Clear Sky Science · en
FaceScanPaliGemma multi-agent vision language models for facial attribute recognition
Why Smarter Face Reading Matters
Every day, cameras capture countless images of people: in social media posts, online meetings, and public spaces. Behind the scenes, computer systems increasingly try to "read" these faces, guessing things like age, mood, and other traits. Such tools can power useful services, from accessibility aids to health research, but they also raise deep questions about fairness, privacy, and bias. This paper introduces FaceScanPaliGemma, a new AI system designed not only to improve how computers read faces, but also to pay closer attention to who might be left out or treated unfairly.
A New Team-Based Approach to Reading Faces
Most past face-analysis systems rely on a single, large model that tries to do everything at once: detect race, gender, age group, and emotion from an image. FaceScanPaliGemma takes a different route. It uses a “team” of smaller, specialized models that work together, each one focusing on just one task. These models are built on a vision–language design, meaning they can look at a picture and also process a written prompt about what the user wants to know. For example, the system can answer questions such as “What is the age group and emotion of the child in this picture?” by combining what it sees with what it is asked.
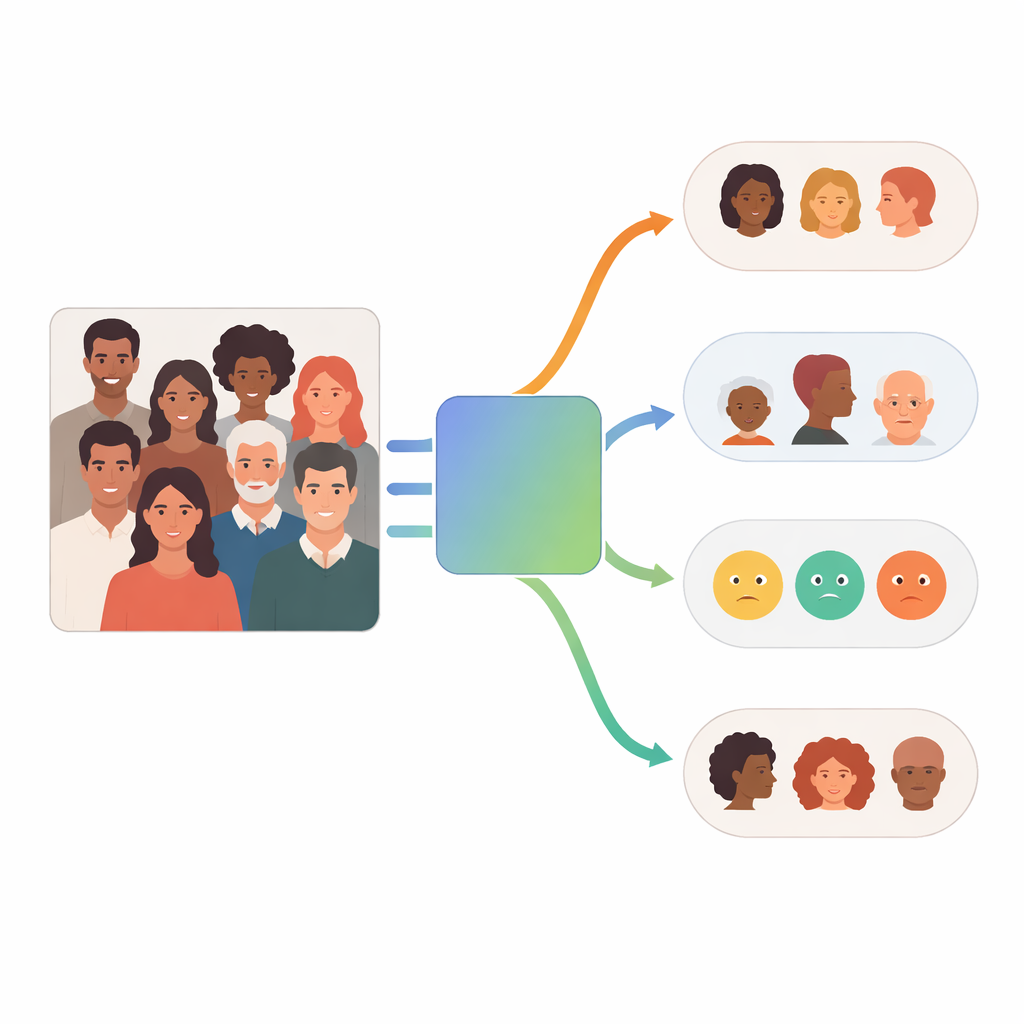
How the Multi-Agent System Works
At the heart of FaceScanPaliGemma is an analysis agent that reads the user’s request and breaks it down into steps. If the query mentions a specific person in a busy scene—for instance, “the boy holding a ball” or “the Middle Eastern woman”—the analysis agent first calls on a face-detection model to locate the relevant faces. It then forwards those cropped faces to one or more specialist agents devoted to race, gender, age group, or emotion. Each specialist is a fine-tuned version of Google’s PaliGemma vision–language model, trained on labeled face images to become highly accurate at its single task. The analysis agent finally combines the pieces into an answer that follows the original request.
Building on Fairer and Larger Face Datasets
To train and test these agents, the researchers relied on two major public datasets. The first, FairFace, consists of more than one hundred thousand faces carefully balanced across several racial groups and including labels for gender and detailed age ranges. This design helps reduce the common problem of having far more examples of certain groups, such as white faces, than others. The second dataset, AffectNet, contains hundreds of thousands of images tagged with eight basic facial expressions, from happiness to contempt, collected from the web in multiple languages. By fine-tuning PaliGemma models on these datasets, the team adapted a general-purpose vision–language tool into four focused experts for race, gender, age group, and emotion recognition.
How Well the System Performs
In extensive tests, FaceScanPaliGemma was compared against well-known, general-purpose AI systems such as GPT-4o and Gemini, as well as against traditional deep-learning models based purely on image processing. For race recognition, the new system reached about 81% accuracy when grouping several racial categories, a clear gain over both earlier vision systems and off-the-shelf vision–language models. It achieved around 96% accuracy for gender, and 80% for broader age groups, again matching or exceeding strong baselines. Emotion recognition proved tougher: here, FaceScanPaliGemma reached about 59% accuracy—better than pre-trained vision–language models and some classic methods, but still below the very best emotion-focused systems trained on millions of images. The authors also examined how performance varies across different demographic groups and found small gaps for gender but larger ones for certain races and subtle expressions, which they link to the inherent difficulty of judging appearance-based traits.
Fairness, Risks, and Real-World Use
Because facial attribute recognition touches on identity, privacy, and discrimination, the authors devote special attention to ethics. They emphasize that FaceScanPaliGemma was trained on public research datasets and that the models are released with clear guidance against misuse in areas such as mass surveillance or automated decision-making. The multi-agent design also helps: by separating race, gender, age, and emotion into distinct modules, it becomes easier to measure and reduce bias in each one independently. Still, the system has limits. It has been tested mainly on benchmark datasets rather than messy real-world images, and it does not yet explain how it reaches its decisions—both important fronts for future work.
What This Work Means Going Forward
In plain terms, this study shows that a coordinated team of smaller, specialized AI models can read faces more accurately and flexibly than many larger, single-model systems, especially when guided by carefully chosen training data. FaceScanPaliGemma is faster and cheaper to run than many giant models, yet it still rivals or beats them on several key tasks. At the same time, the research underscores that reading human traits from faces remains uncertain and ethically fraught, particularly for emotions and for visually ambiguous groups. The authors argue that future progress should pair technical advances—such as better training data and staged learning—with stronger safeguards around fairness, privacy, and transparency before such systems are widely deployed.
Citation: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
Keywords: facial attribute recognition, vision language models, multi-agent AI, fairface dataset, emotion recognition