Clear Sky Science · ja
顔属性認識のためのFaceScanPaliGemma:マルチエージェント視覚言語モデル
なぜより賢い顔認識が重要なのか
日々、カメラはソーシャルメディアの投稿、オンライン会議、公共空間などで無数の人の画像を記録しています。コンピュータシステムはますますこれらの顔を「読む」ことを試み、年齢や気分、その他の特徴を推定します。こうしたツールはアクセシビリティ支援や健康研究など有用なサービスを支える一方で、公平性、プライバシー、バイアスといった重大な問題も提起します。本論文はFaceScanPaliGemmaという新しいAIシステムを紹介します。これはコンピュータによる顔の読み取りを改善するだけでなく、誰が不利になる可能性があるかにも注意を払う設計を目指しています。
顔認識における新しいチーム型アプローチ
従来の多くの顔解析システムは、単一の大規模モデルが人種、性別、年齢層、感情などを一度に推定する方式でした。FaceScanPaliGemmaは別の道を取ります。複数の小さな専門モデルの「チーム」を使い、それぞれが単一のタスクに専念して協調します。これらのモデルは視覚–言語(ビジョン・ランゲージ)設計に基づいており、画像を解析すると同時に、ユーザーが求める情報を記述したテキストプロンプトを処理できます。たとえば「この写真の子どもの年齢層と感情は?」といった質問に対して、視覚情報と問いを組み合わせて答えることが可能です。
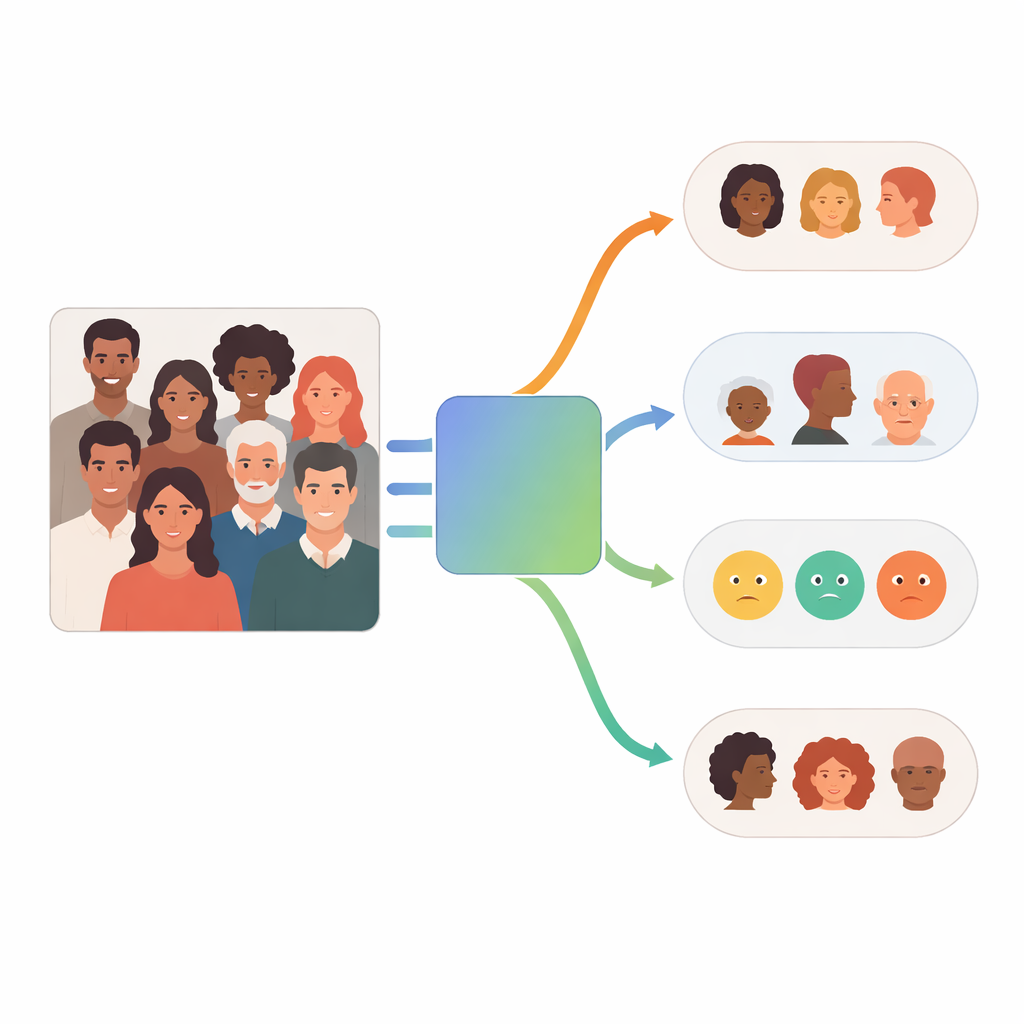
マルチエージェントシステムの仕組み
FaceScanPaliGemmaの中心には、ユーザーの要求を読み取りそれを段階に分解する分析エージェントがあります。たとえば「ボールを持っている少年」や「中東出身の女性」のように混雑した場面で特定の人物を指す問いがある場合、分析エージェントはまず顔検出モデルを呼び出して該当する顔を見つけます。次にその切り出した顔を、人種、性別、年齢層、感情にそれぞれ特化した専門エージェントに渡します。各専門エージェントはGoogleのPaliGemma視覚–言語モデルを微調整したもので、ラベル付けされた顔画像で単一タスクに対して高精度になるよう訓練されています。最後に分析エージェントが各出力を組み合わせて、元の要求に沿った回答を生成します。
より公平で大規模な顔データセットを基盤に
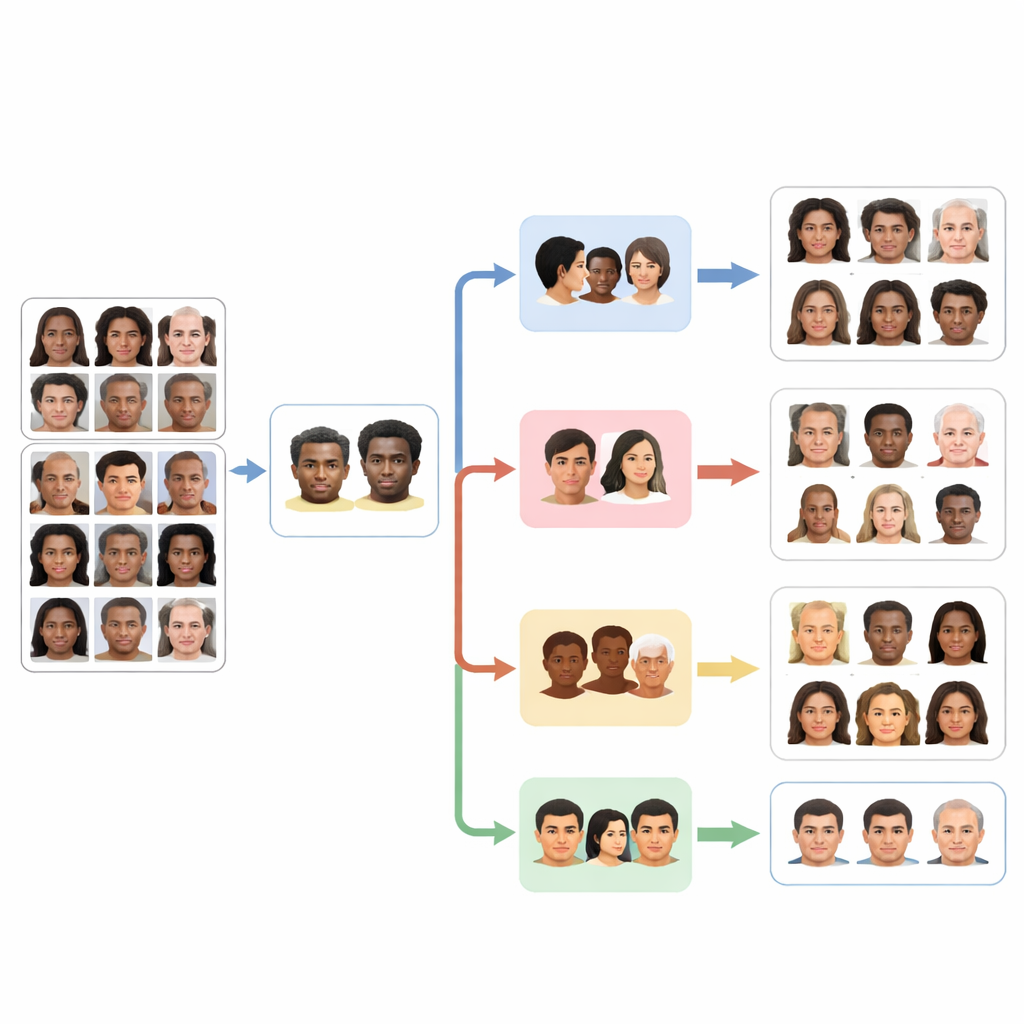
これらのエージェントを訓練・評価するために、研究者たちは二つの主要な公開データセットを利用しました。第一にFairFaceは、複数の人種グループにわたって慎重にバランスされた10万件を超える顔画像を含み、性別と詳細な年齢範囲のラベルも備えています。この設計は白人顔など一部のグループのサンプルが過剰になる一般的な問題を軽減します。第二のデータセットAffectNetは、幸福や軽蔑など八つの基本的な表情でラベル付けされた数十万の画像を多言語のウェブから収集したものです。PaliGemmaモデルをこれらのデータセットで微調整することで、研究チームは人種、性別、年齢層、感情認識の四つの専門家モデルへと汎用の視覚–言語ツールを適応させました。
システムの性能
大規模な評価で、FaceScanPaliGemmaはGPT-4oやGeminiといった著名な汎用AIシステム、および画像処理に基づく従来の深層学習モデルと比較されました。人種認識では、複数の人種カテゴリをまとめた場合に約81%の精度を達成し、従来の視覚システムや既製の視覚–言語モデルを明確に上回りました。性別は約96%、広い年齢層では約80%の精度を示し、いずれも強力なベースラインに匹敵または上回りました。感情認識はより困難で、FaceScanPaliGemmaは約59%の精度に留まりました。これは事前学習された視覚–言語モデルや一部の従来手法より良好ですが、数百万枚の画像で訓練された最高峰の感情特化システムには及びません。研究者らは異なる人口統計群間での性能差も検討し、性別では小さな差が見られた一方、特定の人種や微妙な表情ではより大きな差があり、これは外見に基づく判定の本質的な難しさに起因するとしています。
公平性、リスク、実運用上の課題
顔属性認識は身元、プライバシー、差別に関わるため、著者らは倫理面に特に配慮しています。FaceScanPaliGemmaは公開研究用データセットで訓練されており、モデルの悪用(大規模監視や自動意思決定など)を避けるための明確な使用上の注意が添えられていることを強調しています。マルチエージェント設計も有益であり、人種、性別、年齢、感情を別々のモジュールに分離することで、それぞれのバイアスを個別に測定・軽減しやすくなります。それでも限界は残ります。主にベンチマークデータでの評価に留まり、雑多な実世界の画像での検証が十分ではないこと、また判断過程を説明する機能がまだ整っていないことは、今後の重要な課題です。
今後への示唆
要するに、この研究は、小さく専門化されたAIモデルのチームが、適切に選ばれた学習データに導かれることで、多くの大規模単一モデルよりも正確かつ柔軟に顔を読み取れることを示しています。FaceScanPaliGemmaは多くの巨大モデルに比べて処理が速くコストも低く、それでいていくつかの主要タスクでそれらに匹敵または凌駕します。同時に、人の特徴を顔から読み取ることは依然として不確実で倫理的に問題が多く、特に感情や視覚的にあいまいな集団に対しては慎重さが求められます。著者らは、より良い訓練データや段階的学習などの技術的進展と、公平性、プライバシー、透明性を強化する制度的な保護を組み合わせることが、こうしたシステムを広く展開する前に必要だと述べています。
引用: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
キーワード: 顔属性認識, 視覚言語モデル, マルチエージェントAI, FairFaceデータセット, 感情認識