Clear Sky Science · it
Un nuovo Vision Transformer basato su superpixel per migliorare l’interpretabilità nello screening del glaucoma
Perché le scansioni oculari e le macchine intelligenti sono importanti
Il glaucoma è una malattia oculare silenziosa che può sottrarre la vista prima che le persone notino sintomi. I medici possono individuare segnali precoci in fotografie a colori della parte posteriore dell’occhio, ma esaminare attentamente ogni immagine è dispendioso in termini di tempo e richiede competenza. L’intelligenza artificiale (IA) può aiutare, tuttavia molti sistemi potenti si comportano come “scatole nere”, offrendo scarsa chiarezza su come arrivano a una decisione. Questo studio introduce un nuovo approccio di IA che mira a mantenere un’elevata accuratezza rendendo al contempo più comprensibile il processo decisionale per gli specialisti oculari, in modo che possano vederlo e fidarsene.
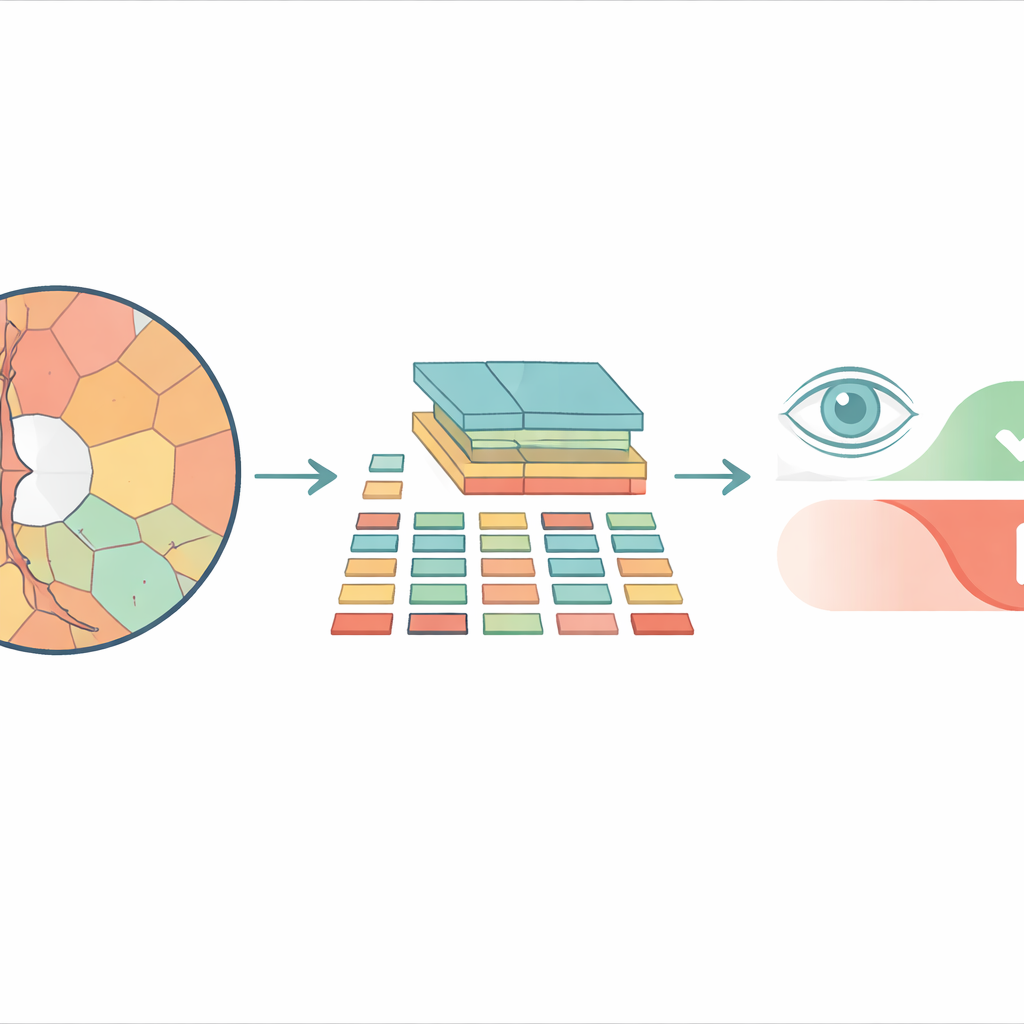
Da tasselli quadrati a regioni più naturali
La maggior parte dei moderni sistemi di analisi delle immagini basati su vision transformer suddivide una foto in una scacchiera di tasselli quadrati identici prima di elaborarla. Questo può funzionare bene per foto quotidiane, ma ignora la forma delle strutture reali nell’occhio. Il disco ottico e la depressione interna chiamata cupola hanno contorni curvi e irregolari, e costringerli in quadrati rigidi mescola insieme dettagli importanti e non importanti. I ricercatori invece utilizzano i “superpixel” — gruppi di pixel vicini con colore o texture simili — per suddividere l’immagine retinica in parti che seguono i confini anatomici reali. Questi superpixel diventano quindi le unità di base, o “token”, che il transformer analizza.
Un nuovo modo di alimentare le immagini nei transformer
Il modello proposto, chiamato Superpixel‑based Vision Transformer (SpxViT), mantiene quasi inalterata la parte interna di un vision transformer standard e si concentra sul ridisegno della fase iniziale. Prima che l’immagine raggiunga il transformer, un algoritmo esistente (SLIC) la divide in 196 superpixel, approssimando il numero di tasselli usati in un modello di riferimento comune chiamato ViT‑B/16. Ogni regione irregolare viene trasformata in una descrizione numerica a lunghezza fissa in modo da poter essere trattata come un normale tassello. Sono testate due varianti: una che usa un’impostazione costante per favorire forme più naturali (SpxViT_fix) e un’altra che adatta questa impostazione per ogni immagine in modo da produrre sempre esattamente 196 regioni (SpxViT_var). A parte questo passaggio di tokenizzazione, gli strati del transformer e la procedura di addestramento sono gli stessi del modello classico, il che consente un confronto equo.
Test su immagini oculari reali
Il team ha valutato il metodo su 739 fotografie retiniche provenienti da un database pubblico e da una raccolta ospedaliera, con ogni immagine etichettata da esperti di glaucoma. Gli specialisti hanno anche tracciato i confini del disco ottico e della cupola, creando mappe dettagliate delle strutture clinicamente più importanti. Sono stati addestrati da zero diversi sistemi basati su transformer e confrontati: il ViT‑B/16 standard con tasselli quadrati, un altro progetto basato su superpixel di lavori precedenti e le due versioni di SpxViT. Le prestazioni sono state misurate con score diagnostici comuni che bilanciano quanto bene un modello rileva occhi malati e scarta correttamente quelli sani. Il ViT‑B/16 classico ha ottenuto la migliore accuratezza complessiva, ma SpxViT_var si è avvicinato molto, con un distacco inferiore a un punto percentuale.
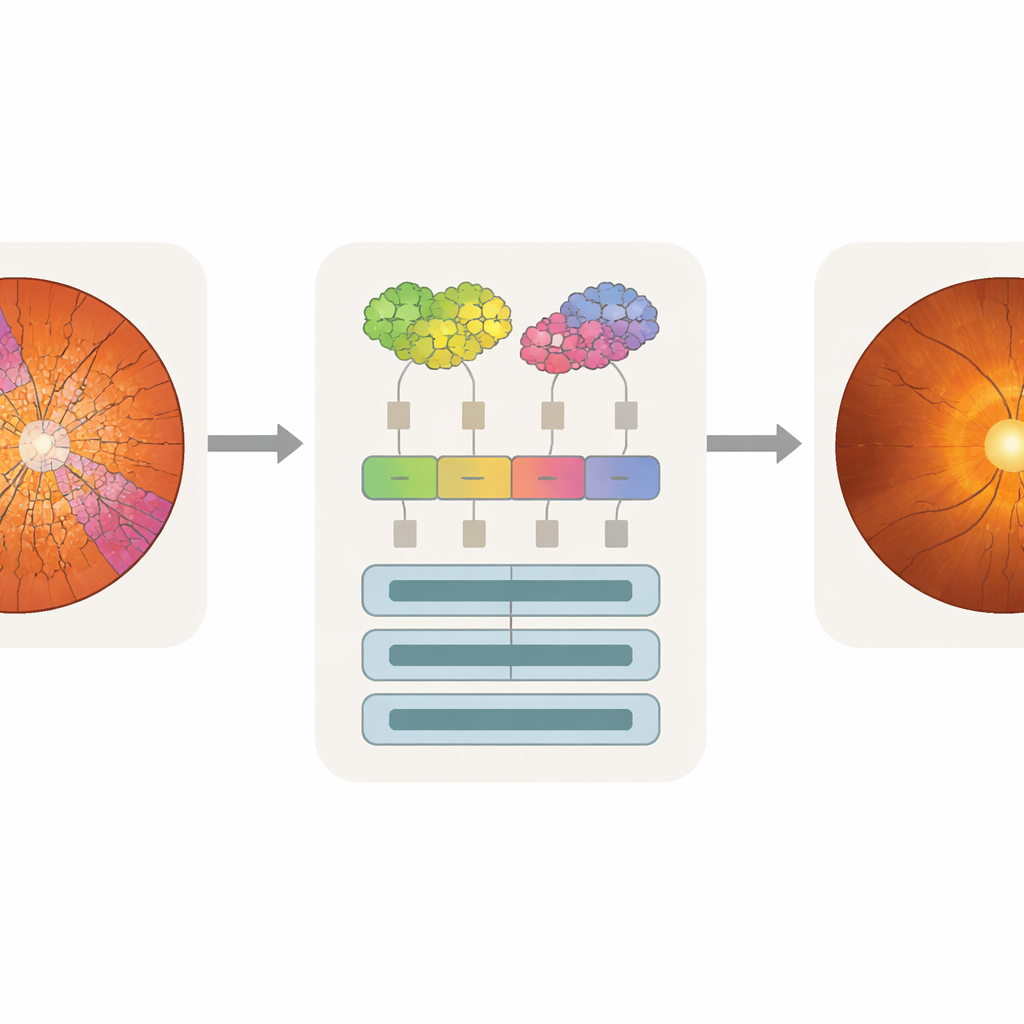
Far corrispondere l’attenzione della macchina allo sguardo del medico
L’accuratezza da sola non basta per l’uso clinico; i medici devono anche sapere quali parti di un’immagine hanno influenzato la decisione di un modello. I ricercatori hanno usato una tecnica di analisi chiamata attention rollout, che traccia quanto ogni token contribuisce alla predizione finale e trasforma questo dato in una heatmap sovrapposta all’immagine originale. Poiché i token di SpxViT seguono i contorni del disco e della cupola, le sue mappe di attenzione si allineano naturalmente con quelle regioni ed evitano il pattern a blocchi visto nei transformer standard. Sovrapponendo le heatmap con le segmentazioni esperte, il team ha potuto calcolare quanta attenzione era rivolta alla cupola, al disco o allo sfondo. I modelli basati su superpixel, in particolare SpxViT_var, hanno concentrato la maggior parte dell’attenzione su disco e cupola ignorando ampiamente il resto della retina. Uno specialista del glaucoma ha inoltre valutato a occhio alcune mappe di esempio e ha trovato quelle prodotte da SpxViT_fix le più facili da interpretare, con evidenziazioni chiare delle strutture utilizzate nella diagnosi reale.
Bilanciare fiducia e prestazioni nell’IA per l’oculistica
Lo studio mostra che rimodellare il modo in cui le immagini vengono suddivise può rendere i sistemi di IA per lo screening del glaucoma più trasparenti senza compromettere gravemente l’accuratezza. Pur avendo il transformer classico un lieve vantaggio nelle metriche numeriche, SpxViT fornisce spiegazioni che corrispondono meglio al ragionamento clinico concentrandosi su disco ottico e cupola invece di pattern sparsi o a griglia. Nella pratica quotidiana questo compromesso può valere la pena: un modello che i medici possono comprendere e interrogare ha più probabilità di essere adottato e integrato in sicurezza nei programmi di screening. Gli autori sostengono che progetti simili basati su superpixel potrebbero contribuire a portare IA interpretabile ad altri compiti di imaging medico in cui sapere dove il modello guarda è importante quanto il fatto che abbia ragione.
Citazione: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
Parole chiave: screening del glaucoma, imaging retinico, vision transformer, IA spiegabile, superpixel