Clear Sky Science · es
FaceScanPaliGemma modelos de visión y lenguaje multiagente para el reconocimiento de atributos faciales
Por qué importa leer rostros de forma más inteligente
Cada día, cámaras capturan innumerables imágenes de personas: en publicaciones de redes sociales, reuniones en línea y espacios públicos. Detrás de escena, los sistemas informáticos intentan cada vez más «leer» estos rostros, adivinando cosas como la edad, el estado de ánimo y otros rasgos. Estas herramientas pueden impulsar servicios útiles, desde ayudas de accesibilidad hasta investigación en salud, pero también plantean preguntas profundas sobre equidad, privacidad y sesgos. Este artículo presenta FaceScanPaliGemma, un nuevo sistema de IA diseñado no solo para mejorar la lectura facial por parte de las máquinas, sino también para prestar mayor atención a quién podría quedar excluido o ser tratado de forma injusta.
Un nuevo enfoque en equipo para leer rostros
La mayoría de los sistemas de análisis facial anteriores confían en un único modelo grande que intenta hacerlo todo a la vez: detectar raza, género, grupo de edad y emoción a partir de una imagen. FaceScanPaliGemma sigue una ruta diferente. Usa un «equipo» de modelos más pequeños y especializados que trabajan juntos, cada uno centrado en una única tarea. Estos modelos se basan en un diseño visión–lenguaje, lo que significa que pueden mirar una imagen y también procesar un texto con lo que el usuario quiere saber. Por ejemplo, el sistema puede responder preguntas como «¿Cuál es el grupo de edad y la emoción del niño en esta fotografía?» combinando lo que ve con lo que se le pregunta.
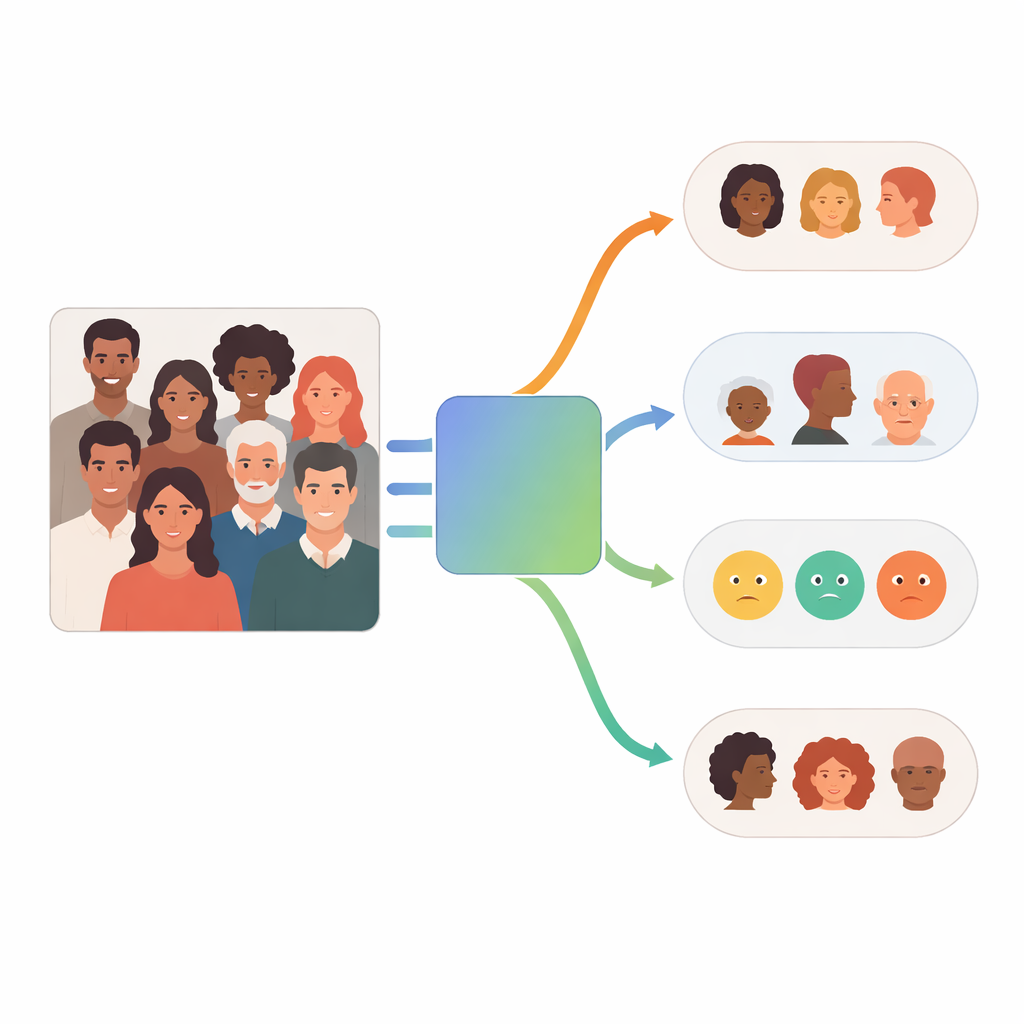
Cómo funciona el sistema multiagente
En el núcleo de FaceScanPaliGemma hay un agente de análisis que lee la petición del usuario y la descompone en pasos. Si la consulta menciona a una persona concreta en una escena concurrida —por ejemplo, «el niño que sostiene una pelota» o «la mujer de Oriente Medio»— el agente de análisis primero recurre a un modelo de detección de rostros para localizar las caras relevantes. A continuación, envía esos rostros recortados a uno o varios agentes especialistas dedicados a raza, género, grupo de edad o emoción. Cada especialista es una versión afinada del modelo visión–lenguaje PaliGemma de Google, entrenada con imágenes faciales etiquetadas para volverse muy precisa en su tarea única. El agente de análisis combina finalmente las piezas en una respuesta que sigue la solicitud original.
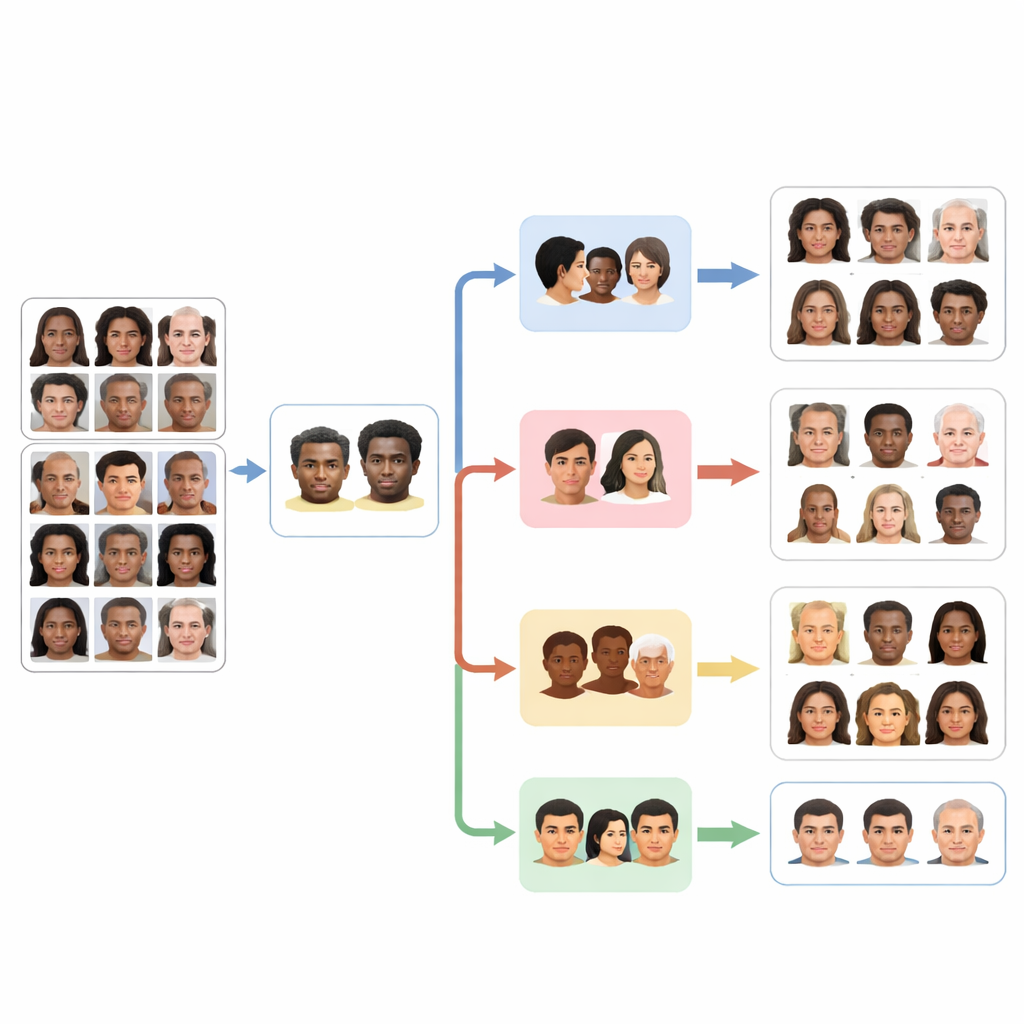
Construido sobre conjuntos de datos faciales más grandes y equitativos
Para entrenar y evaluar a estos agentes, los investigadores se apoyaron en dos conjuntos de datos públicos principales. El primero, FairFace, consta de más de cien mil rostros cuidadosamente equilibrados entre varios grupos raciales e incluye etiquetas para género y rangos de edad detallados. Este diseño ayuda a reducir el problema común de tener muchos más ejemplos de ciertos grupos, como rostros blancos, que de otros. El segundo conjunto, AffectNet, contiene cientos de miles de imágenes etiquetadas con ocho expresiones faciales básicas, desde la felicidad hasta el desprecio, recopiladas en la web en varios idiomas. Afinando los modelos PaliGemma con estos conjuntos de datos, el equipo adaptó una herramienta visión–lenguaje de propósito general en cuatro expertos centrados en reconocimiento de raza, género, grupo de edad y emoción.
Qué tan bien funciona el sistema
En pruebas extensas, FaceScanPaliGemma se comparó con sistemas de IA de propósito general bien conocidos, como GPT-4o y Gemini, así como con modelos tradicionales de aprendizaje profundo basados únicamente en procesamiento de imagen. Para el reconocimiento de raza, el nuevo sistema alcanzó alrededor del 81 % de precisión al agrupar varias categorías raciales, una mejora clara respecto a sistemas de visión anteriores y a modelos visión–lenguaje listos para usar. Logró aproximadamente un 96 % de precisión en género y un 80 % en grupos de edad amplios, igualando o superando sólidas referencias. El reconocimiento de emociones resultó más difícil: aquí, FaceScanPaliGemma alcanzó cerca del 59 % de precisión —mejor que modelos visión–lenguaje preentrenados y algunos métodos clásicos, pero aún por debajo de los mejores sistemas centrados en emociones entrenados con millones de imágenes. Los autores también examinaron cómo varía el rendimiento entre distintos grupos demográficos y hallaron brechas pequeñas en género pero mayores en ciertas razas y expresiones sutiles, que relacionan con la dificultad intrínseca de juzgar rasgos basados en la apariencia.
Equidad, riesgos y uso en el mundo real
Puesto que el reconocimiento de atributos faciales toca identidad, privacidad y discriminación, los autores dedican atención especial a la ética. Enfatizan que FaceScanPaliGemma se entrenó con conjuntos de datos públicos de investigación y que los modelos se publican con orientaciones claras contra su uso indebido en áreas como la vigilancia masiva o la toma automática de decisiones. El diseño multiagente también ayuda: al separar raza, género, edad y emoción en módulos distintos, resulta más fácil medir y reducir el sesgo en cada uno por separado. Aun así, el sistema tiene límites. Se ha probado mayormente en conjuntos de referencia más que en imágenes desordenadas del mundo real, y aún no explica cómo llega a sus decisiones —dos frentes importantes para trabajo futuro.
Qué significa este trabajo de cara al futuro
En términos sencillos, este estudio muestra que un equipo coordinado de modelos de IA más pequeños y especializados puede leer rostros con mayor precisión y flexibilidad que muchos sistemas grandes de modelo único, especialmente cuando se guía con datos de entrenamiento cuidadosamente elegidos. FaceScanPaliGemma es más rápido y barato de ejecutar que muchos modelos gigantes, y aun así los iguala o supera en varias tareas clave. Al mismo tiempo, la investigación subraya que leer rasgos humanos a partir de rostros sigue siendo incierto y éticamente problemático, especialmente para las emociones y para grupos visualmente ambiguos. Los autores sostienen que los avances futuros deberían combinar mejoras técnicas —como mejores datos de entrenamiento y aprendizaje por etapas— con salvaguardas más fuertes sobre equidad, privacidad y transparencia antes de que tales sistemas se desplieguen de forma amplia.
Cita: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
Palabras clave: reconocimiento de atributos faciales, modelos de visión y lenguaje, IA multiagente, conjunto de datos FairFace, reconocimiento de emociones