Clear Sky Science · ar
محول رؤية جديد قائم على السوبر‑بيكسل لتحسين قابلية التفسير في فحص الزَرَق
لماذا تهم فحوصات العين والآلات الذكية
الزَرَق مرض عيني صامت يمكن أن يسرق البصر قبل أن يلاحظ الأشخاص أي أعراض. يستطيع الأطباء اكتشاف علامات الإنذار المبكرة في صور ملونة لجزء خلفي من العين، لكن فحص كل صورة بعناية يستغرق وقتًا ويتطلب خبرة. يمكن للذكاء الاصطناعي أن يساعد، إلا أن العديد من الأنظمة القوية تتصرف كـ «صناديق سوداء» ولا توفر سوى القليل من الشرح لطريقة الوصول إلى القرار. تقدم هذه الدراسة نهجًا جديدًا للذكاء الاصطناعي يهدف إلى الحفاظ على دقة عالية مع جعل استدلاله أسهل على أخصائيي العيون لرؤيته والثقة به.
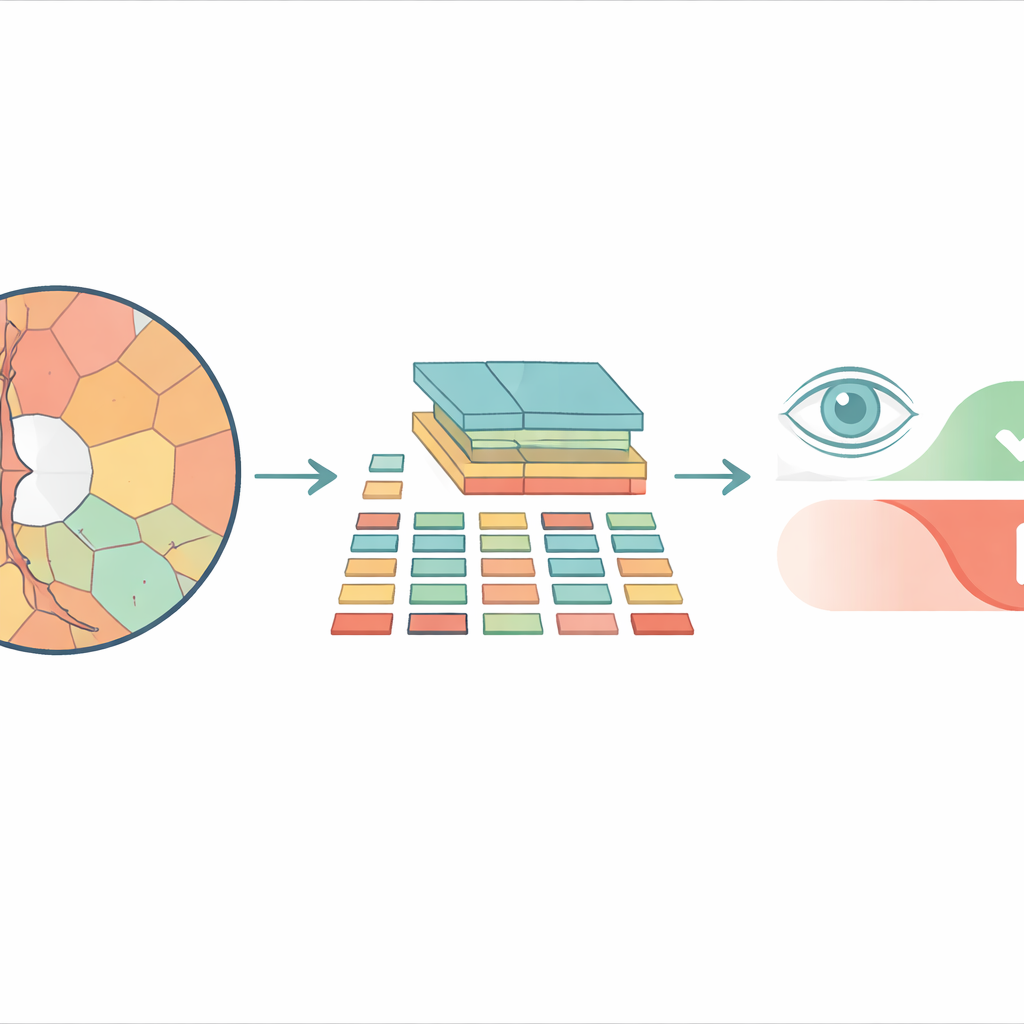
من المربعات إلى مناطق أكثر طبيعية
معظم أنظمة تحليل الصور الحديثة المبنية على محولات الرؤية تقسم الصورة إلى شبكة شطرنجية من المربعات المتطابقة قبل معالجتها. قد يعمل ذلك جيدًا للصور اليومية، لكنه يتجاهل كيفية تشكل الهياكل الحقيقية في العين. القرص البصري والانخفاض الداخلي المسمى الحُفرة لهما محاذير منحنية وغير منتظمة، وإجبارهما على الانطباق داخل مربعات صارمة يخلط بين التفاصيل المهمة وغير المهمة. بدلاً من ذلك يستخدم الباحثون «السوبر‑بيكسلات» — مجموعات من البكسلات المتجاورة التي تشترك في لون أو نسيج مماثل — لتقطيع صورة الشبكية إلى أجزاء تتبع الحدود التشريحية الفعلية. تصبح هذه السوبر‑بيكسلات بعدها الوحدات الأساسية، أو «الرموز»، التي يحللها المحول.
طريقة جديدة لإدخال الصور إلى المحولات
النموذج المقترح، المسمى محول الرؤية القائم على السوبر‑بيكسل (SpxViT)، يحتفظ بالآلية الداخلية لمحول الرؤية القياسي دون تغيير تقريبًا ويركز على إعادة تصميم الواجهة الأمامية. قبل أن تصل الصورة إلى المحول، يقسمها خوارزم موجود (SLIC) إلى 196 سوبر‑بيكسل، ما يقارب عدد المربعات المستخدمة في نموذج مرجعي شائع اسمه ViT‑B/16. تُحوّل كل منطقة غير منتظمة إلى وصف رقمي بطول ثابت بحيث يمكن معالجتها تمامًا مثل بلاطة عادية. تم اختبار متغيرين: واحد يستخدم إعدادًا ثابتًا ليفضل أشكالًا أكثر طبيعية (SpxViT_fix) وآخر يعدّل هذا الإعداد لكل صورة لإنتاج 196 منطقة بالضبط دائمًا (SpxViT_var). باستثناء خطوة التقطيع هذه، تبقى طبقات المحول وإجراءات التدريب كما هي في النموذج الكلاسيكي، مما يسمح بمقارنة عادلة.
الاختبار على صور عين حقيقية
قيّم الفريق طريقتهم على 739 صورة شبكية من قاعدة بيانات عامة ومجموعة مستشفى، مع وسم كل صورة بواسطة خبراء الزَرَق. كما تتبَّع الاختصاصيون حدود القرص البصري والحُفرة، متنمين خرائط تفصيلية للهياكل الأكثر أهمية سريريًا. تم تدريب عدة أنظمة مبنية على المحولات من الصفر ومقارنتها: ViT‑B/16 القياسي بالمربعات، وتصميم آخر قائم على السوبر‑بيكسل من عمل سابق، والإصداران من SpxViT. قيس الأداء باستخدام مقاييس تشخيصية شائعة توازن بين قدرة النموذج على كشف العيون المريضة واستبعاد العيون السليمة بشكل صحيح. حقق ViT‑B/16 الكلاسيكي أفضل دقة كلية، لكن SpxViT_var اقترب جدًا منه، بفارق أقل من نقطة مئوية واحدة.
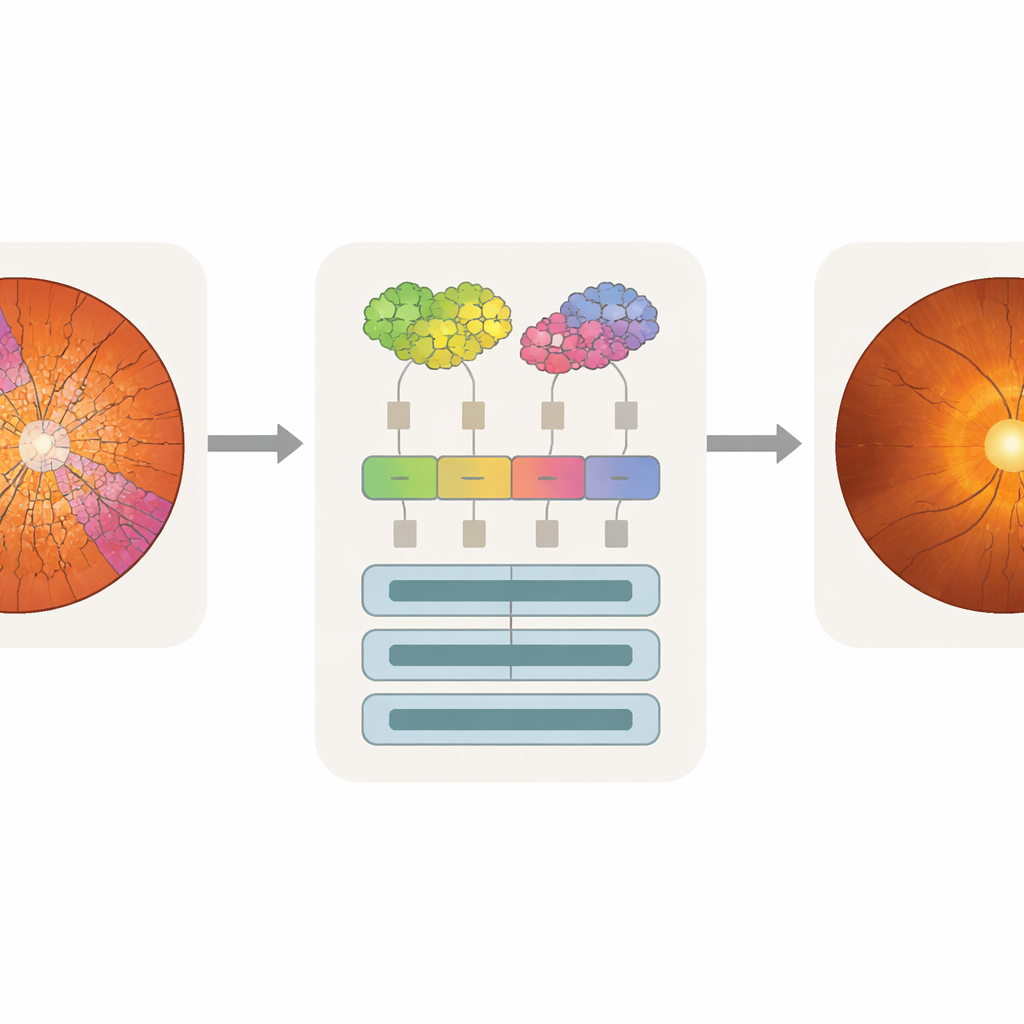
جعل انتباه الآلة يتوافق مع عين الطبيب
الدقة وحدها لا تكفي للاستخدام السريري؛ يحتاج الأطباء أيضًا إلى معرفة أي أجزاء من الصورة أثّرت في قرار النموذج. استخدم الباحثون تقنية تحليل تسمى "تتبُّع الانتباه" (attention rollout)، التي تتتبع مقدار مساهمة كل رمز في التنبؤ النهائي وتحويل ذلك إلى خريطة حرارة فوق الصورة الأصلية. لأن رموز SpxViT تتبع محاذير القرص والحُفرة، فإن خرائط الانتباه الخاصة به تتماشى طبيعيًا مع تلك المناطق وتتجنب النمط الشبكي الكتلي الذي يظهر في المحولات القياسية. عبر تراكب خرائط الحرارة مع تقسيمات الخبراء، استطاع الفريق حساب مقدار الانتباه الموجه نحو الحُفرة أو القرص أو الخلفية. ركزت نماذج السوبر‑بيكسل، وبخاصة SpxViT_var، معظم اهتمامها على القرص والحُفرة بينما تجاهلت بقية الشبكية إلى حد كبير. كما قيّم اختصاصي زَرَق خرائط أمثلة بالعين ووجد أن خرائط SpxViT_fix كانت الأسهل في التفسير، مع إبراز واضح للهياكل المستخدمة في التشخيص الواقعي.
موازنة الثقة والأداء في ذكاء العيون الاصطناعي
تُظهر الدراسة أن إعادة تشكيل طريقة تقسيم الصور إلى أجزاء يمكن أن يجعل أنظمة الذكاء الاصطناعي لفحص الزَرَق أكثر شفافية دون التضحية الجادة بالدقة. بينما يتفوق المحول الكلاسيكي على الطريقة الجديدة من حيث الأرقام الصافية، يقدم SpxViT تفسيرات تتوافق بشكل أفضل مع المنطق السريري من خلال التركيز على القرص والحُفرة بدلًا من أنماط متناثرة أو شبكية. في الممارسة اليومية، قد تكون هذه المقايضة مجدية: فالنموذج الذي يستطيع الأطباء فهمه والتشكيك فيه مرجّح أن يتم تبنيه ودمجه بأمان في برامج الفحص. يجادل المؤلفون بأن تصميمات مشابهة قائمة على السوبر‑بيكسل قد تساعد في تقديم ذكاء اصطناعي قابل للتفسير لمهام تصوير طبية أخرى حيث معرفة المكان الذي ينظر إليه النموذج لا تقل أهمية عن كونه صحيحًا.
الاستشهاد: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
الكلمات المفتاحية: فحص الزَرَق, تصوير الشبكية, محولات الرؤية, الذكاء الاصطناعي القابل للتفسير, السوبر‑بيكسلات