Clear Sky Science · en
A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening
Why eye scans and smart machines matter
Glaucoma is a silent eye disease that can steal vision before people notice any symptoms. Doctors can spot early warning signs in color photographs of the back of the eye, but carefully examining each image is time‑consuming and requires expertise. Artificial intelligence (AI) can help, yet many powerful systems behave like “black boxes,” offering little insight into how they reach a verdict. This study introduces a new AI approach that aims to keep high accuracy while making its reasoning easier for eye specialists to see and trust.
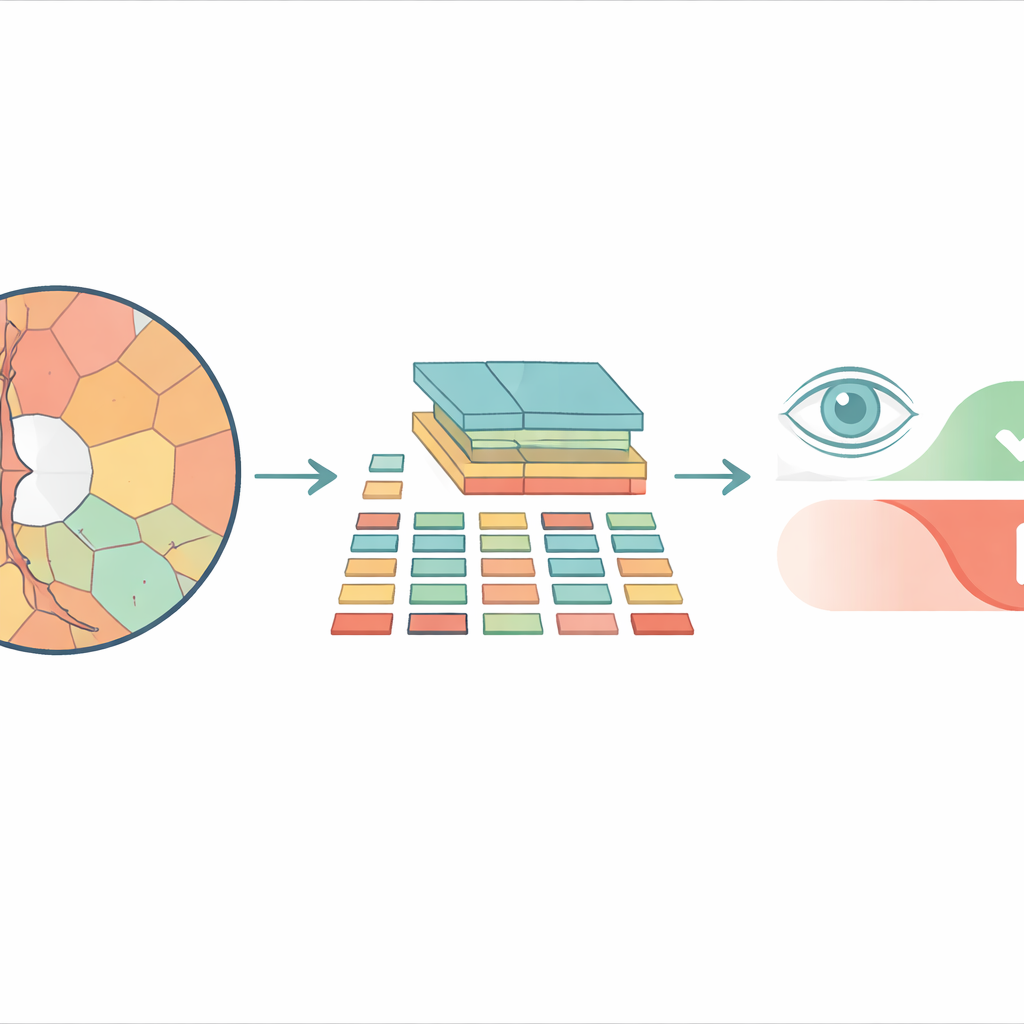
From square tiles to more natural regions
Most modern image‑analysis systems based on vision transformers break a picture into a checkerboard of identical square tiles before processing it. That may work well for everyday photos, but it ignores how real structures in the eye are shaped. The optic disc and the inner depression called the cup have curved, irregular outlines, and forcing them into rigid squares mixes important and unimportant details together. The researchers instead use “superpixels” — groups of neighboring pixels that share similar color or texture — to carve the retinal image into pieces that follow actual anatomical boundaries. These superpixels then become the basic units, or “tokens,” that the transformer analyzes.
A new way to feed images into transformers
The proposed model, called Superpixel‑based Vision Transformer (SpxViT), keeps the internal machinery of a standard vision transformer almost unchanged and focuses on redesigning the front end. Before the image reaches the transformer, an existing algorithm (SLIC) divides it into 196 superpixels, roughly matching the number of tiles used in a common baseline model called ViT‑B/16. Each irregular region is converted into a fixed‑length numeric description so it can be handled just like a normal tile. Two variants are tested: one that uses a constant setting to favor more natural shapes (SpxViT_fix) and another that adjusts this setting for each image to always produce exactly 196 regions (SpxViT_var). Apart from this tokenization step, the transformer layers and training procedure are the same as in the classic model, which allows a fair comparison.
Testing on real eye images
The team evaluated their method on 739 retinal photographs from a public database and a hospital collection, with each image labeled by glaucoma experts. Specialists also traced the boundaries of the optic disc and cup, creating detailed maps of the most clinically important structures. Several transformer‑based systems were trained from scratch and compared: the standard ViT‑B/16 with square tiles, another superpixel‑based design from previous work, and the two SpxViT versions. Performance was measured using common diagnostic scores that balance how well a model detects diseased eyes and correctly dismisses healthy ones. The classic ViT‑B/16 achieved the best overall accuracy, but SpxViT_var came very close, trailing by less than one percentage point.
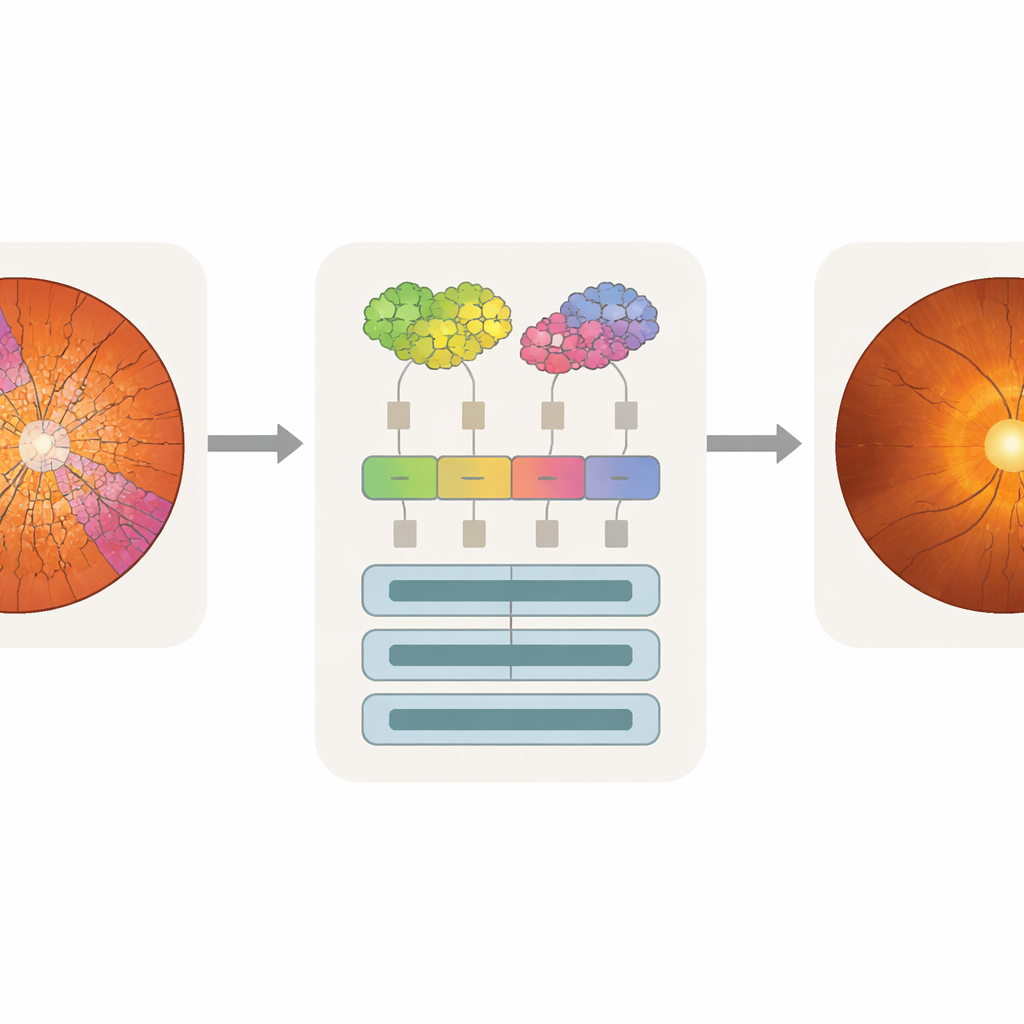
Making machine attention match the doctor’s eye
Accuracy alone is not enough for clinical use; doctors also need to know what parts of an image influenced a model’s decision. The researchers used an analysis technique called attention rollout, which traces how much each token contributes to the final prediction and turns this into a heat map over the original image. Because SpxViT tokens follow the disc and cup outlines, its attention maps naturally align with those regions and avoid the blocky grid pattern seen in standard transformers. By overlaying the heat maps with the expert segmentations, the team could compute how much attention fell on the cup, the disc, or the background. The superpixel models, especially SpxViT_var, concentrated most of their attention on the disc and cup while largely ignoring the rest of the retina. A glaucoma specialist also rated example maps by eye and found those from SpxViT_fix the easiest to interpret, with clear highlighting of the structures used in real diagnosis.
Balancing trust and performance in eye‑care AI
The study shows that reshaping how images are broken into pieces can make AI systems for glaucoma screening more transparent without seriously sacrificing accuracy. While the classic transformer edges out the new method in pure numbers, SpxViT produces explanations that better match clinical reasoning by focusing on the optic disc and cup instead of scattered or grid‑shaped patterns. For everyday practice, this trade‑off may be worthwhile: a model that doctors can understand and question is more likely to be adopted and safely integrated into screening programs. The authors argue that similar superpixel‑based designs could help bring interpretable AI to other medical imaging tasks where knowing where the model looks is just as important as whether it is right.
Citation: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
Keywords: glaucoma screening, retinal imaging, vision transformers, explainable AI, superpixels