Clear Sky Science · pt
FaceScanPaliGemma modelos de visão e linguagem multiagente para reconhecimento de atributos faciais
Por que uma Leitura de Rosto mais Inteligente Importa
Todos os dias, câmeras capturam inúmeras imagens de pessoas: em postagens de redes sociais, reuniões online e espaços públicos. Nos bastidores, sistemas computacionais tentam cada vez mais “ler” esses rostos, inferindo coisas como idade, humor e outros traços. Essas ferramentas podem viabilizar serviços úteis, desde recursos de acessibilidade até pesquisas em saúde, mas também levantam questões profundas sobre equidade, privacidade e viés. Este artigo apresenta o FaceScanPaliGemma, um novo sistema de IA projetado não só para melhorar como os computadores leem rostos, mas também para prestar mais atenção a quem pode ser excluído ou tratado de forma injusta.
Uma Nova Abordagem em Equipe para Ler Rostos
A maioria dos sistemas de análise facial anteriores depende de um único modelo grande que tenta fazer tudo de uma vez: detectar raça, gênero, faixa etária e emoção a partir de uma imagem. O FaceScanPaliGemma segue um caminho diferente. Ele usa uma “equipe” de modelos menores e especializados que trabalham em conjunto, cada um focado em apenas uma tarefa. Esses modelos são construídos com um design visão–linguagem, ou seja, são capazes de olhar para uma imagem e também processar um prompt escrito sobre o que o usuário deseja saber. Por exemplo, o sistema pode responder perguntas como “Qual é a faixa etária e a emoção da criança nesta foto?” combinando o que vê com o que é solicitado.
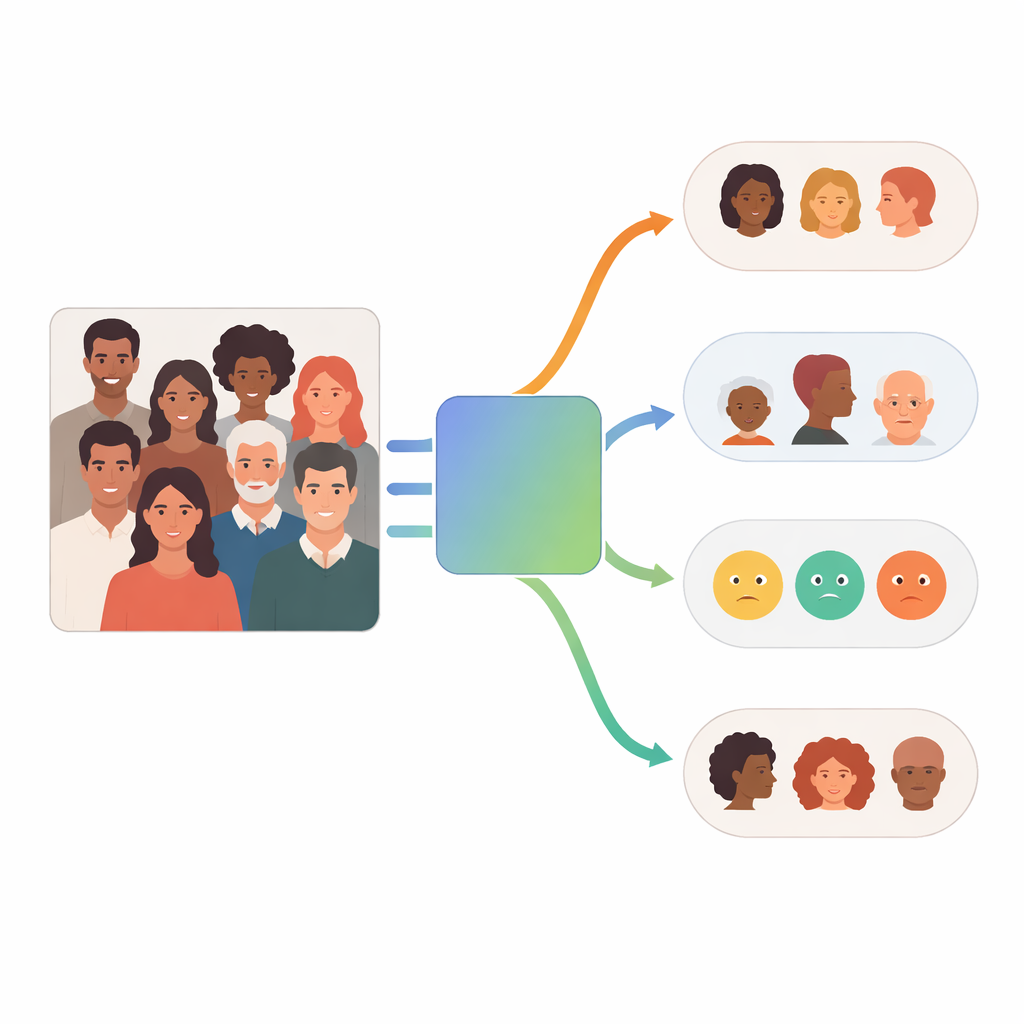
Como o Sistema Multiagente Funciona
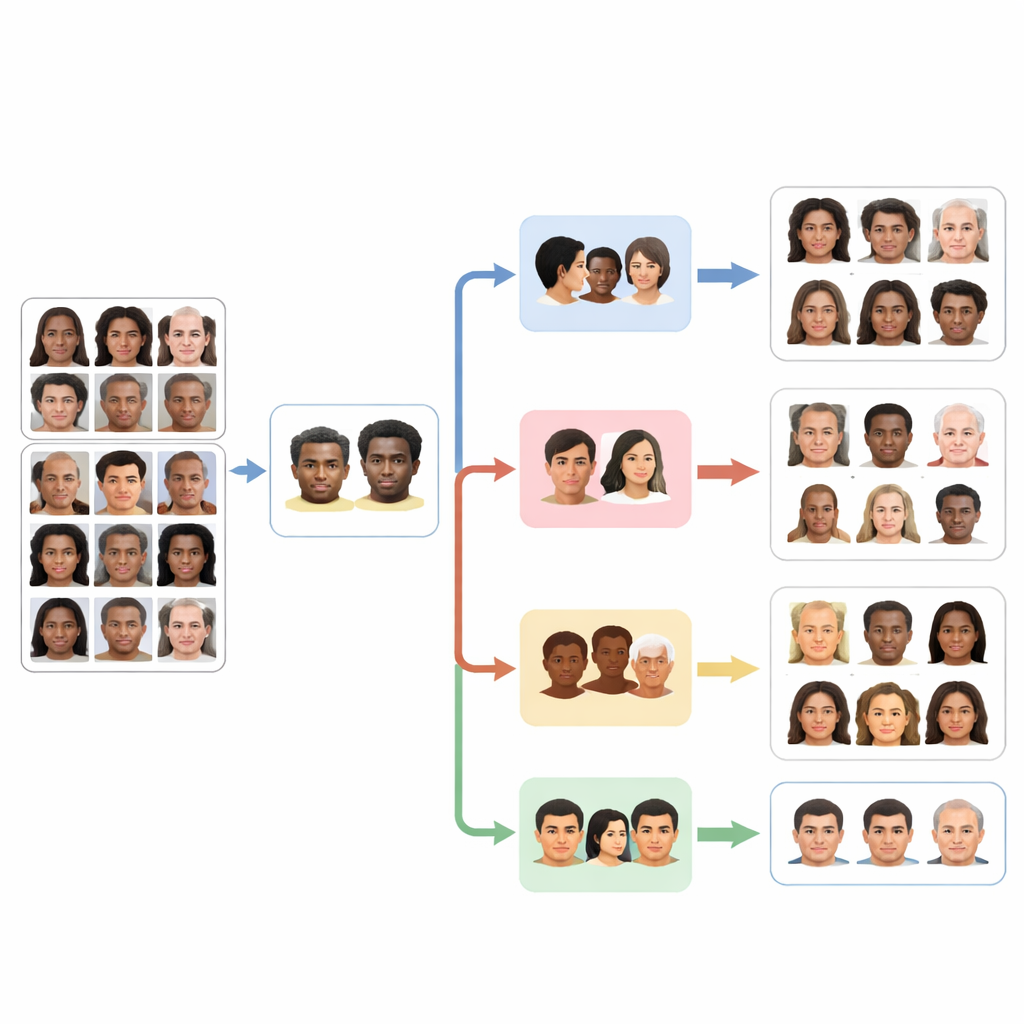
No centro do FaceScanPaliGemma está um agente de análise que lê a solicitação do usuário e a divide em etapas. Se a consulta menciona uma pessoa específica em uma cena movimentada — por exemplo, “o garoto segurando uma bola” ou “a mulher do Oriente Médio” — o agente de análise primeiro recorre a um modelo de detecção de faces para localizar os rostos relevantes. Em seguida, envia essas faces recortadas para um ou mais agentes especialistas dedicados a raça, gênero, faixa etária ou emoção. Cada especialista é uma versão ajustada (fine-tuned) do modelo visão–linguagem PaliGemma do Google, treinada em imagens faciais rotuladas para se tornar altamente precisa em sua tarefa única. O agente de análise finalmente combina as partes em uma resposta que segue a solicitação original.
Construindo sobre Conjuntos de Dados Faciais Maiores e Mais Justos
Para treinar e testar esses agentes, os pesquisadores recorreram a dois grandes conjuntos de dados públicos. O primeiro, FairFace, consiste em mais de cem mil rostos cuidadosamente balanceados entre vários grupos raciais e incluindo rótulos para gênero e faixas etárias detalhadas. Esse desenho ajuda a reduzir o problema comum de ter muito mais exemplos de certos grupos, como rostos brancos, do que de outros. O segundo conjunto, AffectNet, contém centenas de milhares de imagens rotuladas com oito expressões faciais básicas, da felicidade ao desprezo, coletadas na web em múltiplos idiomas. Ao ajustar os modelos PaliGemma nesses conjuntos de dados, a equipe adaptou uma ferramenta visão–linguagem de propósito geral em quatro especialistas focados para reconhecimento de raça, gênero, faixa etária e emoção.
Desempenho do Sistema
Em testes extensivos, o FaceScanPaliGemma foi comparado com sistemas de IA de propósito geral bem conhecidos, como GPT-4o e Gemini, assim como com modelos tradicionais de deep learning baseados puramente em processamento de imagem. Para reconhecimento de raça, o novo sistema alcançou cerca de 81% de acurácia ao agrupar várias categorias raciais, um ganho claro sobre sistemas de visão anteriores e modelos visão–linguagem prontos para uso. Obteve cerca de 96% de acurácia para gênero e 80% para faixas etárias mais amplas, novamente igualando ou superando fortes referências. O reconhecimento de emoções mostrou-se mais difícil: aqui, o FaceScanPaliGemma alcançou cerca de 59% de acurácia — melhor que modelos visão–linguagem pré-treinados e alguns métodos clássicos, mas ainda abaixo dos melhores sistemas focados em emoção treinados com milhões de imagens. Os autores também examinaram como o desempenho varia entre diferentes grupos demográficos e encontraram pequenas diferenças por gênero, mas lacunas maiores para certas raças e expressões sutis, que eles relacionam à dificuldade inerente de julgar traços baseados na aparência.
Justiça, Riscos e Uso no Mundo Real
Como o reconhecimento de atributos faciais toca em identidade, privacidade e discriminação, os autores dedicam atenção especial à ética. Eles enfatizam que o FaceScanPaliGemma foi treinado em conjuntos de dados de pesquisa públicos e que os modelos são disponibilizados com orientações claras contra o uso indevido em áreas como vigilância em massa ou tomada de decisão automatizada. O desenho multiagente também ajuda: ao separar raça, gênero, idade e emoção em módulos distintos, torna-se mais fácil medir e reduzir o viés em cada um independentemente. Ainda assim, o sistema tem limites. Foi testado principalmente em conjuntos de referência em vez de imagens reais e desordenadas do mundo cotidiano, e ainda não explica como chega às suas decisões — ambos pontos importantes para trabalhos futuros.
O Que Este Trabalho Significa para o Futuro
Em termos simples, este estudo mostra que uma equipe coordenada de modelos de IA menores e especializados pode ler rostos com mais precisão e flexibilidade do que muitos sistemas maiores de modelo único, especialmente quando guiada por dados de treinamento cuidadosamente selecionados. O FaceScanPaliGemma é mais rápido e mais barato de executar do que muitos modelos gigantes, e ainda assim rivaliza ou supera eles em várias tarefas-chave. Ao mesmo tempo, a pesquisa ressalta que inferir traços humanos a partir de rostos permanece incerto e eticamente delicado, particularmente para emoções e para grupos visualmente ambíguos. Os autores defendem que o progresso futuro combine avanços técnicos — como melhores dados de treinamento e aprendizado em etapas — com salvaguardas mais fortes em torno da equidade, privacidade e transparência antes que tais sistemas sejam amplamente implantados.
Citação: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
Palavras-chave: reconhecimento de atributos faciais, modelos visão-linguagem, IA multiagente, conjunto de dados FairFace, reconhecimento de emoções