Clear Sky Science · ru
FaceScanPaliGemma: многоагентные визуально-языковые модели для распознавания черт лица
Почему важно умнее «читать» лица
Ежедневно камеры фиксируют бесчисленное количество изображений людей: в публикациях в социальных сетях, на онлайн-встречах и в общественных местах. За кулисами компьютерные системы всё чаще пытаются «читать» эти лица, оценивая возраст, настроение и другие характеристики. Такие инструменты могут обеспечивать полезные сервисы — от средств доступности до исследований в медицине, — но они также поднимают серьёзные вопросы о справедливости, приватности и предвзятости. В этой статье представлен FaceScanPaliGemma — новая система ИИ, созданная не только для повышения точности компьютерного «чтения» лиц, но и для более внимательного отношения к тому, кто может оказаться в невыгодном положении или столкнуться с несправедливым обращением.
Новый командный подход к анализу лиц
Большинство предыдущих систем анализа лиц опираются на одну большую модель, которая пытается делать всё: определять расу, пол, возрастную группу и эмоции по изображению. FaceScanPaliGemma идёт другим путём. Система использует «команду» из небольших специализированных моделей, которые работают совместно, каждая сосредоточена на одной задаче. Эти модели построены по схеме «визуально-языковой» модели, то есть они не только анализируют изображение, но и обрабатывают текстовые подсказки о том, что пользователь хочет узнать. Например, система может ответить на вопрос «Какая возрастная группа и эмоция у ребёнка на этой фотографии?», сочетая то, что видит, с формулировкой запроса.
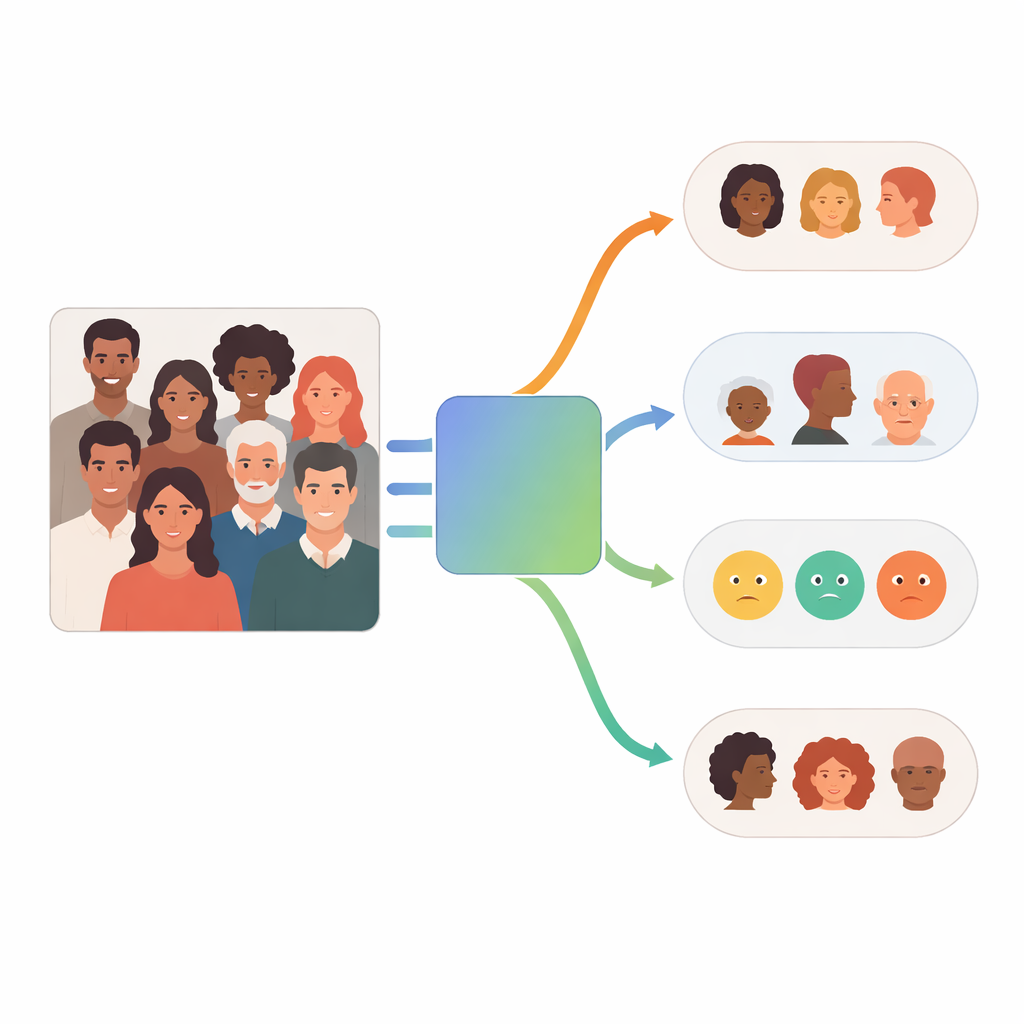
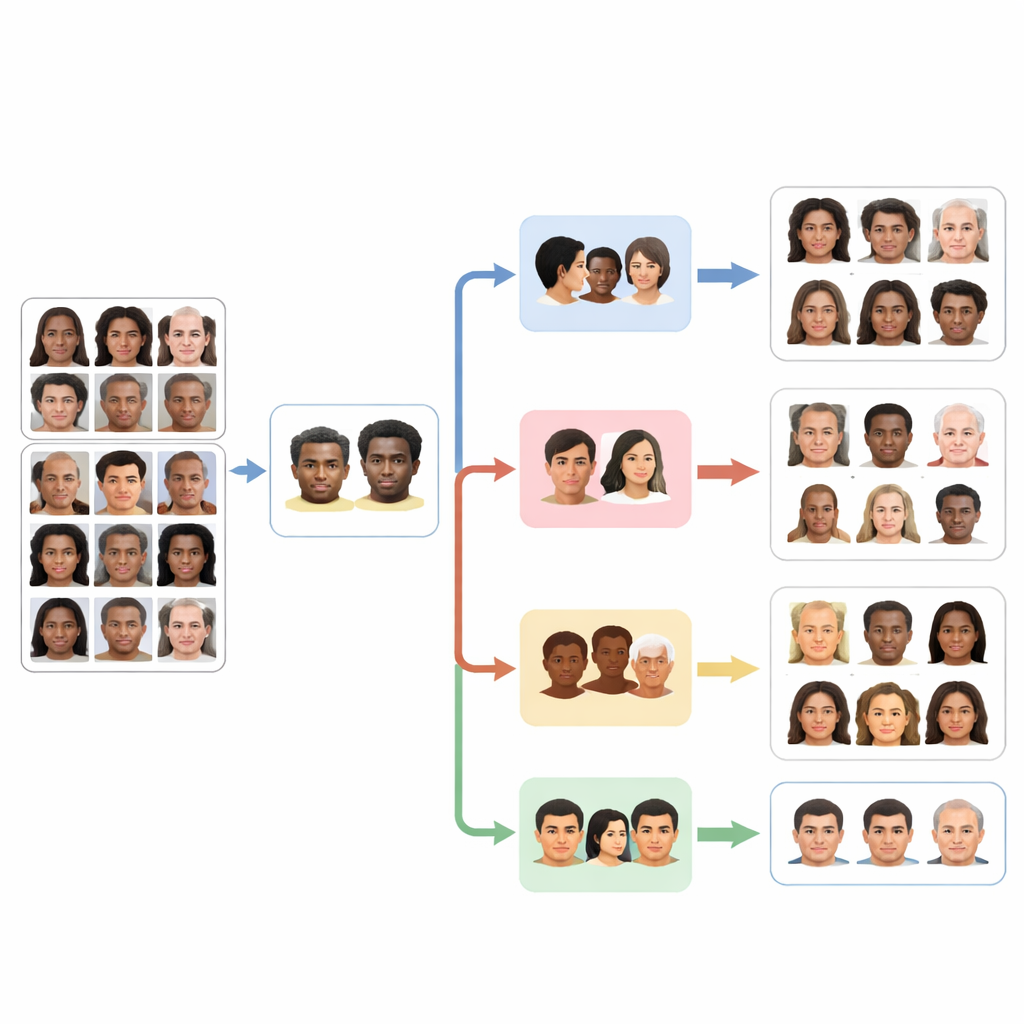
Как работает многоагентная система
В основе FaceScanPaliGemma лежит аналитический агент, который читает запрос пользователя и разбивает его на шаги. Если в запросе упоминается конкретный человек в загруженной сцене — например, «мальчик, держащий мяч», или «женщина ближневосточного происхождения» — аналитический агент сначала вызывает модель обнаружения лиц, чтобы локализовать нужные лица. Затем он передаёт вырезанные лица одному или нескольким специализированным агентам, отвечающим за расу, пол, возрастную группу или эмоции. Каждый специалист — это дообученная версия визуально-языковой модели PaliGemma от Google, натренированная на размеченных изображениях лиц для высокой точности в своей единственной задаче. В конце аналитический агент объединяет результаты в ответ, соответствующий первоначальному запросу.
Опора на более справедливые и крупные наборы данных лиц
Для обучения и тестирования этих агентов исследователи использовали два крупных публичных набора данных. Первый, FairFace, включает более ста тысяч лиц, аккуратно сбалансированных по нескольким расовым группам и снабжённых метками пола и подробных возрастных диапазонов. Такая организация помогает сократить распространённую проблему неравномерного представительства, когда примеров одних групп, например белых лиц, значительно больше, чем других. Второй набор, AffectNet, содержит сотни тысяч изображений, помеченных восьми базовыми выражениями лица — от радости до презрения — собранных из интернета на разных языках. Дообучив модели PaliGemma на этих наборах, команда адаптировала универсальный визуально-языковой инструмент в четыре узкоспециализированных эксперта по распознаванию расы, пола, возрастной группы и эмоций.
Насколько хорошо работает система
В обширных тестах FaceScanPaliGemma сравнивали с известными универсальными системами ИИ, такими как GPT-4o и Gemini, а также с традиционными глубокими моделями, основанными исключительно на обработке изображений. Для распознавания расы новая система достигла около 81% точности при группировке нескольких расовых категорий, что является заметным улучшением по сравнению с прежними визуальными системами и готовыми визуально-языковыми моделями. По полу точность составила примерно 96%, по более широким возрастным группам — около 80%, что также совпадает с лучшими или превосходит их. Распознавание эмоций оказалось сложнее: здесь FaceScanPaliGemma достигла примерно 59% точности — лучше, чем предобученные визуально-языковые модели и некоторые классические методы, но всё ещё ниже самых сильных систем, ориентированных на эмоции и обученных на миллионах изображений. Авторы также изучили, как меняется производительность по разным демографическим группам, и обнаружили небольшие разрывы по полу, но более значительные — для некоторых рас и тонких выражений, что они связывают со сложностью оценки признаков, основанных на внешности.
Справедливость, риски и применение в реальном мире
Поскольку распознавание черт лица затрагивает вопросы идентичности, приватности и дискриминации, авторы уделяют этому особое внимание в этической части работы. Они подчёркивают, что FaceScanPaliGemma обучалась на публичных исследовательских наборах данных и что модели публикуются с чёткими рекомендациями по недопущению злоупотреблений в областях, таких как массовое слежение или автоматизированное принятие решений. Многоагентная архитектура также помогает: разделение расы, пола, возраста и эмоций на отдельные модули облегчает измерение и снижение предвзятости в каждом из них независимо. Тем не менее у системы есть ограничения. Она в основном тестировалась на эталонных наборах данных, а не на «грязных» реальных изображениях, и пока не объясняет, как принимает решения — оба эти направления важны для будущих исследований.
Что это означает для будущего
Проще говоря, исследование показывает, что скоординированная команда небольших специализированных моделей может распознавать черты лица более точно и гибко, чем многие крупные одноцепочечные системы, особенно при использовании тщательно подобранных данных для обучения. FaceScanPaliGemma работает быстрее и дешевле многих гигантских моделей, при этом соперничая с ними или превосходя по ряду ключевых задач. В то же время работа подчёркивает, что чтение человеческих качеств по лицу остаётся неопределённым и этически проблематичным, особенно в отношении эмоций и визуально неоднозначных групп. Авторы утверждают, что дальнейший прогресс должен сочетать технические улучшения — например, лучшие данные для обучения и поэтапное обучение — с усиленными гарантиями в отношении справедливости, приватности и прозрачности, прежде чем такие системы будут широко внедряться.
Цитирование: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
Ключевые слова: распознавание черт лица, визуально-языковые модели, многоагентный ИИ, набор данных FairFace, распознавание эмоций