Clear Sky Science · pt
Um novo Vision Transformer baseado em superpixels para melhorar a interpretabilidade no rastreamento do glaucoma
Por que exames oculares e máquinas inteligentes importam
O glaucoma é uma doença ocular silenciosa que pode roubar a visão antes que as pessoas percebam quaisquer sintomas. Médicos podem identificar sinais precoces em fotografias coloridas do fundo do olho, mas examinar cada imagem com atenção consome tempo e exige especialização. A inteligência artificial (IA) pode ajudar, porém muitos sistemas poderosos agem como “caixas‑pretas”, oferecendo pouca visibilidade sobre como chegam a um veredito. Este estudo apresenta uma nova abordagem de IA que busca manter alta precisão ao mesmo tempo em que torna seu raciocínio mais fácil de ver e confiar para os especialistas em olhos.
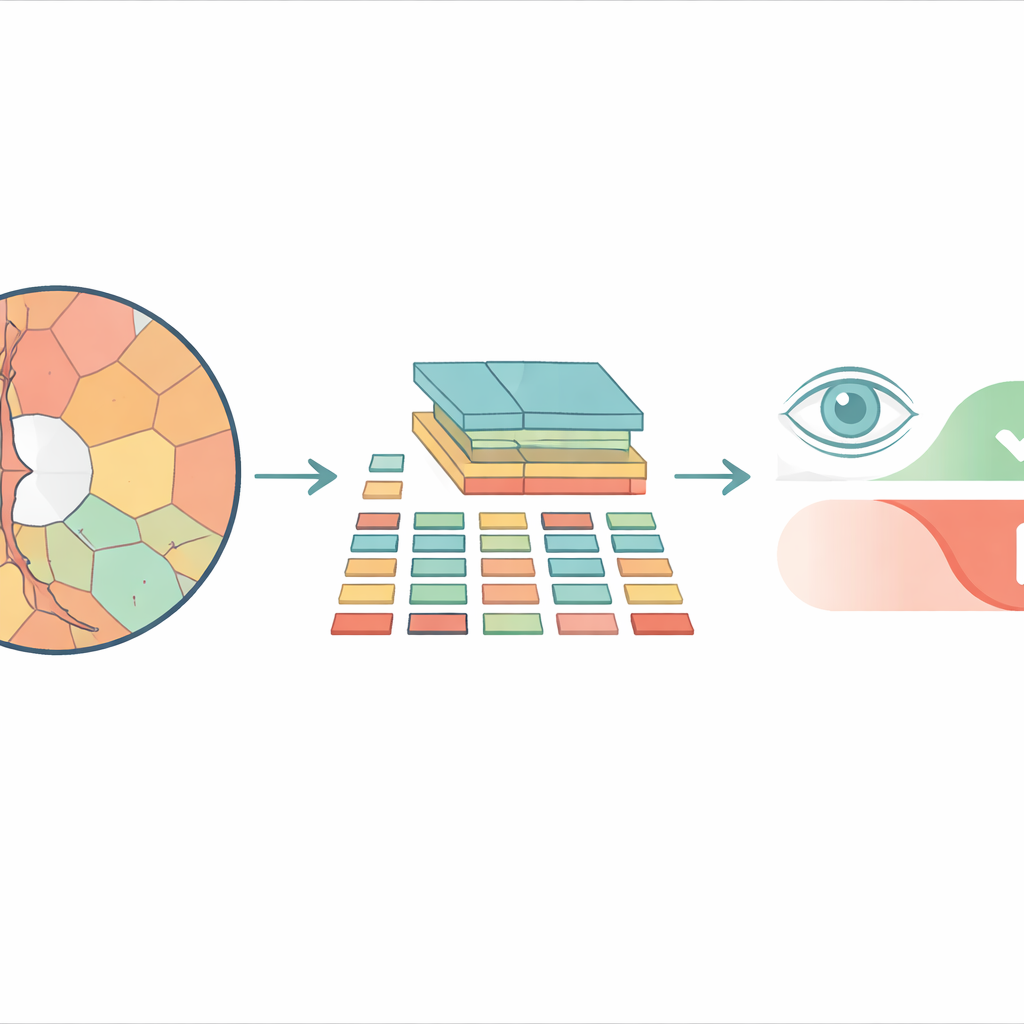
De blocos quadrados para regiões mais naturais
A maioria dos sistemas modernos de análise de imagens baseada em vision transformers divide uma imagem em um tabuleiro de peças quadradas idênticas antes de processá‑la. Isso pode funcionar bem para fotos do dia a dia, mas ignora como as estruturas reais do olho são formadas. O disco óptico e a depressão interna chamada escavação (cup) têm contornos curvos e irregulares, e forçá‑los em quadrados rígidos mistura detalhes importantes com irrelevantes. Os pesquisadores, em vez disso, usam “superpixels” — grupos de pixels vizinhos que compartilham cor ou textura semelhantes — para recortar a imagem da retina em peças que seguem limites anatômicos reais. Esses superpixels tornam‑se então as unidades básicas, ou “tokens”, que o transformer analisa.
Uma nova maneira de alimentar imagens em transformers
O modelo proposto, chamado Superpixel‑based Vision Transformer (SpxViT), mantém a mecânica interna de um vision transformer padrão quase inalterada e concentra‑se em redesenhar a etapa inicial. Antes de a imagem chegar ao transformer, um algoritmo conhecido (SLIC) a divide em 196 superpixels, aproximando‑se do número de blocos usados em um modelo de referência comum chamado ViT‑B/16. Cada região irregular é convertida em uma descrição numérica de comprimento fixo para que possa ser tratada como um bloco normal. Duas variantes foram testadas: uma que usa uma configuração constante para favorecer formas mais naturais (SpxViT_fix) e outra que ajusta essa configuração para cada imagem, produzindo sempre exatamente 196 regiões (SpxViT_var). À parte essa etapa de tokenização, as camadas do transformer e o procedimento de treinamento são os mesmos do modelo clássico, o que permite uma comparação justa.
Testando em imagens reais do olho
A equipe avaliou seu método em 739 fotografias de retina provenientes de um banco de dados público e de uma coleção hospitalar, com cada imagem rotulada por especialistas em glaucoma. Os especialistas também contornaram os limites do disco óptico e da escavação, criando mapas detalhados das estruturas clinicamente mais importantes. Vários sistemas baseados em transformer foram treinados do zero e comparados: o ViT‑B/16 padrão com blocos quadrados, outro projeto baseado em superpixels de trabalhos anteriores e as duas versões do SpxViT. O desempenho foi medido usando escores diagnósticos comuns que equilibram quão bem um modelo detecta olhos doentes e descarta corretamente os saudáveis. O ViT‑B/16 clássico obteve a melhor acurácia geral, mas o SpxViT_var chegou muito perto, ficando atrás por menos de um ponto percentual.
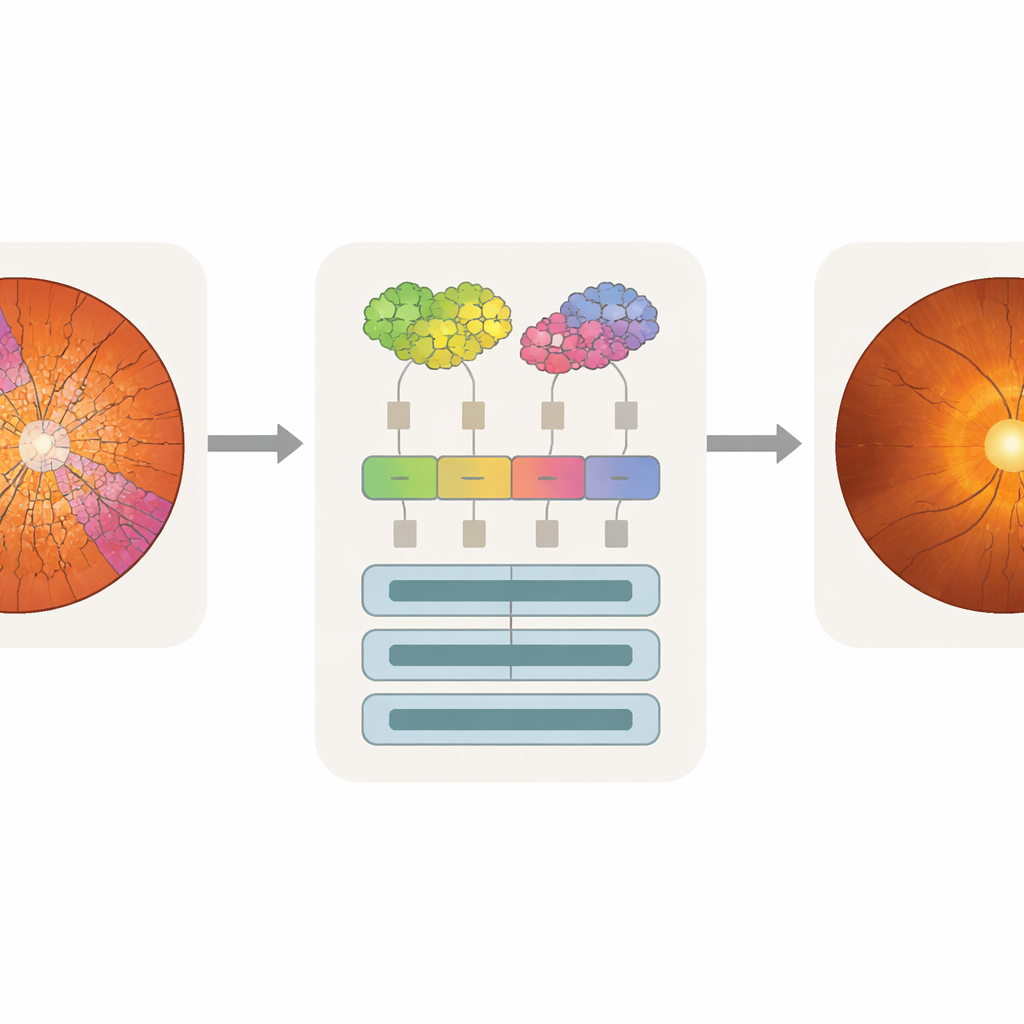
Fazer a atenção da máquina coincidir com o olhar do médico
Apenas a acurácia não é suficiente para uso clínico; médicos também precisam saber quais partes de uma imagem influenciaram a decisão de um modelo. Os pesquisadores usaram uma técnica de análise chamada attention rollout, que rastreia quanto cada token contribui para a predição final e transforma isso em um mapa de calor sobre a imagem original. Como os tokens do SpxViT seguem os contornos do disco e da escavação, seus mapas de atenção alinham‑se naturalmente com essas regiões e evitam o padrão em grade visto nos transformers padrão. Ao sobrepor os mapas de calor com as segmentações dos especialistas, a equipe pôde calcular quanto da atenção caiu sobre a escavação, o disco ou o fundo. Os modelos baseados em superpixels, especialmente o SpxViT_var, concentraram a maior parte da atenção no disco e na escavação, enquanto em grande parte ignoraram o restante da retina. Um especialista em glaucoma também avaliou visualmente mapas de exemplo e considerou os do SpxViT_fix os mais fáceis de interpretar, com realce claro das estruturas usadas no diagnóstico real.
Equilibrando confiança e desempenho na IA para cuidados oculares
O estudo mostra que reconfigurar como as imagens são divididas em peças pode tornar sistemas de IA para rastreamento do glaucoma mais transparentes sem sacrificar seriamente a precisão. Embora o transformer clássico supere o novo método em números puros, o SpxViT produz explicações que se alinham melhor com o raciocínio clínico ao focar no disco óptico e na escavação em vez de padrões dispersos ou em grade. Na prática diária, essa troca pode valer a pena: um modelo que os médicos consigam entender e questionar tem maior probabilidade de ser adotado e integrado com segurança em programas de rastreamento. Os autores argumentam que projetos semelhantes baseados em superpixels podem ajudar a levar IA interpretável a outras tarefas de imagem médica onde saber onde o modelo observa é tão importante quanto ele estar certo.
Citação: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
Palavras-chave: rastreamento do glaucoma, imagens da retina, vision transformers, IA explicável, superpixels