Clear Sky Science · pl
FaceScanPaliGemma wieloagentowe modele wizja-język do rozpoznawania cech twarzy
Dlaczego inteligentniejsze czytanie twarzy ma znaczenie
Codziennie kamery rejestrują niezliczone obrazy ludzi: w postach w mediach społecznościowych, podczas spotkań online i w przestrzeni publicznej. W tle systemy komputerowe coraz częściej próbują „czytać” te twarze, zgadując takie cechy jak wiek, nastrój czy inne właściwości. Narzędzia te mogą napędzać użyteczne usługi — od udogodnień dostępnościowych po badania zdrowotne — ale jednocześnie rodzą poważne pytania o uczciwość, prywatność i uprzedzenia. W artykule przedstawiono FaceScanPaliGemma, nowy system AI zaprojektowany nie tylko w celu poprawy sposobu, w jaki komputery analizują twarze, lecz także z większą dbałością o to, kto może zostać pominięty lub potraktowany niesprawiedliwie.
Nowe, zespołowe podejście do czytania twarzy
Większość dotychczasowych systemów analizy twarzy opiera się na jednym, dużym modelu próbującym robić wszystko naraz: wykrywać rasę, płeć, grupę wiekową i emocję na obrazie. FaceScanPaliGemma wybiera inną drogę. Wykorzystuje „zespół” mniejszych, wyspecjalizowanych modeli, które współpracują, z których każdy koncentruje się na jednym zadaniu. Modele te zbudowano w architekturze wizja–język, co oznacza, że potrafią analizować obraz oraz przetwarzać pisemne polecenie o tym, czego użytkownik chce się dowiedzieć. Na przykład system może odpowiedzieć na pytanie „Jaka jest grupa wiekowa i emocja dziecka na tym zdjęciu?”, łącząc to, co widzi, z tym, o co zostanie zapytany.
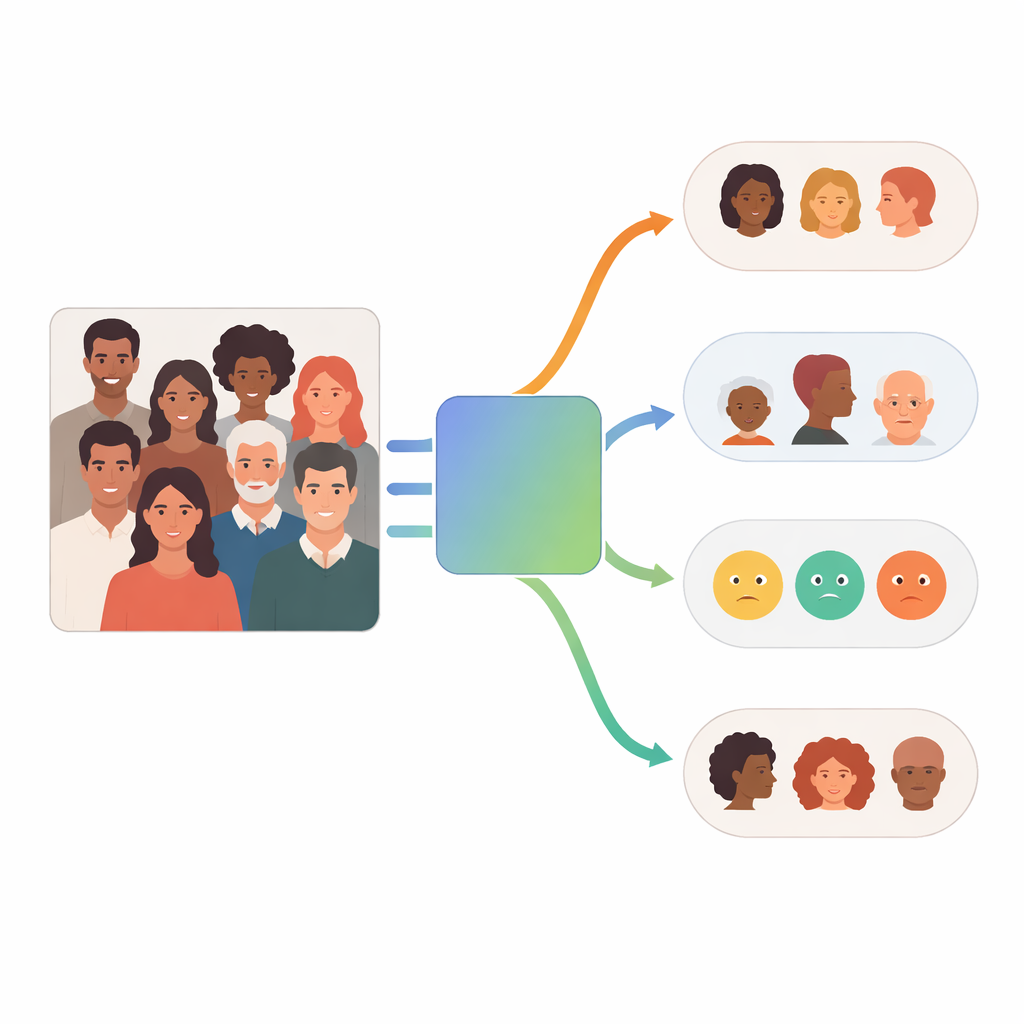
Jak działa system wieloagentowy
W centrum FaceScanPaliGemma stoi agent analityczny, który czyta żądanie użytkownika i rozbija je na kroki. Jeśli zapytanie odnosi się do konkretnej osoby w zatłoczonej scenie — na przykład „chłopiec trzymający piłkę” lub „kobieta z Bliskiego Wschodu” — agent analityczny najpierw odwołuje się do modelu wykrywania twarzy, aby zlokalizować odpowiednie twarze. Następnie przekazuje przycięte obszary twarzy do jednego lub więcej agentów specjalistów poświęconych rasie, płci, grupie wiekowej lub emocji. Każdy specjalista to dostrojona wersja modelu PaliGemma wizja–język firmy Google, wytrenowana na oznakowanych obrazach twarzy, aby osiągnąć wysoką dokładność w swoim pojedynczym zadaniu. Agent analityczny ostatecznie łączy wyniki w odpowiedź zgodną z pierwotnym żądaniem.
Budowanie na sprawiedliwszych i większych zbiorach twarzy
Aby trenować i testować tych agentów, badacze wykorzystali dwa główne publiczne zbiory danych. Pierwszy, FairFace, składa się z ponad stu tysięcy twarzy starannie zrównoważonych w kilku grupach rasowych i zawierających etykiety płci oraz szczegółowe przedziały wiekowe. Taka konstrukcja pomaga ograniczyć powszechny problem znacznej przewagi przykładów pewnych grup, na przykład twarzy białych, nad innymi. Drugi zbiór, AffectNet, zawiera setki tysięcy obrazów oznaczonych ośmioma podstawowymi wyrazami twarzy, od radości po pogardę, zebranych z sieci w wielu językach. Poprzez dostrojenie modeli PaliGemma na tych zbiorach, zespół zaadaptował narzędzie ogólnego przeznaczenia wizja–język w cztery wyspecjalizowane eksperckie modele do rozpoznawania rasy, płci, grupy wiekowej i emocji.
Jak dobrze działa system
W rozległych testach FaceScanPaliGemma porównano z dobrze znanymi, ogólnego przeznaczenia systemami AI, takimi jak GPT-4o i Gemini, a także z tradycyjnymi modelami głębokiego uczenia opartymi wyłącznie na analizie obrazów. W rozpoznawaniu rasy nowy system osiągnął około 81% dokładności przy grupowaniu kilku kategorii rasowych, co stanowi wyraźny wzrost w porównaniu zarówno z wcześniejszymi systemami wizji, jak i z modelami wizja–język typu off-the-shelf. Uzyskał około 96% dokładności dla płci oraz 80% dla szerszych grup wiekowych, ponownie równając lub przewyższając silne punkty odniesienia. Rozpoznawanie emocji okazało się trudniejsze: FaceScanPaliGemma osiągnął tu około 59% dokładności — lepiej niż wstępnie wytrenowane modele wizja–język i niektóre klasyczne metody, ale wciąż poniżej najlepszych systemów skoncentrowanych na emocjach wytrenowanych na milionach obrazów. Autorzy przeanalizowali także, jak wydajność różni się w zależności od grup demograficznych i znaleźli niewielkie luki w przypadku płci, ale większe dla niektórych ras i subtelnych wyrazów, które wiążą z wrodzoną trudnością oceny cech opartych na wyglądzie.
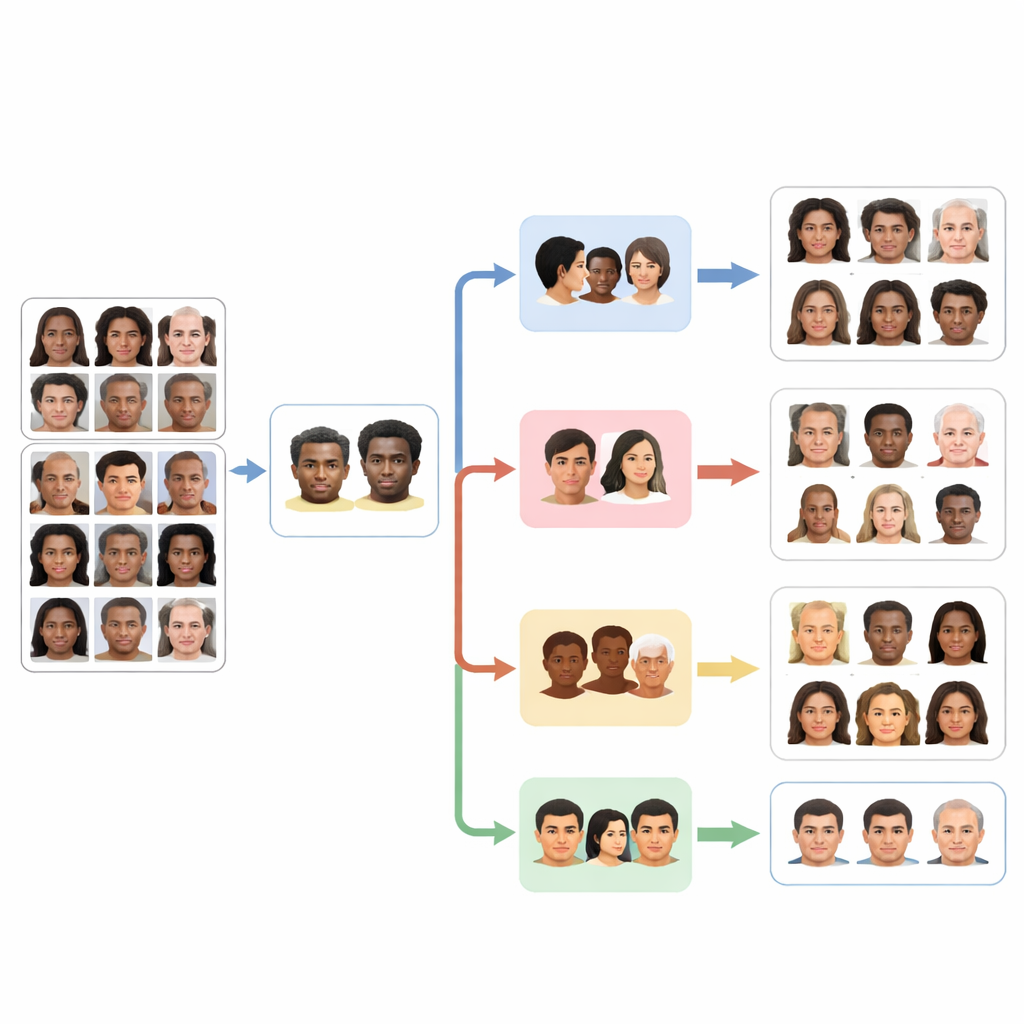
Sprawiedliwość, ryzyka i zastosowania w świecie rzeczywistym
Ponieważ rozpoznawanie cech twarzy dotyka tożsamości, prywatności i dyskryminacji, autorzy poświęcają temu szczególną uwagę etyczną. Podkreślają, że FaceScanPaliGemma był trenowany na publicznych zbiorach badawczych oraz że modele są udostępniane z jasnymi wskazówkami zapobiegającymi nadużyciom w obszarach takich jak masowy nadzór czy zautomatyzowane podejmowanie decyzji. Projekt wieloagentowy też pomaga: przez oddzielenie rasy, płci, wieku i emocji w odrębne moduły łatwiej jest mierzyć i redukować uprzedzenia w każdym z nich niezależnie. System ma jednak ograniczenia. Testowano go głównie na zbiorach referencyjnych, a nie na chaotycznych obrazach z rzeczywistości, i nie wyjaśnia jeszcze, jak dochodzi do swoich decyzji — oba te obszary są ważnymi kierunkami przyszłej pracy.
Co oznacza ta praca na przyszłość
Mówiąc prosto, badanie pokazuje, że skoordynowany zespół mniejszych, wyspecjalizowanych modeli AI może czytać twarze dokładniej i elastyczniej niż wiele większych, jednorodnych systemów, zwłaszcza gdy kieruje je starannie dobrany zestaw danych treningowych. FaceScanPaliGemma jest szybszy i tańszy w uruchomieniu niż wiele olbrzymich modeli, a mimo to rywalizuje z nimi lub je przewyższa w kilku kluczowych zadaniach. Jednocześnie badania podkreślają, że odczytywanie cech ludzkich z twarzy pozostaje niepewne i obarczone dylematami etycznymi, szczególnie w przypadku emocji i grup wizualnie niejednoznacznych. Autorzy argumentują, że przyszły postęp powinien łączyć postępy techniczne — takie jak lepsze dane treningowe i uczenie etapowe — z silniejszymi zabezpieczeniami w obszarach uczciwości, prywatności i przejrzystości, zanim takie systemy zostaną szeroko wdrożone.
Cytowanie: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
Słowa kluczowe: rozpoznawanie cech twarzy, modele wizja-język, wieloagentowa sztuczna inteligencja, zbiór danych FairFace, rozpoznawanie emocji