Clear Sky Science · fr
Un nouveau Vision Transformer basé sur des superpixels pour améliorer l’interprétabilité du dépistage du glaucome
Pourquoi les examens oculaires et les machines intelligentes comptent
Le glaucome est une maladie oculaire silencieuse qui peut voler la vision avant que les personnes ne remarquent des symptômes. Les médecins peuvent repérer des signes précoces sur des photographies couleur du fond de l’œil, mais examiner chaque image attentivement prend du temps et demande de l’expertise. L’intelligence artificielle (IA) peut aider, toutefois de nombreux systèmes puissants se comportent comme des « boîtes noires », offrant peu d’indications sur la manière dont ils aboutissent à un verdict. Cette étude présente une nouvelle approche d’IA qui vise à conserver une grande précision tout en rendant son raisonnement plus facile à visualiser et à approuver pour les spécialistes de l’œil.
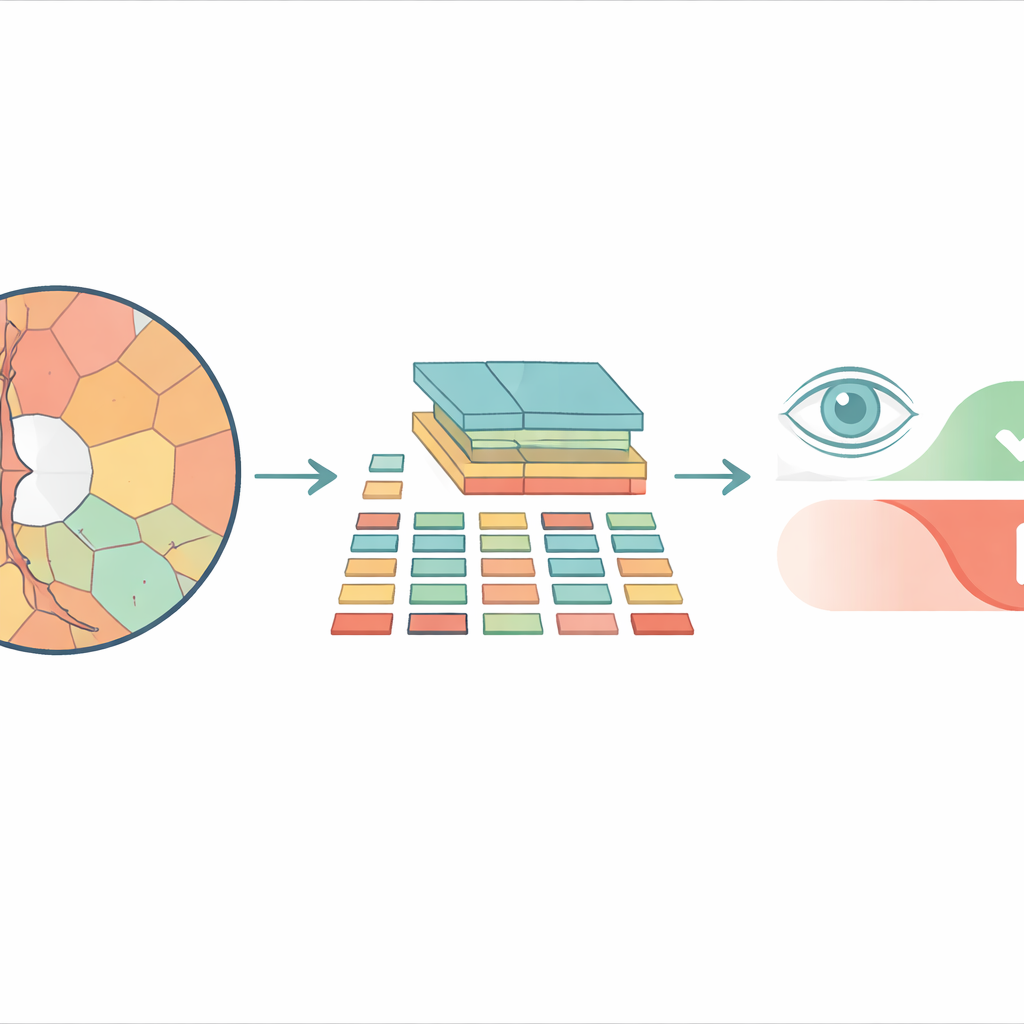
Des tuiles carrées à des régions plus naturelles
La plupart des systèmes modernes d’analyse d’images basés sur des vision transformers découpent une image en une grille d’éléments carrés identiques avant de la traiter. Cela peut bien fonctionner pour des photos courantes, mais ignore la façon dont les structures réelles de l’œil sont formées. Le disque optique et la dépression interne appelée cup ont des contours courbes et irréguliers, et les contraindre en cases rigides mélange des détails importants et non pertinents. Les chercheurs utilisent plutôt des « superpixels » — des groupes de pixels voisins partageant une couleur ou une texture similaire — pour découper l’image rétinienne en segments qui suivent les limites anatomiques réelles. Ces superpixels deviennent ensuite les unités de base, ou « tokens », que le transformer analyse.
Une nouvelle façon d’alimenter les transformers avec des images
Le modèle proposé, appelé Superpixel‑based Vision Transformer (SpxViT), conserve la mécanique interne d’un vision transformer standard presque inchangée et se concentre sur la refonte de la partie frontale. Avant que l’image n’atteigne le transformer, un algorithme existant (SLIC) la divise en 196 superpixels, ce qui correspond approximativement au nombre de tuiles utilisées dans un modèle de référence courant appelé ViT‑B/16. Chaque région irrégulière est convertie en une description numérique de longueur fixe afin d’être traitée comme une tuile normale. Deux variantes sont testées : l’une utilise un réglage constant pour favoriser des formes plus naturelles (SpxViT_fix) et l’autre ajuste ce réglage pour chaque image afin de produire exactement 196 régions (SpxViT_var). À part cette étape de tokenisation, les couches du transformer et la procédure d’entraînement sont les mêmes que dans le modèle classique, ce qui permet une comparaison équitable.
Tests sur de vraies images oculaires
L’équipe a évalué sa méthode sur 739 photographies rétiniennes provenant d’une base de données publique et d’une collection hospitalière, chaque image étant annotée par des experts du glaucome. Les spécialistes ont également tracé les limites du disque optique et de la cup, créant des cartes détaillées des structures cliniquement les plus importantes. Plusieurs systèmes basés sur des transformers ont été entraînés depuis zéro et comparés : le ViT‑B/16 standard avec tuiles carrées, un autre dispositif basé sur des superpixels issu de travaux antérieurs, et les deux versions de SpxViT. La performance a été mesurée à l’aide de scores diagnostiques courants qui équilibrent la détection des yeux malades et le bon rejet des yeux sains. Le ViT‑B/16 classique a obtenu la meilleure exactitude globale, mais SpxViT_var s’en est approché, avec un retard inférieur à un point de pourcentage.
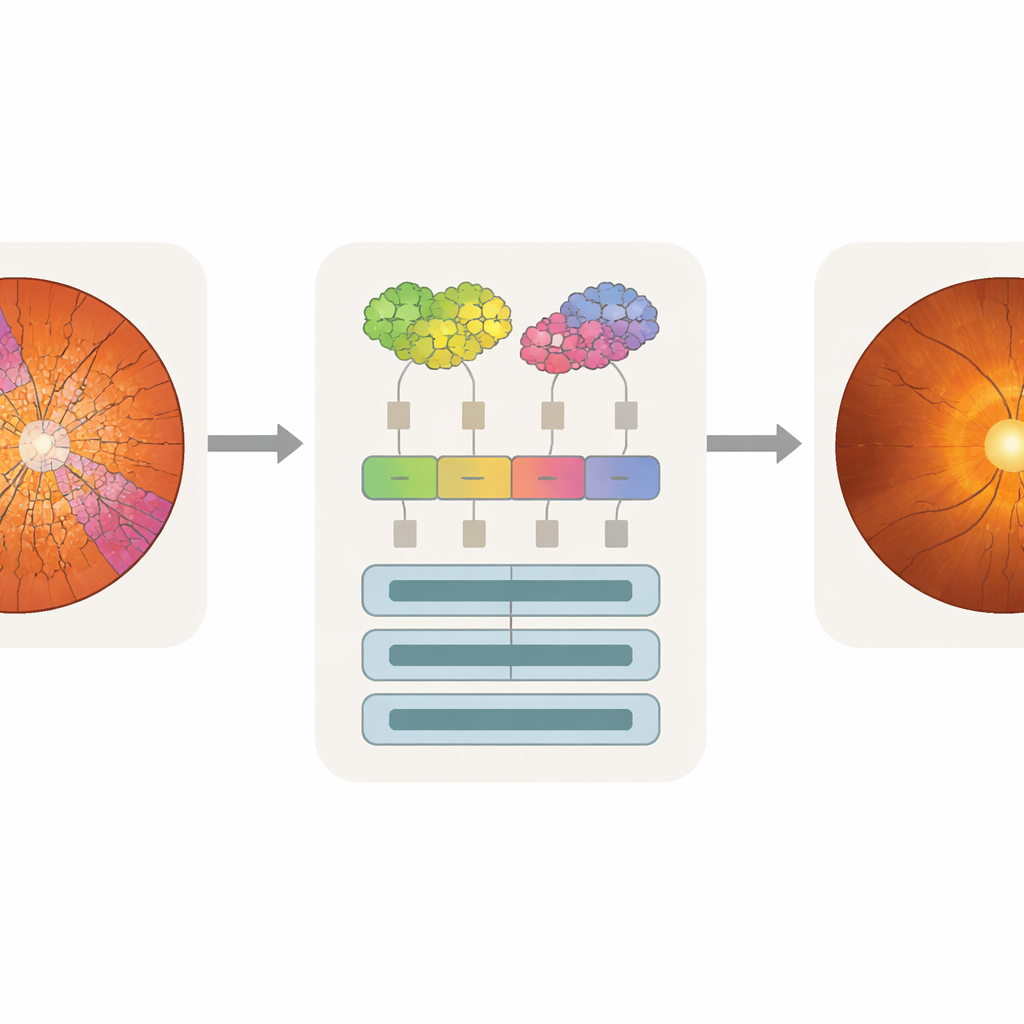
Faire correspondre l’attention machine au regard du médecin
L’exactitude seule ne suffit pas en clinique ; les médecins doivent aussi savoir quelles parties d’une image ont influencé la décision d’un modèle. Les chercheurs ont utilisé une technique d’analyse appelée attention rollout, qui retrace la contribution de chaque token à la prédiction finale et la transforme en une carte de chaleur sur l’image d’origine. Parce que les tokens de SpxViT suivent les contours du disque et de la cup, ses cartes d’attention s’alignent naturellement sur ces régions et évitent le motif quadrillé vu dans les transformers standards. En superposant les cartes de chaleur avec les segmentations d’experts, l’équipe a pu calculer la part d’attention portant sur la cup, le disque ou l’arrière‑plan. Les modèles basés sur des superpixels, en particulier SpxViT_var, ont concentré la plupart de leur attention sur le disque et la cup tout en ignorant largement le reste de la rétine. Un spécialiste du glaucome a également évalué visuellement des cartes d’exemple et a trouvé celles de SpxViT_fix les plus faciles à interpréter, avec une mise en évidence claire des structures utilisées dans le diagnostic réel.
Équilibrer confiance et performance dans l’IA pour les soins oculaires
L’étude montre que remodeler la manière dont les images sont découpées peut rendre les systèmes d’IA pour le dépistage du glaucome plus transparents sans sacrifier sérieusement la précision. Alors que le transformer classique devance la nouvelle méthode en chiffres purs, SpxViT produit des explications qui correspondent mieux au raisonnement clinique en se focalisant sur le disque optique et la cup plutôt que sur des motifs dispersés ou en grille. Pour la pratique quotidienne, ce compromis peut valoir le coup : un modèle que les médecins peuvent comprendre et interroger est plus susceptible d’être adopté et intégré en toute sécurité dans les programmes de dépistage. Les auteurs soutiennent que des conceptions similaires basées sur des superpixels pourraient aider à apporter une IA interprétable à d’autres tâches d’imagerie médicale où savoir où le modèle regarde est aussi important que savoir s’il a raison.
Citation: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
Mots-clés: dépistage du glaucome, imagerie rétinienne, vision transformers, IA explicable, superpixels