Clear Sky Science · sv
FaceScanPaliGemma multi-agent vision language models for facial attribute recognition
Varför smartare ansiktsavläsning är viktig
Varje dag fångar kameror otaliga bilder av människor: i inlägg på sociala medier, online-möten och i offentliga miljöer. I bakgrunden försöker datorsystem i allt högre grad "läsa" dessa ansikten och gissa saker som ålder, sinnestillstånd och andra egenskaper. Sådana verktyg kan möjliggöra användbara tjänster, från hjälpmedel för tillgänglighet till hälsoforskning, men de väcker också djupa frågor om rättvisa, integritet och snedvridningar. Denna artikel introducerar FaceScanPaliGemma, ett nytt AI-system utformat inte bara för att förbättra hur datorer tolkar ansikten, utan också för att uppmärksamma vilka som kan bli utestängda eller behandlade orättvist.
En ny team-baserad metod för att läsa ansikten
De flesta tidigare system för ansiktsanalys förlitar sig på en enda, stor modell som försöker göra allt på en gång: upptäcka ras, kön, åldersgrupp och känslouttryck i en bild. FaceScanPaliGemma går en annan väg. Det använder ett "team" av mindre, specialiserade modeller som samarbetar, där varje modell fokuserar på en enda uppgift. Dessa modeller bygger på en vision–språk-arkitektur, vilket innebär att de både kan tolka en bild och bearbeta en skriftlig uppmaning om vad användaren vill veta. Till exempel kan systemet svara på frågor som "Vilken åldersgrupp och vilket känslouttryck har barnet på den här bilden?" genom att kombinera vad det ser med vad som efterfrågas.
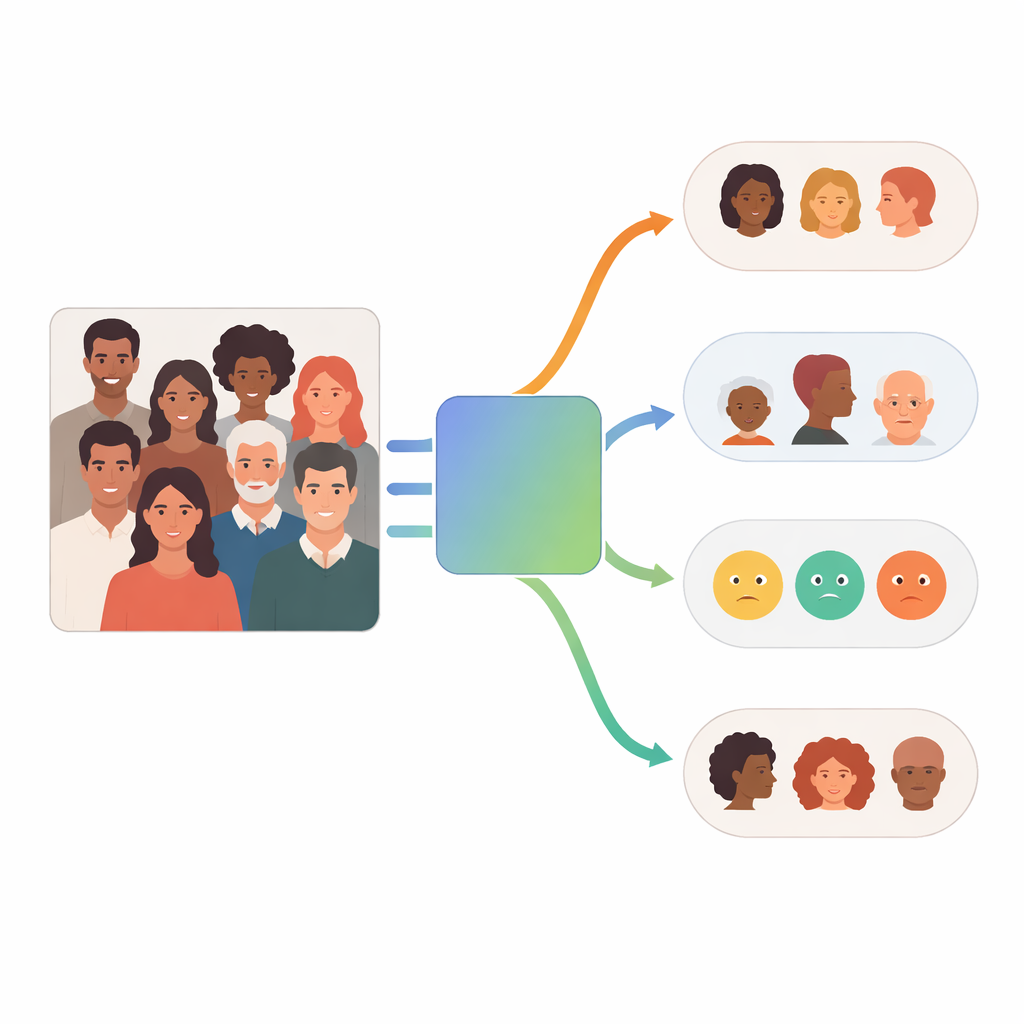
Hur fleragentssystemet fungerar
I centrum för FaceScanPaliGemma finns en analysagent som läser användarens förfrågan och bryter ned den i steg. Om frågan nämner en specifik person i en folkkär scen — till exempel "pojken som håller en boll" eller "den mellanösternkvinna" — anropar analysagenten först en ansiktsdetekteringsmodell för att lokalisera relevanta ansikten. Den skickar sedan dessa beskurna ansikten till en eller flera specialistagenter som är inriktade på ras, kön, åldersgrupp eller känslor. Varje specialist är en finjusterad version av Googles PaliGemma vision–språkmodell, tränad på märkta ansiktsbilder för att bli mycket noggrann på sin specifika uppgift. Analysagenten sammanfogar slutligen delarna till ett svar som följer den ursprungliga förfrågan.
Bygger på större och rättvisare ansiktsdatamängder
För att träna och testa dessa agenter använde forskarna två stora publika dataset. Det första, FairFace, består av mer än hundratusen ansikten noggrant balanserade över flera rasgrupper och inkluderar etiketter för kön och detaljerade åldersintervall. Denna utformning bidrar till att minska det vanliga problemet med att ha betydligt fler exempel av vissa grupper, som vita ansikten, än andra. Det andra datasetet, AffectNet, innehåller hundratusentals bilder taggade med åtta grundläggande ansiktsuttryck, från glädje till förakt, insamlade från webben på flera språk. Genom att finjustera PaliGemma-modellerna på dessa dataset anpassade teamet ett mångsidigt vision–språk-verktyg till fyra fokuserade experter för ras-, köns-, åldersgrupps- och känsloorienterad igenkänning.
Systemets prestation
I omfattande tester jämfördes FaceScanPaliGemma med välkända, allmänna AI-system som GPT-4o och Gemini, samt med traditionella djupinlärningsmodeller baserade enbart på bildbehandling. För rasklassificering nådde det nya systemet cirka 81 % noggrannhet när flera raskategorier grupperades, en tydlig förbättring jämfört med både tidigare visionssystem och färdiga vision–språkmodeller. Det uppnådde cirka 96 % noggrannhet för kön och 80 % för bredare åldersgrupper, vilket återigen matchar eller överstiger starka referensmodeller. Känsloigenkänning visade sig vara svårare: här nådde FaceScanPaliGemma omkring 59 % noggrannhet — bättre än förtränade vision–språkmodeller och vissa klassiska metoder, men fortfarande under de allra bästa känslofokuserade systemen som tränats på miljontals bilder. Författarna undersökte också hur prestationen varierar över olika demografiska grupper och fann små skillnader för kön men större luckor för vissa raser och subtila uttryck, vilket de kopplar till den inneboende svårigheten i att bedöma utseendebaserade egenskaper.
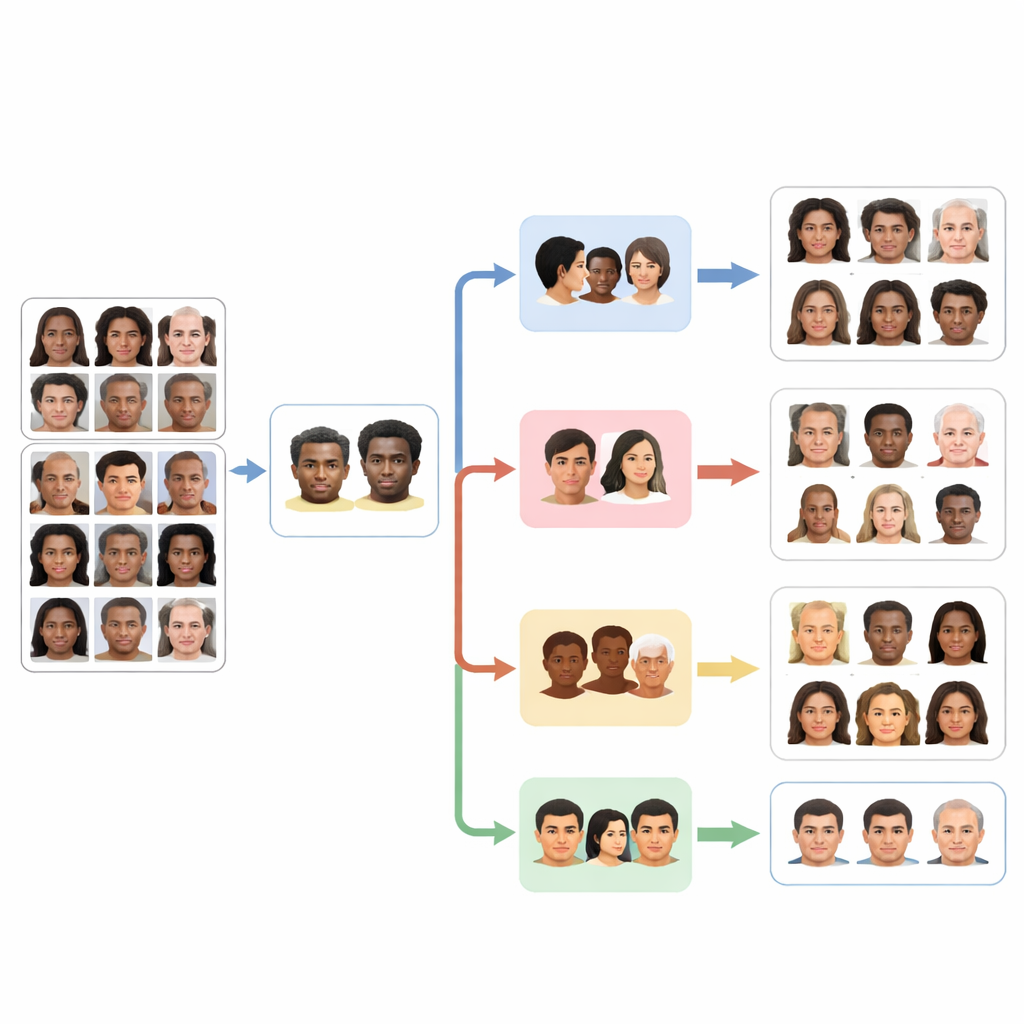
Rättvisa, risker och verklig användning
Då igenkänning av ansiktsattribut rör identitet, integritet och diskriminering ägnar författarna särskild uppmärksamhet åt etik. De poängterar att FaceScanPaliGemma tränades på offentliga forskningsdataset och att modellerna släpps med tydlig vägledning mot missbruk i områden som massövervakning eller automatiserat beslutsfattande. Fleragentdesignen bidrar också: genom att separera ras, kön, ålder och känslor i skilda moduler blir det lättare att mäta och minska bias i varje enskild del. Systemet har ändå begränsningar. Det har främst testats på benchmarks snarare än röriga verkliga bilder, och det förklarar ännu inte hur det når sina beslut — två viktiga områden för framtida arbete.
Vad detta arbete betyder framöver
Med enkla ord visar denna studie att ett koordinerat team av mindre, specialiserade AI-modeller kan läsa ansikten mer noggrant och flexibelt än många större, enstaka modeller, särskilt när de styrs av noggrant utvalda träningsdata. FaceScanPaliGemma är snabbare och billigare att köra än många jättemodeller, och samtidigt kan det mäta sig med eller överträffa dem i flera centrala uppgifter. Samtidigt understryker forskningen att tolkning av mänskliga egenskaper från ansikten förblir osäker och etiskt problematisk, särskilt för känslor och för visuellt otydliga grupper. Författarna hävdar att framtida framsteg bör förena tekniska förbättringar — som bättre träningsdata och stegvis inlärning — med starkare skydd för rättvisa, integritet och transparens innan sådana system används i stor skala.
Citering: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
Nyckelord: igenkänning av ansiktsattribut, vision–språkmodeller, fleragent-AI, FairFace-datasetet, igenkänning av känslor