Clear Sky Science · es
Un nuevo Vision Transformer basado en superpíxeles para mejorar la interpretabilidad en el cribado del glaucoma
Por qué importan las exploraciones oculares y las máquinas inteligentes
El glaucoma es una enfermedad ocular silenciosa que puede robar la visión antes de que las personas perciban síntomas. Los médicos pueden detectar señales de alarma tempranas en fotografías en color del fondo del ojo, pero examinar cada imagen con detalle lleva tiempo y exige experiencia. La inteligencia artificial (IA) puede ayudar, sin embargo muchos sistemas potentes actúan como “cajas negras”, ofreciendo poca transparencia sobre cómo llegan a una conclusión. Este estudio presenta un nuevo enfoque de IA que pretende mantener alta precisión al mismo tiempo que hace que su razonamiento sea más fácil de ver y confiar para los especialistas en oftalmología.
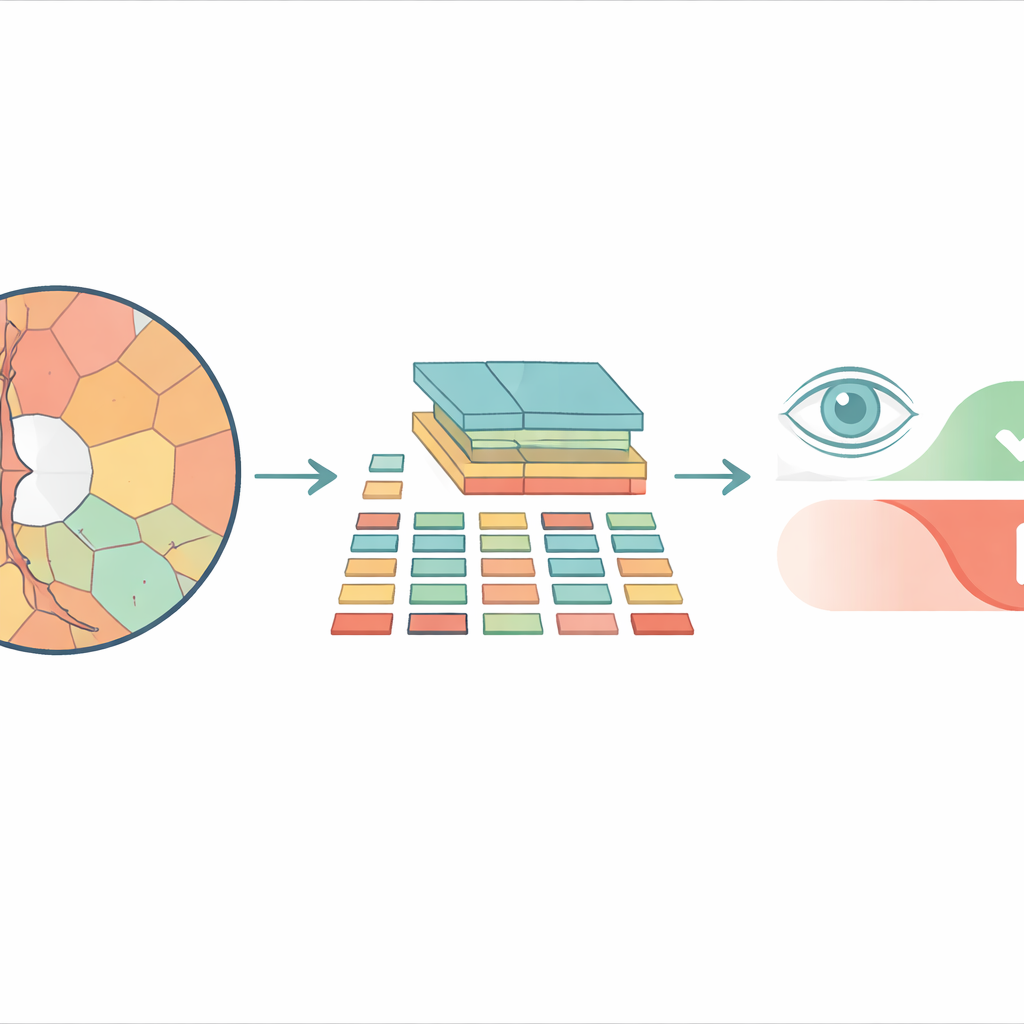
De los mosaicos cuadrados a regiones más naturales
La mayoría de los sistemas modernos de análisis de imágenes basados en vision transformers dividen una imagen en un tablero de fichas cuadradas idénticas antes de procesarla. Eso puede funcionar bien para fotos corrientes, pero ignora cómo se forman realmente las estructuras del ojo. El disco óptico y la depresión interna llamada copa tienen contornos curvos e irregulares, y forzarlos en cuadrados rígidos mezcla detalles importantes con otros irrelevantes. En cambio, los investigadores usan “superpíxeles”: grupos de píxeles vecinos que comparten color o textura similares, para trocear la imagen retinal en piezas que siguen los límites anatómicos reales. Esos superpíxeles se convierten luego en las unidades básicas, o “tokens”, que el transformer analiza.
Una nueva forma de alimentar imágenes a los transformers
El modelo propuesto, llamado Superpixel‑based Vision Transformer (SpxViT), mantiene la mecánica interna de un vision transformer estándar casi sin cambios y se centra en rediseñar la etapa inicial. Antes de que la imagen llegue al transformer, un algoritmo existente (SLIC) la divide en 196 superpíxeles, aproximándose al número de fichas usado en un modelo de referencia común denominado ViT‑B/16. Cada región irregular se convierte en una descripción numérica de longitud fija para que pueda manejarse como una ficha normal. Se prueban dos variantes: una que usa un ajuste constante para favorecer formas más naturales (SpxViT_fix) y otra que ajusta ese parámetro por imagen para producir siempre exactamente 196 regiones (SpxViT_var). Aparte de este paso de tokenización, las capas del transformer y el procedimiento de entrenamiento son los mismos que en el modelo clásico, lo que permite una comparación justa.
Pruebas con imágenes oculares reales
El equipo evaluó su método en 739 fotografías retinianas procedentes de una base de datos pública y de una colección hospitalaria, con cada imagen etiquetada por expertos en glaucoma. Los especialistas también trazaron los límites del disco óptico y de la copa, creando mapas detallados de las estructuras clínicamente más relevantes. Se entrenaron desde cero varios sistemas basados en transformers y se compararon: el ViT‑B/16 estándar con fichas cuadradas, otro diseño basado en superpíxeles de trabajos previos y las dos versiones de SpxViT. El rendimiento se midió con puntuaciones diagnósticas habituales que equilibran la capacidad de detectar ojos enfermos y la de descartar correctamente los sanos. El ViT‑B/16 clásico alcanzó la mejor precisión global, pero SpxViT_var quedó muy cerca, por detrás por menos de un punto porcentual.
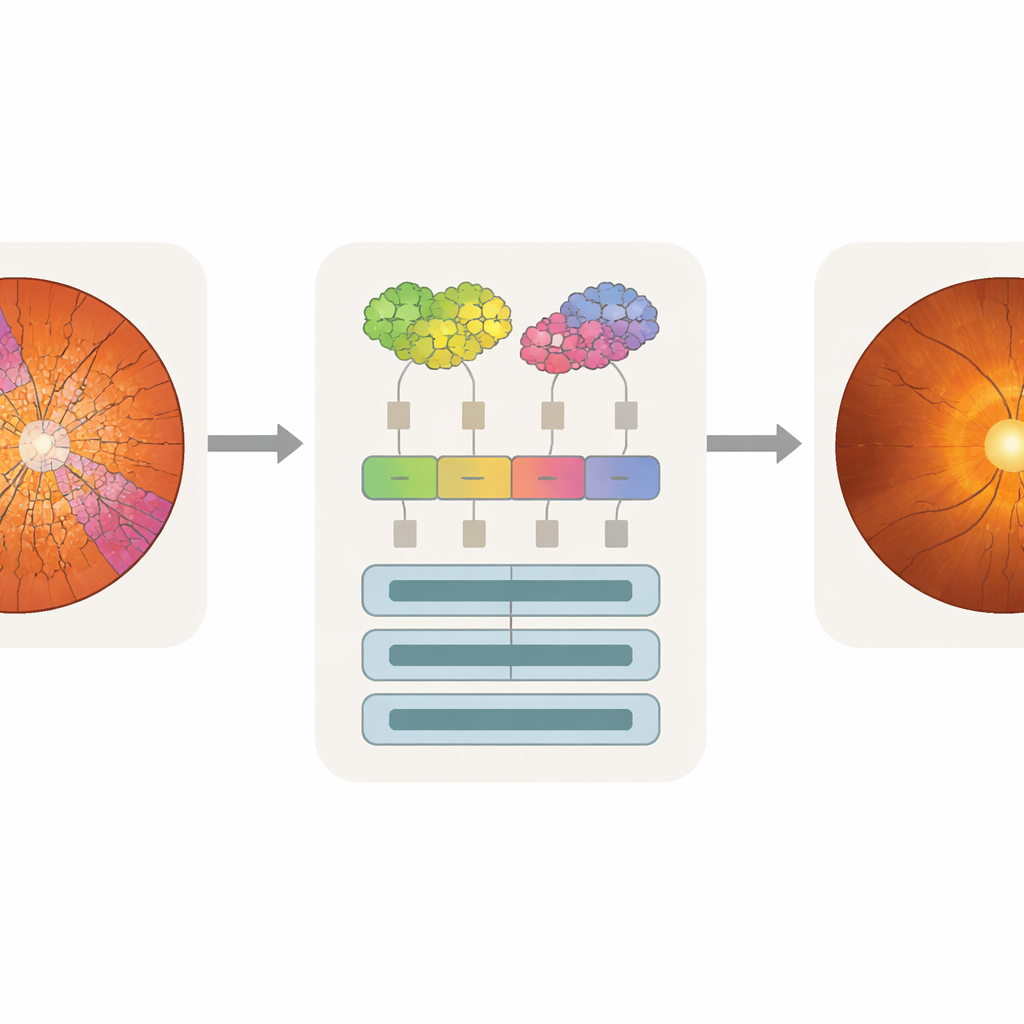
Hacer que la atención de la máquina coincida con la mirada del médico
La precisión por sí sola no es suficiente para el uso clínico; los médicos también necesitan saber qué partes de una imagen influyeron en la decisión de un modelo. Los investigadores emplearon una técnica de análisis llamada attention rollout, que traza cuánto contribuye cada token a la predicción final y lo convierte en un mapa de calor sobre la imagen original. Porque los tokens de SpxViT siguen los contornos del disco y la copa, sus mapas de atención se alinean de forma natural con esas regiones y evitan el patrón cuadriculado visto en transformers estándar. Al superponer los mapas de calor con las segmentaciones de los expertos, el equipo pudo calcular qué proporción de atención recayó en la copa, en el disco o en el fondo. Los modelos basados en superpíxeles, en especial SpxViT_var, concentraron la mayor parte de su atención en el disco y la copa mientras ignoraban en gran medida el resto de la retina. Un especialista en glaucoma también valoró visualmente mapas de ejemplo y encontró que los de SpxViT_fix eran los más fáciles de interpretar, con resaltados claros de las estructuras utilizadas en el diagnóstico real.
Equilibrar confianza y rendimiento en la IA para atención ocular
El estudio muestra que cambiar la forma en que se divide la imagen en piezas puede hacer que los sistemas de IA para el cribado del glaucoma sean más transparentes sin sacrificar de forma significativa la precisión. Si bien el transformer clásico supera al nuevo método en números puros, SpxViT produce explicaciones que se ajustan mejor al razonamiento clínico al centrarse en el disco óptico y la copa en lugar de patrones dispersos o en rejilla. Para la práctica diaria, este compromiso puede valer la pena: un modelo que los médicos puedan entender y cuestionar tiene más probabilidades de ser adoptado e integrado de forma segura en programas de cribado. Los autores sostienen que diseños similares basados en superpíxeles podrían ayudar a llevar IA interpretable a otras tareas de imagen médica donde saber dónde mira el modelo es tan importante como si acierta.
Cita: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
Palabras clave: cribado de glaucoma, imagen retinal, vision transformers, IA explicable, superpíxeles