Clear Sky Science · fr
FaceScanPaliGemma modèles vision-langage multi-agents pour la reconnaissance d’attributs faciaux
Pourquoi mieux décrypter les visages importe
Chaque jour, des caméras saisissent d’innombrables images de personnes : sur les réseaux sociaux, lors de réunions en ligne et dans les espaces publics. Dans les coulisses, des systèmes informatiques tentent de plus en plus de « lire » ces visages, en estimant par exemple l’âge, l’humeur ou d’autres traits. De tels outils peuvent servir des usages utiles, des aides à l’accessibilité à la recherche en santé, mais soulèvent aussi des questions profondes de justice, de vie privée et de biais. Cet article présente FaceScanPaliGemma, un nouveau système d’IA conçu non seulement pour améliorer la lecture automatique des visages, mais aussi pour accorder plus d’attention à qui pourrait être exclu ou traité de manière injuste.
Une nouvelle approche en équipe pour analyser les visages
La plupart des systèmes d’analyse faciale précédents reposent sur un modèle unique et volumineux qui tente de tout faire : détecter la race, le genre, la tranche d’âge et l’émotion sur une image. FaceScanPaliGemma emprunte une autre voie. Il utilise une « équipe » de modèles plus petits et spécialisés qui coopèrent, chacun se concentrant sur une tâche précise. Ces modèles sont basés sur une architecture vision–langage, ce qui signifie qu’ils peuvent à la fois analyser une image et traiter une consigne textuelle sur ce que l’utilisateur souhaite savoir. Par exemple, le système peut répondre à des questions comme « Quel est le groupe d’âge et l’émotion de l’enfant sur cette photo ? » en combinant ce qu’il voit avec ce qu’on lui demande.
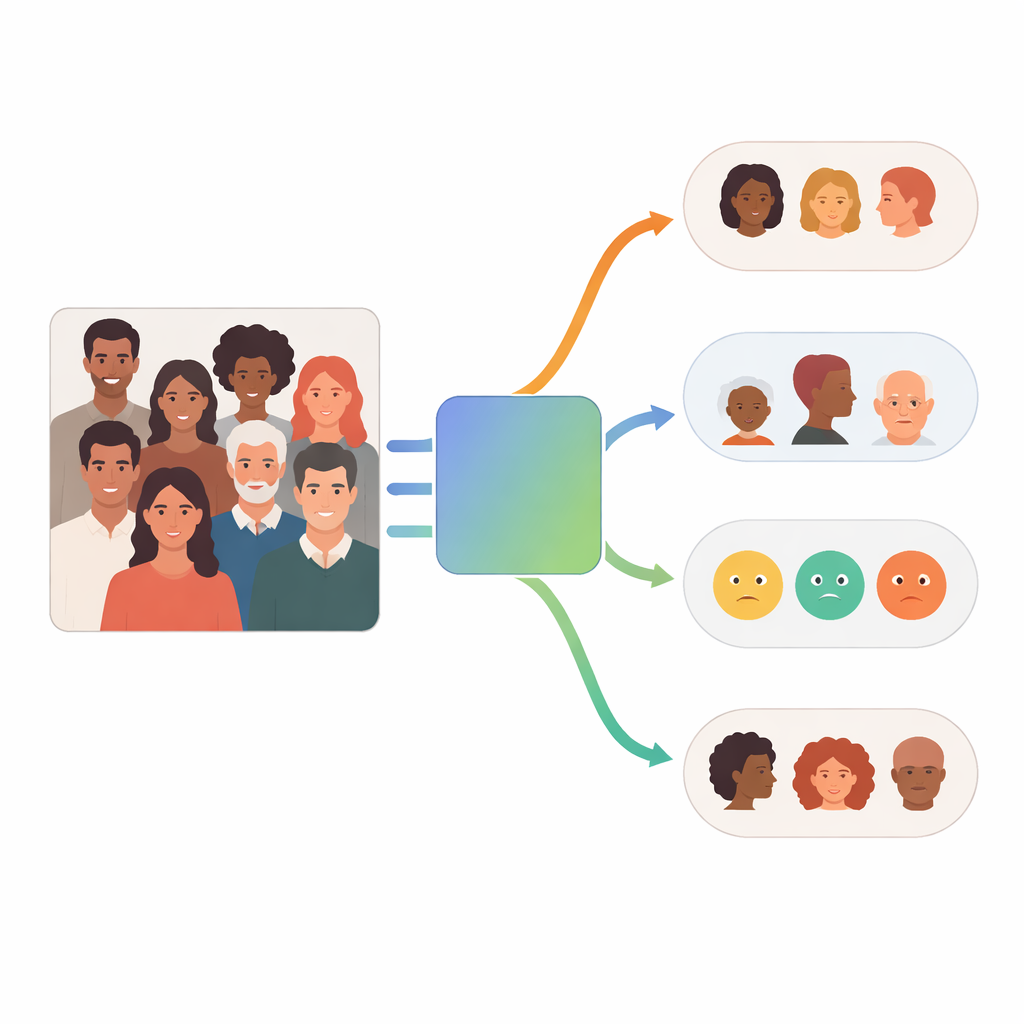
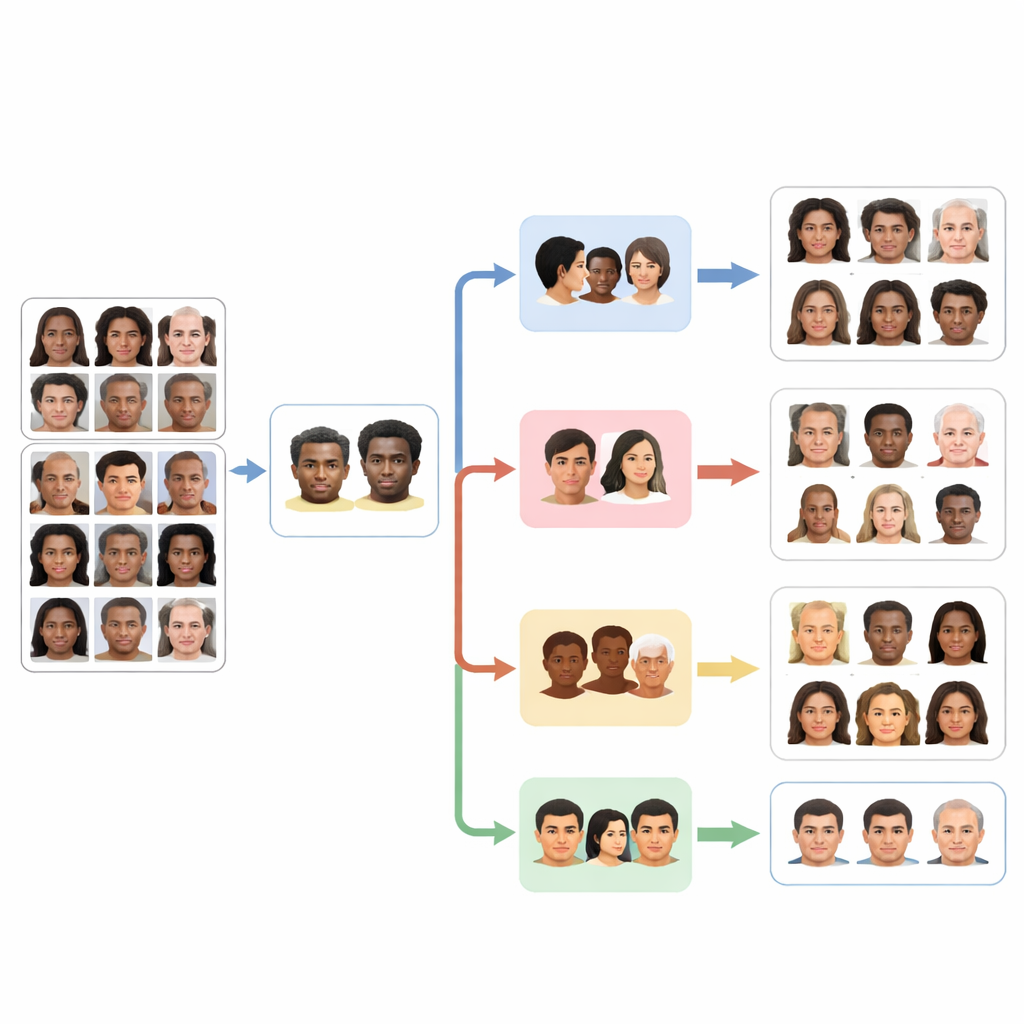
Comment fonctionne le système multi-agent
Au cœur de FaceScanPaliGemma se trouve un agent d’analyse qui lit la demande de l’utilisateur et la décompose en étapes. Si la requête mentionne une personne précise dans une scène animée — par exemple « le garçon tenant un ballon » ou « la femme d’origine moyen-orientale » — l’agent d’analyse fait d’abord appel à un modèle de détection de visages pour localiser les visages pertinents. Il transmet ensuite ces visages recadrés à un ou plusieurs agents spécialistes dédiés à la race, au genre, au groupe d’âge ou à l’émotion. Chaque spécialiste est une version fine-tunée du modèle vision–langage PaliGemma de Google, entraînée sur des images faciales annotées pour devenir très performante sur sa tâche unique. L’agent d’analyse combine enfin les éléments en une réponse conforme à la demande initiale.
S’appuyer sur des ensembles de données faciales plus grands et plus équitables
Pour entraîner et évaluer ces agents, les chercheurs se sont appuyés sur deux grands ensembles de données publics. Le premier, FairFace, comprend plus de cent mille visages soigneusement équilibrés entre plusieurs groupes raciaux et incluant des étiquettes pour le genre et des tranches d’âge détaillées. Cette conception aide à réduire le problème courant des déséquilibres, où certaines catégories, comme les visages blancs, sont surreprésentées. Le second ensemble, AffectNet, contient des centaines de milliers d’images étiquetées selon huit expressions faciales de base, de la joie au mépris, collectées sur le web en plusieurs langues. En fine-tunant les modèles PaliGemma sur ces jeux de données, l’équipe a adapté un outil vision–langage généraliste en quatre experts ciblés pour la reconnaissance de la race, du genre, du groupe d’âge et des émotions.
Performance du système
Lors d’essais complets, FaceScanPaliGemma a été comparé à des systèmes d’IA généralistes bien connus comme GPT-4o et Gemini, ainsi qu’à des modèles de deep learning traditionnels basés uniquement sur le traitement d’image. Pour la reconnaissance de la race, le nouveau système a atteint environ 81 % de précision en groupant plusieurs catégories raciales, un gain net par rapport aux systèmes de vision antérieurs et aux modèles vision–langage prêts à l’emploi. Il a obtenu environ 96 % de précision pour le genre, et 80 % pour des tranches d’âge larges, égalant ou dépassant de solides références. La reconnaissance des émotions s’est révélée plus difficile : là, FaceScanPaliGemma a atteint environ 59 % de précision — mieux que les modèles vision–langage pré-entraînés et certaines méthodes classiques, mais encore en deçà des meilleurs systèmes spécialisés sur les émotions entraînés sur des millions d’images. Les auteurs ont aussi examiné la variation des performances selon les groupes démographiques et ont constaté de petits écarts pour le genre mais des écarts plus marqués pour certaines races et pour des expressions subtiles, qu’ils rapprochent de la difficulté intrinsèque à juger des traits basés sur l’apparence.
Équité, risques et usages réels
Parce que la reconnaissance d’attributs faciaux touche à l’identité, à la vie privée et à la discrimination, les auteurs accordent une attention particulière à l’éthique. Ils soulignent que FaceScanPaliGemma a été entraîné sur des ensembles de données de recherche publics et que les modèles sont publiés avec des recommandations claires contre les usages abusifs, comme la surveillance de masse ou la prise de décision automatisée. Le design multi-agent aide aussi : en séparant race, genre, âge et émotion en modules distincts, il devient plus facile de mesurer et de réduire le biais dans chacun d’eux indépendamment. Néanmoins, le système a ses limites. Il a été testé principalement sur des jeux de données de référence plutôt que sur des images réelles et désordonnées, et il n’explique pas encore comment il parvient à ses décisions — deux axes importants pour des travaux futurs.
Ce que ce travail annonce pour la suite
En termes simples, cette étude montre qu’une équipe coordonnée de modèles d’IA plus petits et spécialisés peut lire les visages avec plus de précision et de souplesse que beaucoup de systèmes monolithiques plus grands, en particulier lorsqu’elle est guidée par des données d’entraînement soigneusement choisies. FaceScanPaliGemma est plus rapide et moins coûteux à exécuter que bien des modèles géants, tout en rivalisant ou en les surpassant sur plusieurs tâches clés. Dans le même temps, la recherche souligne que l’interprétation des traits humains à partir des visages reste incertaine et éthiquement délicate, notamment pour les émotions et pour des groupes visuellement ambigus. Les auteurs plaident pour que les progrès futurs associent des avancées techniques — meilleures données d’entraînement et apprentissage par étapes — à des garanties renforcées en matière d’équité, de confidentialité et de transparence avant un déploiement à grande échelle de tels systèmes.
Citation: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
Mots-clés: reconnaissance d’attributs faciaux, modèles vision-langage, IA multi-agent, ensemble de données FairFace, reconnaissance des émotions