwia uczciwe porównanie.
Testowanie na rzeczywistych obrazach oka
Zespół ocenił swoją metodę na 739 fotografiach siatkówki pochodzących z bazy publicznej i zbioru szpitalnego, z których każdy obraz został oznaczony przez ekspertów od jaskry. Specjaliści również odrysowali granice tarczy i kubka, tworząc szczegółowe mapy najważniejszych klinicznie struktur. Kilka systemów opartych na transformerach szkolono od zera i porównano: standardowy ViT‑B/16 z kwadratowymi płytkami, inny superpikselowy projekt z wcześniejszych prac oraz dwie wersje SpxViT. Wydajność mierzono za pomocą powszechnych miar diagnostycznych, które równoważą zdolność modelu do wykrywania chorych oczu i prawidłowego odrzucania zdrowych. Klasyczny ViT‑B/16 osiągnął najlepszą ogólną dokładność, ale SpxViT_var znalazł się bardzo blisko, ustępując mniej niż o jeden punkt procentowy.
Skoordynowanie uwagi maszyny z okiem lekarza
Sama dokładność nie wystarcza w zastosowaniach klinicznych; lekarze muszą także wiedzieć, które części obrazu wpłynęły na decyzję modelu. Badacze zastosowali technikę analizy nazwaną attention rollout, która śledzi, ile każdy token wnosi do końcowej prognozy i przekształca to w mapę ciepła na oryginalnym obrazie. Ponieważ tokeny SpxViT podążają za obrysami tarczy i kubka, jego mapy uwagi naturalnie pokrywają się z tymi obszarami i unikają blokowego wzoru siatki charakterystycznego dla standardowych transformerów. Nakładając mapy ciepła na segmentacje ekspertów, zespół mógł obliczyć, jaka część uwagi przypadała na kubek, tarczę lub tło. Modele oparte na superpikselach, zwłaszcza SpxViT_var, koncentrówały większość uwagi na tarczy i kubku, jednocześnie w dużej mierze ignorując pozostałą część siatkówki. Specjalista od jaskry ocenił również przykładowe mapy wizualnie i uznał mapy z SpxViT_fix za najłatwiejsze do interpretacji, z wyraźnym podświetleniem struktur używanych w rzeczywistej diagnostyce.
Równoważenie zaufania i wydajności w SI dla opieki okulistycznej
Badanie pokazuje, że zmiana sposobu dzielenia obrazu na fragmenty może uczynić systemy SI do przesiewu jaskry bardziej przejrzystymi bez poważnej utraty dokładności. Choć klasyczny transformer wyprzedza nową metodę pod względem samych liczb, SpxViT generuje wyjaśnienia lepiej dopasowane do rozumowania klinicznego, skupiając się na tarczy i kubku zamiast na rozproszonych lub siatkowych wzorcach. W codziennej praktyce taka wymiana może być opłacalna: model, który lekarze rozumieją i mogą poddać krytyce, ma większe szanse na przyjęcie i bezpieczną integrację w programach przesiewowych. Autorzy argumentują, że podobne projekty oparte na superpikselach mogłyby pomóc wprowadzić interpretowalną SI do innych zadań obrazowania medycznego, gdzie wiedza o tym, gdzie model patrzy, jest równie ważna jak to, czy ma rację.
Cytowanie: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
Słowa kluczowe: przesiewowe badanie jaskry, obrazowanie siatkówki, vision transformers, wyjaśnialna sztuczna inteligencja, superpiksele