Clear Sky Science · de
Ein neuartiger superpixelbasierter Vision Transformer zur Verbesserung der Interpretierbarkeit beim Glaukom-Screening
Warum Augenaufnahmen und intelligente Maschinen wichtig sind
Glaukom ist eine stille Augenkrankheit, die das Sehvermögen rauben kann, bevor Betroffene Symptome bemerken. Ärztinnen und Ärzte können Frühwarnzeichen auf Farbfotos des Augenhintergrunds erkennen, doch das sorgfältige Durchsehen jeder Aufnahme ist zeitaufwendig und erfordert Fachwissen. Künstliche Intelligenz (KI) kann unterstützen, doch viele leistungsstarke Systeme verhalten sich wie „Black Boxes“ und liefern kaum Einblick, wie sie zu einem Urteil kommen. Diese Studie stellt einen neuen KI-Ansatz vor, der hohe Genauigkeit bewahren will und zugleich die Nachvollziehbarkeit der Entscheidungsfindung für Augenärztinnen und -ärzte verbessert.
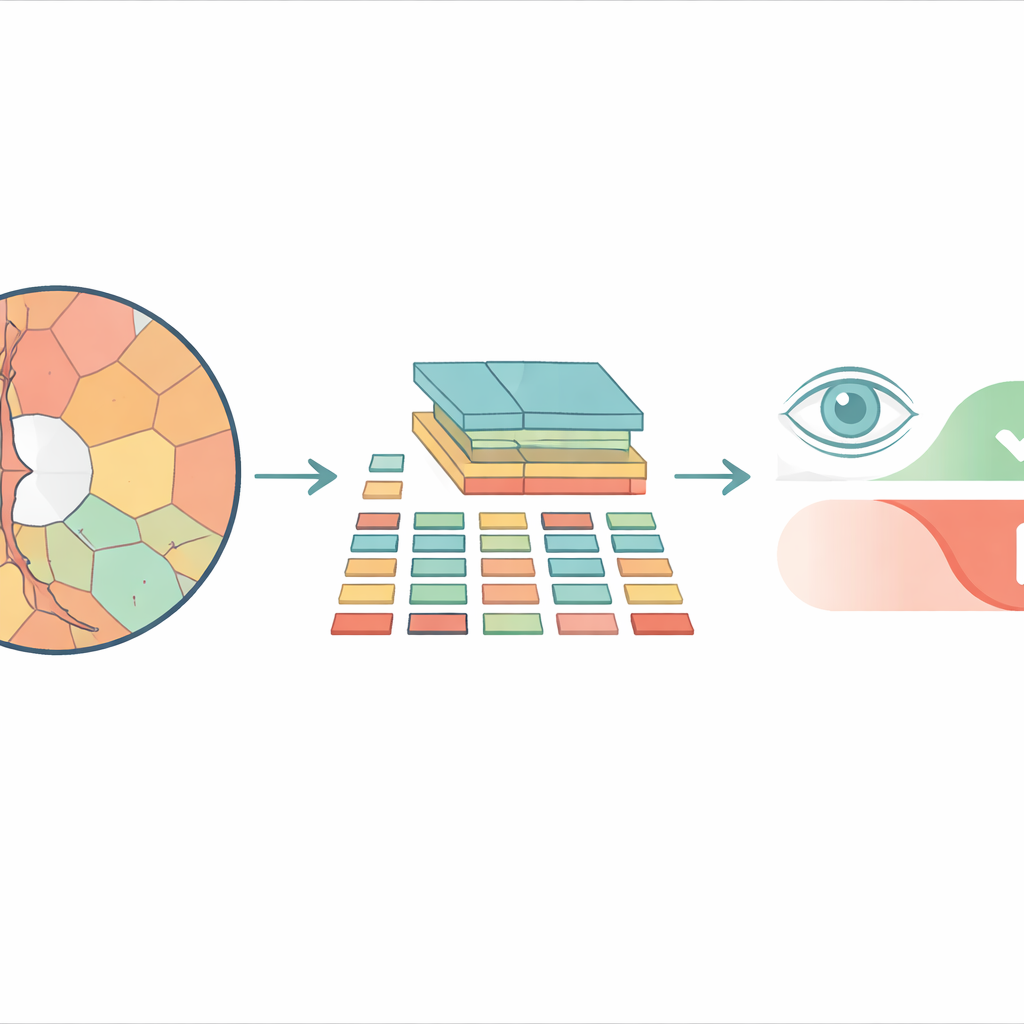
Von quadratischen Kacheln zu natürlicheren Regionen
Die meisten modernen bildanalytischen Systeme auf Basis von Vision Transformers zerlegen ein Bild vor der Verarbeitung in ein Schachbrettmuster aus identischen quadratischen Kacheln. Das funktioniert in Alltagsfotos oft gut, übersieht aber die tatsächliche Form von Strukturen im Auge. Der Sehnervenkopf (Optic Disc) und die innere Vertiefung, die Cup genannt wird, haben geschwungene, unregelmäßige Umrisse, und das Erzwingen starrer Quadrate vermischt wichtige mit unwichtigen Details. Die Forscher verwenden stattdessen „Superpixel“ — Gruppen benachbarter Pixel mit ähnlicher Farbe oder Textur — um das Netzhautbild in Bereiche zu schneiden, die tatsächlichen anatomischen Grenzen folgen. Diese Superpixel werden dann zu den grundlegenden Einheiten oder „Tokens“, die der Transformer analysiert.
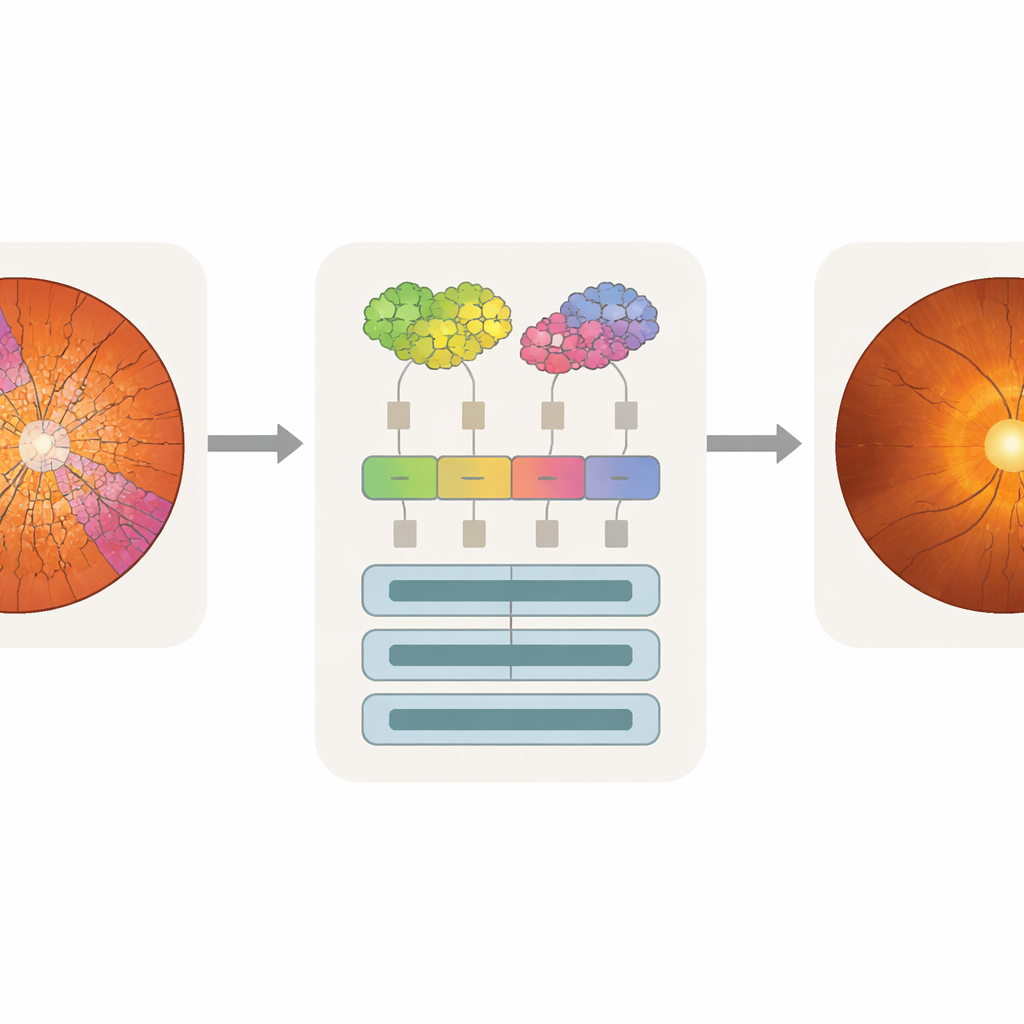
Eine neue Methode, Bilder in Transformer einzuspeisen
Das vorgeschlagene Modell, Superpixel-basierter Vision Transformer (SpxViT), belässt die innere Mechanik eines Standard-Vision-Transformers weitgehend unverändert und konzentriert sich auf die Neugestaltung des Frontends. Bevor das Bild den Transformer erreicht, teilt ein etablierter Algorithmus (SLIC) es in 196 Superpixel auf, was in etwa der Anzahl von Kacheln entspricht, die im gebräuchlichen Basismodell ViT-B/16 verwendet werden. Jede unregelmäßige Region wird in eine numerische Beschreibung fester Länge überführt, sodass sie wie eine normale Kachel verarbeitet werden kann. Es werden zwei Varianten getestet: eine mit einer konstanten Einstellung, die natürlichere Formen begünstigt (SpxViT_fix), und eine, die diese Einstellung für jedes Bild anpasst, um immer genau 196 Regionen zu erzeugen (SpxViT_var). Abgesehen von diesem Tokenisierungs-Schritt sind die Transformer-Schichten und das Trainingsverfahren identisch mit dem klassischen Modell, was einen fairen Vergleich ermöglicht.
Test an realen Augenaufnahmen
Das Team bewertete die Methode an 739 Netzhautfotos aus einer öffentlichen Datenbank und einer Krankenhauskollektion, wobei jedes Bild von Glaukom-Expertinnen und -Experten beschriftet wurde. Die Spezialistinnen und Spezialisten zeichneten außerdem die Umrisse von Optic Disc und Cup nach und erstellten detaillierte Karten der klinisch wichtigsten Strukturen. Mehrere transformerbasierte Systeme wurden von Grund auf trainiert und verglichen: das Standardmodell ViT-B/16 mit quadratischen Kacheln, ein weiteres superpixelbasiertes Design aus früherer Arbeit sowie die beiden SpxViT-Versionen. Die Leistung wurde mit gängigen diagnostischen Kennzahlen gemessen, die abwägen, wie gut ein Modell kranke Augen erkennt und gesunde korrekt ausschließt. Der klassische ViT-B/16 erzielte die höchste Gesamtgenauigkeit, doch SpxViT_var kam sehr nahe und lag weniger als einen Prozentpunkt zurück.
Maschinelle Aufmerksamkeit an das Auge des Arztes angleichen
Allein die Genauigkeit reicht für den klinischen Einsatz nicht aus; Ärztinnen und Ärzte müssen auch wissen, welche Bildbereiche die Entscheidung eines Modells beeinflusst haben. Die Forscher verwendeten eine Analysetechnik namens Attention Rollout, die nachverfolgt, wie viel Beitrag jedes Token zur Endvorhersage leistet, und dies in eine Heatmap über das Originalbild überträgt. Da sich die SpxViT-Tokens an den Umrissen von Disc und Cup orientieren, stimmen die Aufmerksamkeitskarten natürlicherweise mit diesen Regionen überein und vermeiden das blockige Gittermuster, das bei Standard-Transformern auftritt. Durch Überlagern der Heatmaps mit den Expertensegmentierungen konnte das Team berechnen, wie viel Aufmerksamkeit auf Cup, Disc oder Hintergrund entfiel. Die Superpixel-Modelle, insbesondere SpxViT_var, konzentrierten den größten Teil ihrer Aufmerksamkeit auf Disc und Cup und ignorierten weitgehend den übrigen Bereich der Netzhaut. Ein Glaukom-Spezialist bewertete Beispielkarten zudem visuell und fand die Karten von SpxViT_fix am leichtesten zu interpretieren, mit klarer Hervorhebung der Strukturen, die in der klinischen Diagnose relevant sind.
Vertrauen und Leistung in der Augenheilkunde ausbalancieren
Die Studie zeigt, dass das Umgestalten der Zerlegung von Bildern in Teile KI-Systeme für das Glaukom-Screening transparenter machen kann, ohne die Genauigkeit ernsthaft zu schmälern. Zwar übertrifft der klassische Transformer die neue Methode in reinen Kennzahlen, doch SpxViT liefert Erklärungen, die besser mit klinischem Denken übereinstimmen, weil es sich auf Optic Disc und Cup statt auf verstreute oder gitterförmige Muster konzentriert. Für den täglichen Gebrauch kann sich dieser Kompromiss lohnen: Ein Modell, das Ärztinnen und Ärzte verstehen und hinterfragen können, wird eher übernommen und sicher in Screenings integriert. Die Autorinnen und Autoren argumentieren, dass ähnliche superpixelbasierte Entwürfe dazu beitragen könnten, erklärbare KI in andere medizinische Bildgebungsaufgaben zu bringen, in denen zu wissen, wo das Modell hinschaut, genauso wichtig ist wie die Frage, ob es richtig liegt.
Zitation: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
Schlüsselwörter: Glaukom-Screening, Retina-Bildgebung, Vision Transformer, erklärbare KI, Superpixel