Clear Sky Science · nl
FaceScanPaliGemma multi-agent visuele taalmodellen voor herkenning van gelaatskenmerken
Waarom slimmer gezichtslezen ertoe doet
Elke dag leggen camera’s talloze beelden van mensen vast: in berichten op sociale media, online vergaderingen en openbare ruimtes. Achter de schermen proberen computers steeds vaker deze gezichten te "lezen" en te raden zoals leeftijd, gemoedstoestand en andere kenmerken. Dergelijke hulpmiddelen kunnen nuttige diensten aandrijven, van toegankelijkheidsfuncties tot gezondheidsonderzoek, maar roepen ook fundamentele vragen op over eerlijkheid, privacy en vooroordelen. Dit artikel introduceert FaceScanPaliGemma, een nieuw AI-systeem dat niet alleen probeert te verbeteren hoe computers gezichten lezen, maar ook meer aandacht besteedt aan wie mogelijk wordt buitengesloten of oneerlijk behandeld.
Een nieuwe teamgebaseerde aanpak voor gezichtslezing
De meeste eerdere gezichtsanalyse-systemen vertrouwen op één groot model dat alles tegelijk probeert te doen: ras, geslacht, leeftijdsgroep en emotie detecteren uit een afbeelding. FaceScanPaliGemma kiest een andere route. Het gebruikt een "team" van kleinere, gespecialiseerde modellen die samenwerken, waarbij elk model zich op één taak richt. Deze modellen zijn opgebouwd volgens een visie–taalontwerp, wat betekent dat ze een afbeelding kunnen bekijken en ook een geschreven prompt kunnen verwerken over wat de gebruiker wil weten. Zo kan het systeem vragen beantwoorden zoals "Wat is de leeftijdsgroep en de emotie van het kind op deze foto?" door te combineren wat het ziet met wat er gevraagd wordt.
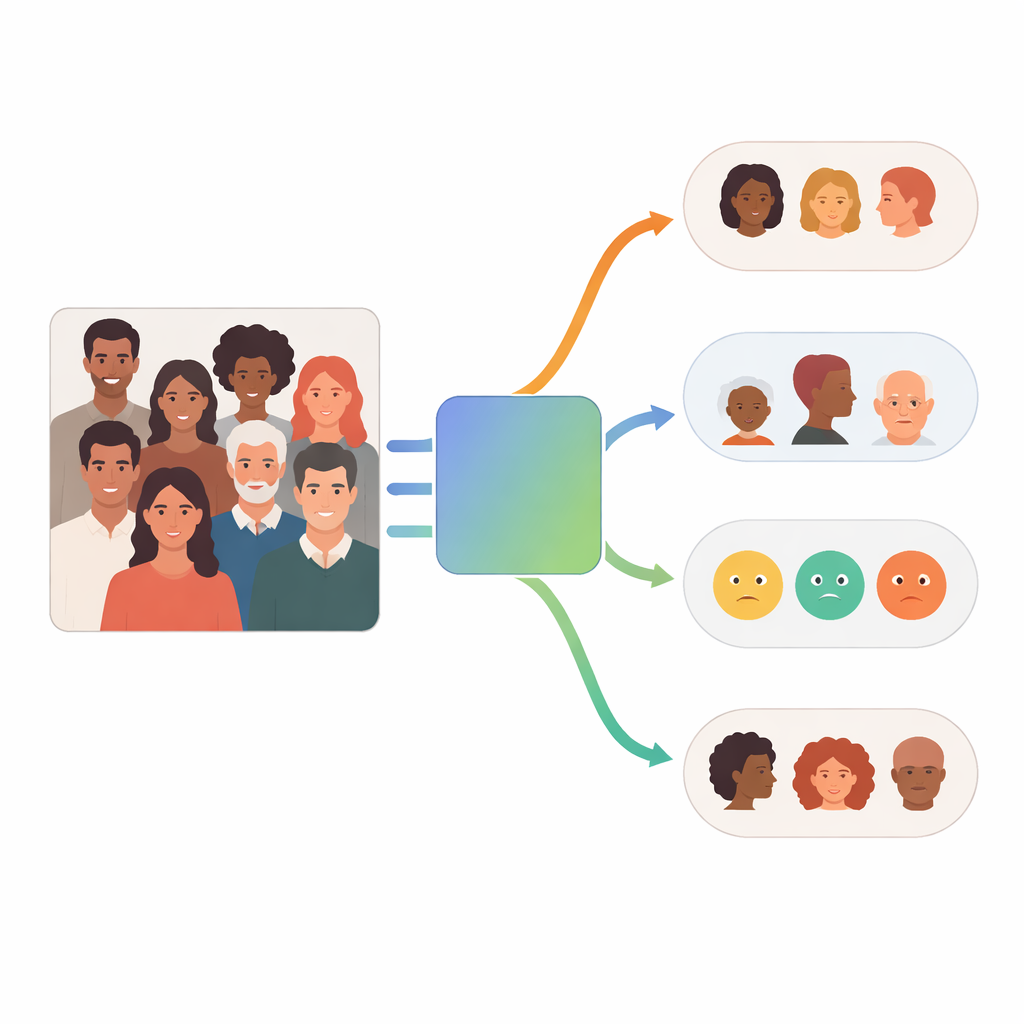
Hoe het multi-agent-systeem werkt
Centraal in FaceScanPaliGemma staat een analyse-agent die de gebruikersvraag leest en opsplitst in stappen. Als de vraag naar een specifieke persoon in een drukke scène verwijst—for example, "de jongen die een bal vasthoudt" of "de Midden-Oosterse vrouw"—roept de analyse-agent eerst een gezicht-detectiemodel op om de relevante gezichten te lokaliseren. Vervolgens stuurt hij die uitgesneden gezichten door naar één of meerdere specialist-agents die gewijd zijn aan ras, geslacht, leeftijdsgroep of emotie. Elke specialist is een fijn-afgestemde versie van Google’s PaliGemma visie–taalmodel, getraind op gelabelde gezichtsfoto’s om zeer nauwkeurig te worden in zijn enkele taak. De analyse-agent combineert uiteindelijk de onderdelen tot een antwoord dat aansluit bij het oorspronkelijke verzoek.
Bouwen op eerlijkere en grotere face-datasets
Om deze agents te trainen en te testen, vertrouwden de onderzoekers op twee belangrijke openbare datasets. De eerste, FairFace, bestaat uit meer dan honderdduizend gezichten die zorgvuldig gebalanceerd zijn over verschillende raciale groepen en labels bevatten voor geslacht en gedetailleerde leeftijdsintervallen. Dit ontwerp helpt het veelvoorkomende probleem te verminderen dat sommige groepen—zoals witte gezichten—veel vaker voorkomen dan andere. De tweede dataset, AffectNet, bevat honderden duizenden afbeeldingen getagd met acht basale gelaatsuitdrukkingen, van blijdschap tot minachting, verzameld van het web in meerdere talen. Door PaliGemma-modellen op deze datasets fijn af te stemmen, paste het team een algemeen visie–taalhulpmiddel aan tot vier gerichte experts voor ras-, geslachts-, leeftijdsgroep- en emotieherkenning.
Hoe goed het systeem presteert
In uitgebreide tests werd FaceScanPaliGemma vergeleken met bekende, algemene AI-systemen zoals GPT-4o en Gemini, evenals met traditionele deep-learningmodellen die uitsluitend op beeldverwerking zijn gebaseerd. Voor rasherkenning bereikte het nieuwe systeem ongeveer 81% nauwkeurigheid bij het groeperen van meerdere raciale categorieën, een duidelijke verbetering ten opzichte van eerdere visionsystemen en kant-en-klare visie–taalmodellen. Het behaalde rond de 96% nauwkeurigheid voor geslacht en 80% voor bredere leeftijdsgroepen, waarmee het sterke referenties evenaarde of overtrof. Emotieherkenning bleek lastiger: hier bereikte FaceScanPaliGemma ongeveer 59% nauwkeurigheid—beter dan voorgetrainde visie–taalmodellen en sommige klassieke methoden, maar nog steeds onder de allerbeste emotiegerichte systemen die op miljoenen afbeeldingen zijn getraind. De auteurs onderzochten ook hoe de prestaties variëren tussen verschillende demografische groepen en vonden kleine verschillen voor geslacht maar grotere voor bepaalde rassen en subtiele uitdrukkingen, wat zij koppelen aan de inherente moeilijkheid van het beoordelen van op uiterlijk gebaseerde kenmerken.
Eerlijkheid, risico’s en gebruik in de echte wereld
Aangezien herkenning van gelaatskenmerken raakt aan identiteit, privacy en discriminatie, besteden de auteurs speciale aandacht aan ethiek. Zij benadrukken dat FaceScanPaliGemma is getraind op openbare onderzoeksdatasets en dat de modellen worden vrijgegeven met duidelijke richtlijnen tegen misbruik in domeinen zoals massale surveillance of geautomatiseerde besluitvorming. Het multi-agent-ontwerp helpt ook: door ras, geslacht, leeftijd en emotie in afzonderlijke modules te scheiden, wordt het makkelijker om vooroordelen in elk van hen onafhankelijk te meten en te verminderen. Toch kent het systeem beperkingen. Het is hoofdzakelijk getest op benchmarkdatasets in plaats van op rommelige, echte wereldbeelden, en het legt nog niet uit hoe het tot zijn beslissingen komt—beide belangrijke terreinen voor toekomstig werk.
Wat dit werk betekent voor de toekomst
Kort gezegd toont deze studie aan dat een gecoördineerd team van kleinere, gespecialiseerde AI-modellen gezichten nauwkeuriger en flexibeler kan lezen dan veel grotere, enkelvoudige modellen, vooral wanneer ze worden geleid door zorgvuldig gekozen trainingsgegevens. FaceScanPaliGemma is sneller en goedkoper te draaien dan veel gigantische modellen, en toch evenaart of overtreft het hen op een aantal belangrijke taken. Tegelijkertijd benadrukt het onderzoek dat het aflezen van menselijke eigenschappen uit gezichten onzeker en ethisch beladen blijft, met name voor emoties en visueel ambigue groepen. De auteurs pleiten ervoor dat toekomstige vooruitgang technische verbeteringen—zoals betere trainingsdata en gefaseerd leren—moet koppelen aan sterkere waarborgen rond eerlijkheid, privacy en transparantie voordat dergelijke systemen op grote schaal worden ingezet.
Bronvermelding: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
Trefwoorden: herkenning van gelaatskenmerken, visie-taalmodellen, multi-agent AI, fairface-dataset, emotieherkenning