Clear Sky Science · de
FaceScanPaliGemma Multi-Agent-Visions‑Sprachmodelle zur Erkennung von Gesichtsmerkmalen
Warum klügeres Gesichtslesen wichtig ist
Tagtäglich erfassen Kameras unzählige Bilder von Menschen: in sozialen Medien, Online‑Meetings und öffentlichen Räumen. Hinter den Kulissen versuchen Computersysteme zunehmend, diese Gesichter „zu lesen“ und Dinge wie Alter, Stimmung oder andere Eigenschaften zu schätzen. Solche Werkzeuge können nützliche Dienste ermöglichen, von Barrierefreiheitsfunktionen bis hin zur Gesundheitsforschung, werfen aber zugleich tiefgehende Fragen zu Fairness, Privatsphäre und Verzerrungen auf. Dieses Papier stellt FaceScanPaliGemma vor, ein neues KI‑System, das nicht nur die Computerauslese von Gesichtern verbessern soll, sondern auch stärker darauf achtet, wer womöglich ausgeschlossen oder unfair behandelt wird.
Ein neuer, teamorientierter Ansatz zum Gesichtslesen
Die meisten bisherigen Gesichtsanalyse‑Systeme beruhen auf einem einzigen, großen Modell, das versucht, alles auf einmal zu leisten: Rasse, Geschlecht, Altersgruppe und Emotionen aus einem Bild zu erkennen. FaceScanPaliGemma wählt einen anderen Weg. Es nutzt ein „Team“ aus kleineren, spezialisierten Modellen, die zusammenarbeiten und sich jeweils nur auf eine Aufgabe konzentrieren. Diese Modelle basieren auf einem Vision‑Language‑Design, das heißt, sie können ein Bild betrachten und zugleich eine schriftliche Anfrage verarbeiten, die angibt, was der Nutzer wissen möchte. So kann das System etwa Fragen beantworten wie „Welche Altersgruppe und Stimmung hat das Kind auf diesem Foto?“, indem es visuelle Eindrücke mit der gestellten Frage kombiniert.
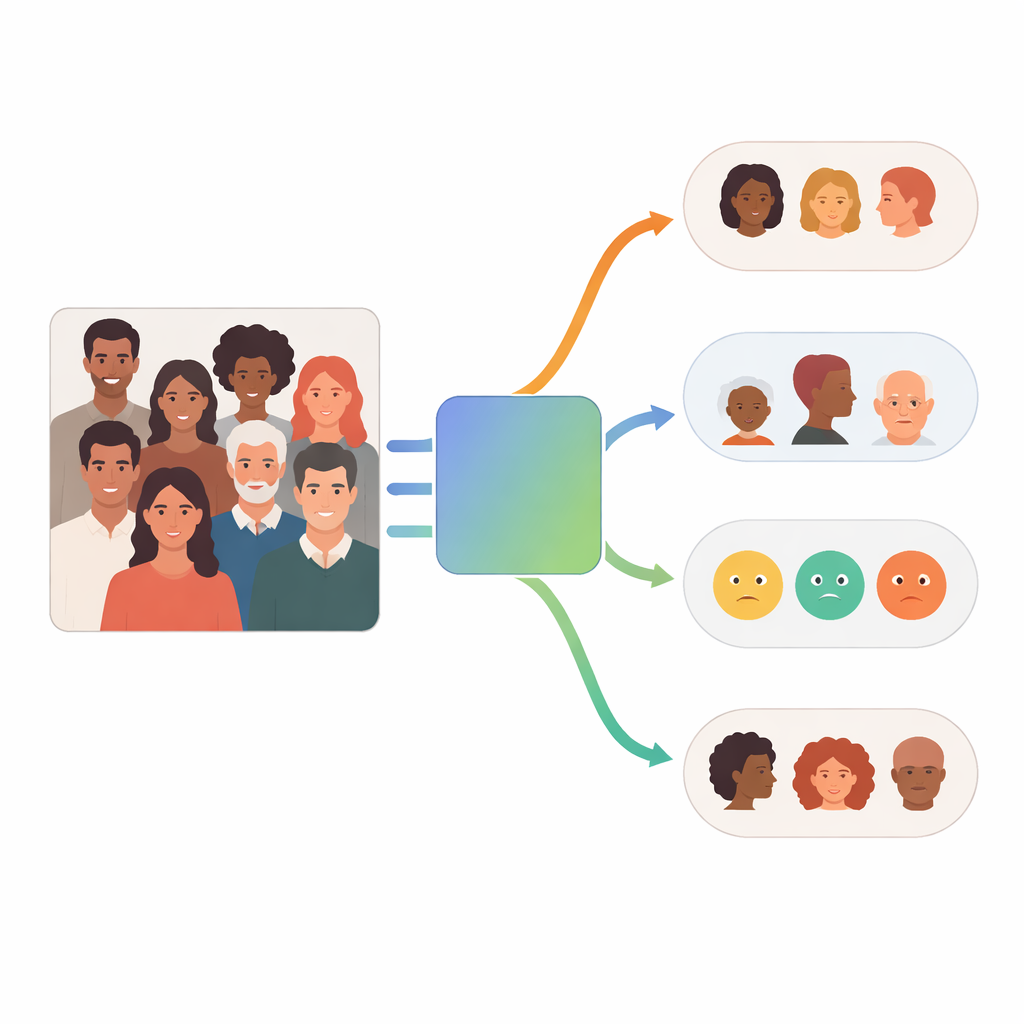
Wie das Multi‑Agenten‑System funktioniert
Im Kern von FaceScanPaliGemma steht ein Analyseagent, der die Nutzeranfrage liest und in Teilschritte zerlegt. Wenn die Anfrage eine bestimmte Person in einer geschäftigen Szene erwähnt – zum Beispiel „der Junge, der einen Ball hält“ oder „die Frau aus dem Nahen Osten“ – ruft der Analyseagent zunächst ein Gesichtserkennungsmodell auf, um die relevanten Gesichter zu lokalisieren. Er schickt dann diese zugeschnittenen Gesichter an einen oder mehrere Spezialagenten, die jeweils für Rasse, Geschlecht, Altersgruppe oder Emotion zuständig sind. Jeder Spezialagent ist eine feinabgestimmte Version von Googles PaliGemma Vision‑Language‑Modell, das an beschrifteten Gesichtsabbildungen trainiert wurde, um in seiner Einzelaufgabe besonders genau zu werden. Abschließend kombiniert der Analyseagent die Ergebnisse zu einer Antwort, die der ursprünglichen Anfrage entspricht.
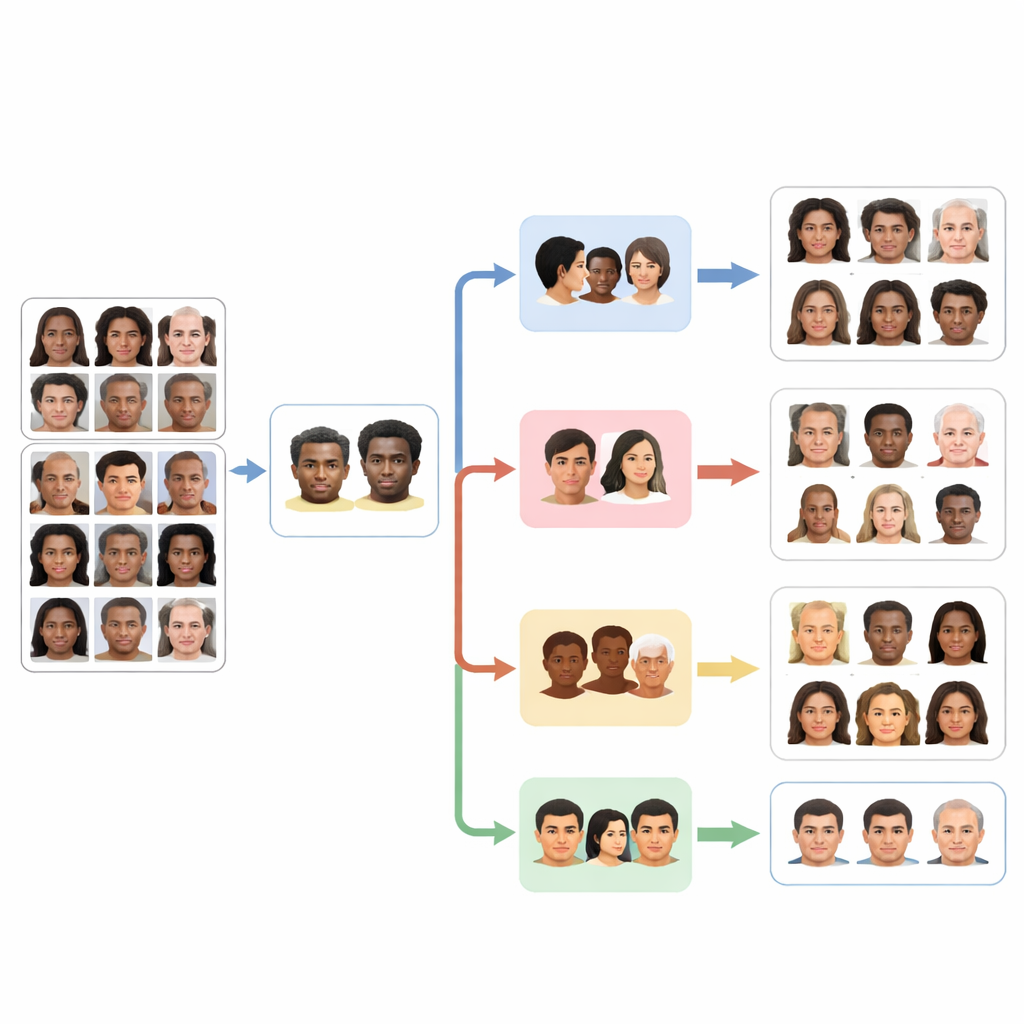
Aufbau mit faireren und größeren Gesichtsdaten
Zum Trainieren und Testen dieser Agenten nutzten die Forschenden zwei große öffentliche Datensätze. Der erste, FairFace, umfasst mehr als hunderttausend Gesichter, sorgfältig ausbalanciert über mehrere Rassengruppen und mit Labels für Geschlecht sowie detaillierte Altersbereiche. Dieses Design hilft, das häufige Problem zu verringern, dass bestimmte Gruppen – etwa weiße Gesichter – deutlich stärker vertreten sind als andere. Der zweite Datensatz, AffectNet, enthält mehrere hunderttausend Bilder, die mit acht grundlegenden Gesichtsausdrücken von Freude bis Verachtung beschriftet sind und aus dem Web in mehreren Sprachen gesammelt wurden. Durch das Fine‑Tuning von PaliGemma‑Modellen an diesen Datensätzen wandelte das Team ein allgemeines Vision‑Language‑Werkzeug in vier fokussierte Expert:innen für Rasse, Geschlecht, Altersgruppe und Emotionserkennung um.
Wie gut das System abschneidet
In umfangreichen Tests wurde FaceScanPaliGemma mit bekannten, allgemeinen KI‑Systemen wie GPT‑4o und Gemini sowie mit traditionellen Deep‑Learning‑Modellen, die nur Bildverarbeitung nutzen, verglichen. Bei der Rassenerkennung erreichte das neue System etwa 81 % Genauigkeit, wenn mehrere Rassenkategorien zusammengefasst wurden – ein deutlicher Gewinn gegenüber früheren Visionsystemen und handelsüblichen Vision‑Language‑Modellen. Für Geschlecht erzielte es rund 96 % Genauigkeit und etwa 80 % für breitere Altersgruppen, womit es starke Baselines erreichte oder übertraf. Die Emotionserkennung erwies sich als schwieriger: Hier kam FaceScanPaliGemma auf etwa 59 % Genauigkeit – besser als vortrainierte Vision‑Language‑Modelle und einige klassische Verfahren, aber noch unterhalb der besten auf Millionen Bildern trainierten emotionsspezifischen Systeme. Die Autor:innen untersuchten außerdem, wie die Leistung zwischen verschiedenen demografischen Gruppen variiert, und fanden kleine Lücken bei Geschlecht, aber größere Unterschiede bei bestimmten Rassen und subtilen Ausdrücken, die sie auf die inhärente Schwierigkeit zurückführen, erscheinungsbasierte Merkmale zu beurteilen.
Fairness, Risiken und praktischer Einsatz
Da die Erkennung von Gesichtsmerkmalen Identität, Privatsphäre und Diskriminierung berührt, widmen die Autor:innen der Ethik besondere Aufmerksamkeit. Sie betonen, dass FaceScanPaliGemma auf öffentlichen Forschungsdatensätzen trainiert wurde und die Modelle mit klaren Hinweisen gegen Missbrauch in Bereichen wie Massenüberwachung oder automatisierter Entscheidungsfindung veröffentlicht werden. Das Multi‑Agenten‑Design hilft ebenfalls: Indem Rasse, Geschlecht, Alter und Emotion in getrennte Module ausgelagert werden, lässt sich Verzerrung in jedem Modul einzeln messen und reduzieren. Gleichwohl hat das System Grenzen. Es wurde hauptsächlich an Benchmark‑Datensätzen getestet statt an unordentlichen Real‑World‑Bildern, und es erklärt noch nicht, wie es zu seinen Entscheidungen kommt – beides wichtige Aufgaben für zukünftige Arbeit.
Was diese Arbeit für die Zukunft bedeutet
Kurz gesagt zeigt diese Studie, dass ein koordiniertes Team kleinerer, spezialisierter KI‑Modelle Gesichter genauer und flexibler lesen kann als viele größere Einzelmodell‑Systeme, insbesondere wenn das Training überlegt ausgewählt wird. FaceScanPaliGemma ist schneller und kostengünstiger im Betrieb als viele Riesenmodelle und kann dennoch in mehreren Schlüsselfeldern mit ihnen konkurrieren oder sie übertreffen. Zugleich unterstreicht die Forschung, dass das Ableiten menschlicher Merkmale aus Gesichtern unsicher und ethisch problematisch bleibt, besonders bei Emotionen und visuell schwer einzuordnenden Gruppen. Die Autor:innen argumentieren, dass künftiger Fortschritt technische Verbesserungen – wie bessere Trainingsdaten und gestuftes Lernen – mit stärkeren Schutzmaßnahmen für Fairness, Privatsphäre und Transparenz verbinden sollte, bevor solche Systeme weit verbreitet eingesetzt werden.
Zitation: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
Schlüsselwörter: Erkennung von Gesichtsmerkmalen, Visions‑Sprachmodelle, Multi‑Agenten‑KI, FairFace‑Datensatz, Emotionserkennung