Clear Sky Science · ar
نموذج FaceScanPaliGemma متعدد العملاء للرؤية واللغة للتعرّف على صفات الوجوه
لماذا يهم تحسين قراءة الوجوه
تلتقط الكاميرات يوميًا عددًا هائلًا من صور الناس: في منشورات وسائل التواصل الاجتماعي، والاجتماعات عبر الإنترنت، وفي الأماكن العامة. في الخلفية، تحاول أنظمة الحاسوب بشكل متزايد "قراءة" هذه الوجوه، وتخمين أمور مثل العمر والحالة المزاجية وسمات أخرى. يمكن أن تغذي هذه الأدوات خدمات مفيدة، من مساعدات الوصول إلى بحوث صحية، لكنها تثير أيضًا أسئلة عميقة حول العدالة والخصوصية والتحيّز. تقدم هذه الورقة FaceScanPaliGemma، نظام ذكاء اصطناعي جديد مصمم ليس فقط لتحسين قدرة الحواسيب على قراءة الوجوه، وإنما أيضًا لإيلاء اهتمام أكبر لمن قد يُستبعد أو يُعامل بإنصاف أقل.
نهج جديد قائم على فريق من النماذج
تعتمد معظم أنظمة تحليل الوجوه السابقة على نموذج واحد كبير يحاول أداء كل شيء دفعة واحدة: اكتشاف العرق والجنس والفئة العمرية والعاطفة من صورة. يسلك FaceScanPaliGemma طريقًا مختلفًا. فهو يستخدم "فريقًا" من النماذج الأصغر والمتخصّصة التي تعمل معًا، وكل منها يركز على مهمة واحدة فقط. بُنيت هذه النماذج على تصميم رؤية–لغة، ما يعني أنها قادرة على النظر إلى صورة ومعالجة موجه نصي حول ما يريد المستخدم معرفته. على سبيل المثال، يمكن للنظام الإجابة عن أسئلة مثل «ما الفئة العمرية والعاطفة للطفل في هذه الصورة؟» بدمج ما يراه مع ما سُئل عنه.
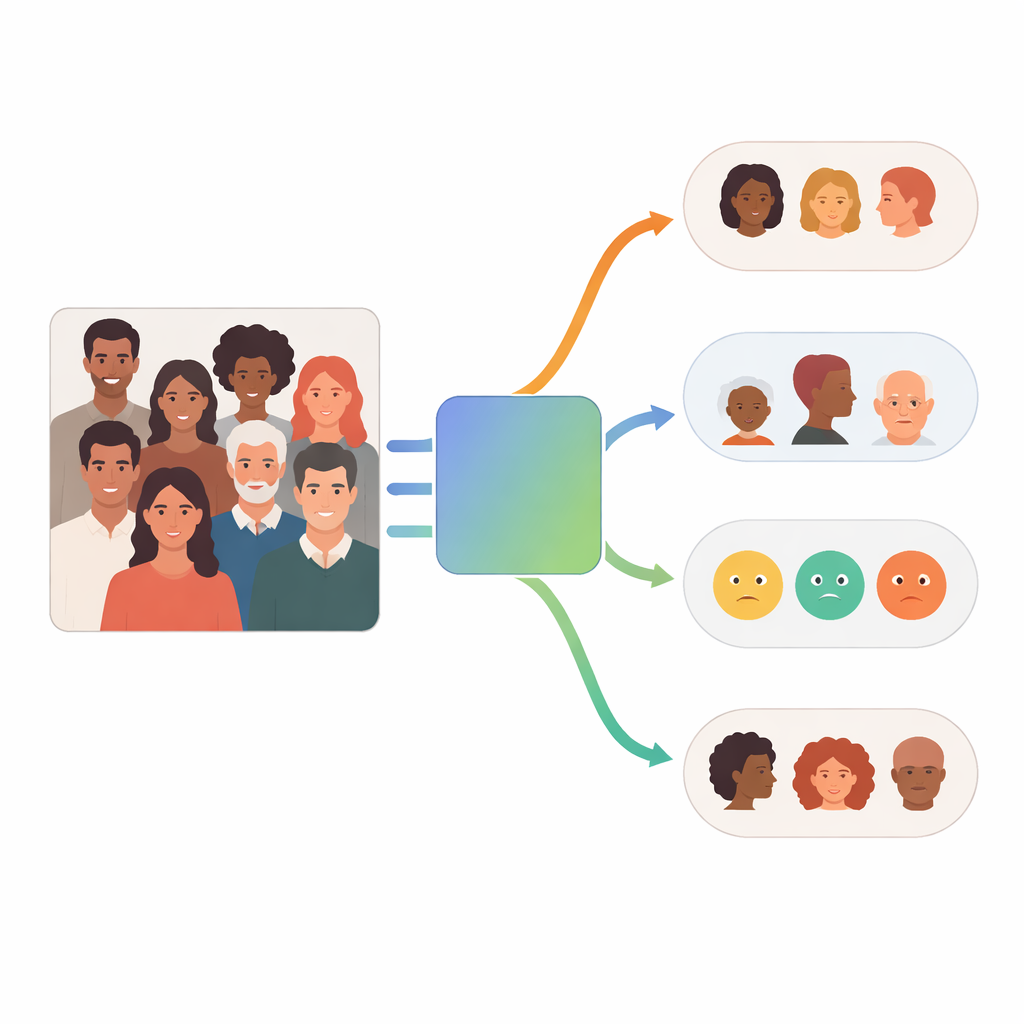
كيف يعمل النظام متعدد العملاء
في صلب FaceScanPaliGemma وكيل تحليلي يقرأ طلب المستخدم ويقسمه إلى خطوات. إذا ذكرت الاستعلام شخصًا محددًا في مشهد مزدحم—على سبيل المثال، "الولد الذي يحمل كرة" أو "المرأة الشرق أوسطية"—يقوم الوكيل التحليلي أولًا باستدعاء نموذج كشف الوجوه لتحديد موقع الوجوه المعنية. ثم يرسل تلك الوجوه المقتطفة إلى واحد أو أكثر من الوكلاء المتخصصين المكرّسين للعرق أو الجنس أو الفئة العمرية أو العاطفة. كل متخصص هو نسخة مخصصة ومدققة من نموذج PaliGemma للرؤية–اللغة من Google، مدرّب على صور وجوه معنونة ليصبح دقيقًا للغاية في مهمته الواحدة. يجمع الوكيل التحليلي أخيرًا الأجزاء لتكوين إجابة تتبع الطلب الأصلي.
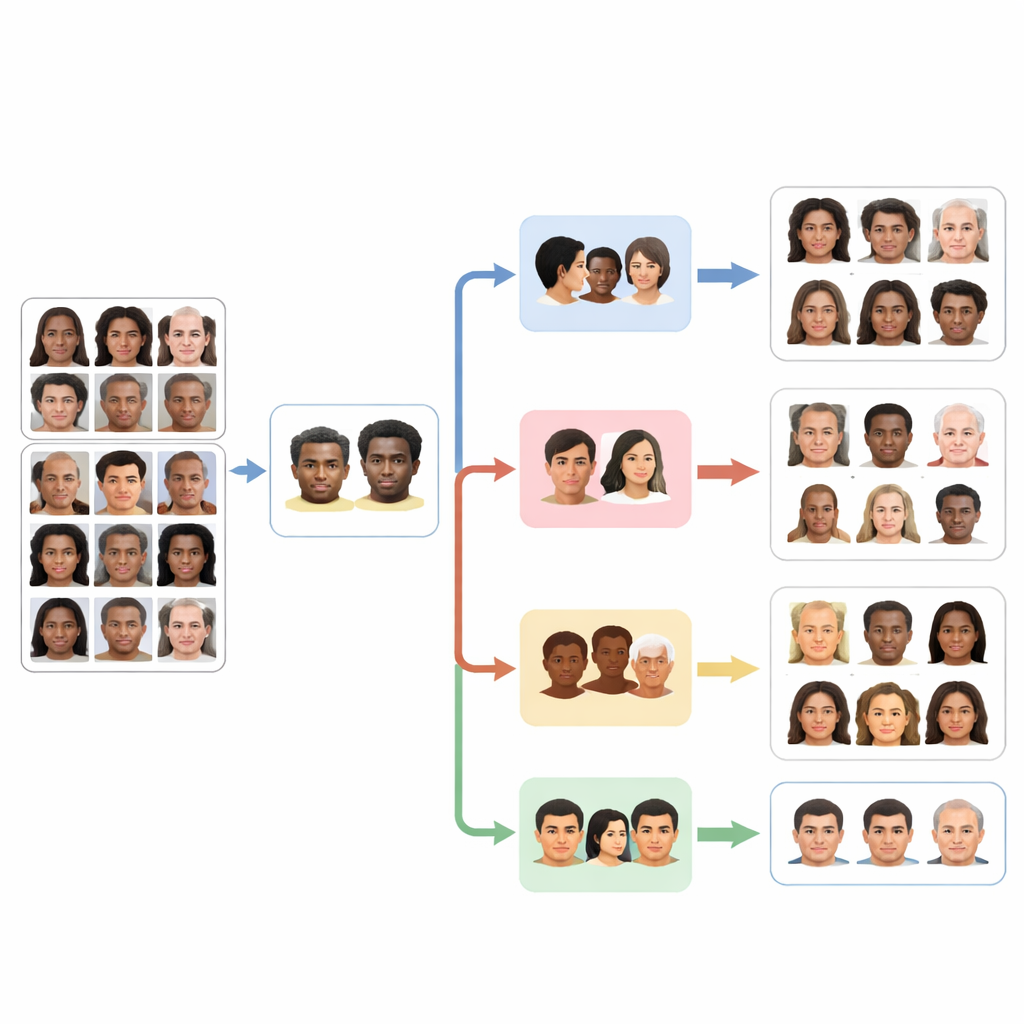
البناء على مجموعات بيانات للوجوه أكبر وأكثر عدالة
لتدريب هذه الوكلاء واختبارهم، اعتمد الباحثون على مجموعتين عامتين رئيسيتين. الأولى، FairFace، تتكوّن من أكثر من مائة ألف وجه موزونة بعناية عبر عدة مجموعات عنصرية وتتضمن تسميات للجنس ونطاقات عمرية مفصّلة. يساعد هذا التصميم في تقليل المشكلة الشائعة المتمثلة في وجود أمثلة أكثر بكثير لمجموعات معينة، مثل الوجوه البيضاء، مقارنة بغيرها. المجموعة الثانية، AffectNet، تحتوي على مئات الآلاف من الصور الموسومة بثمانية تعبيرات وجهية أساسية، من السعادة إلى الازدراء، جمعت من الويب بعدة لغات. من خلال ضبط نماذج PaliGemma على هذه المجموعات، حوّل الفريق أداة رؤية–لغة عامة إلى أربعة خبراء مركّزين للتعرّف على العرق والجنس والفئة العمرية والعاطفة.
مدى أداء النظام
في اختبارات واسعة، قورن FaceScanPaliGemma بأنظمة ذكاء اصطناعي معروفة عامة مثل GPT-4o وGemini، وكذلك مع نماذج التعلم العميق التقليدية المبنية على معالجة الصور فقط. في تعرّف العرق، حقق النظام الجديد دقة تقارب 81% عند تجميع عدة فئات عرقية، وهو مكسب واضح مقارنة بأنظمة الرؤية السابقة ونماذج الرؤية–اللغة الجاهزة. وبلغت دقته حوالي 96% في التعرّف على الجنس، و80% للفئات العمرية الأوسع، مما يوازي أو يتجاوز خطوط الأساس القوية. كان التعرف على العاطفة أصعب: هنا وصل FaceScanPaliGemma إلى نحو 59% دقة—أفضل من نماذج الرؤية–اللغة المدربة مسبقًا وبعض الأساليب الكلاسيكية، لكنه لا يزال أدنى من أفضل الأنظمة المتخصصة في العواطف والمدرّبة على ملايين الصور. كما فحص المؤلفون كيف يختلف الأداء عبر مجموعات ديموغرافية مختلفة ووجدوا فجوات صغيرة للجنس لكن أكبر لبعض الأعراق والتعبيرات الطفيفة، التي ربطوها بصعوبة الحكم على الصفات المبنية على المظهر.
العدالة والمخاطر والاستخدام الواقعي
بما أن التعرّف على صفات الوجه يتداخل مع الهوية والخصوصية والتمييز، يكرّس المؤلفون اهتمامًا خاصًا للأخلاقيات. يؤكدون أن FaceScanPaliGemma تم تدريبه على مجموعات بيانات بحثية عامة وأن النماذج نُشرت مع توجيهات واضحة ضد سوء الاستخدام في مجالات مثل المراقبة الشاملة أو اتخاذ القرار الآلي. يساعد التصميم متعدد العملاء أيضًا في ذلك: عبر فصل العرق والجنس والعمر والعاطفة إلى وحدات منفصلة، يصبح من الأسهل قياس وتقليل التحيّز في كل منها بشكل مستقل. مع ذلك، للنظام حدود. فقد اختُبر أساسًا على مجموعات معيارية أكثر من كونه على صور العالم الحقيقي الفوضوية، ولا يشرح بعد كيف يصل إلى قراراته—وهما جبهتان مهمّتان للعمل المستقبلي.
ماذا يعني هذا العمل للمستقبل
بعبارة بسيطة، تُظهر هذه الدراسة أن فريقًا من نماذج ذكاء اصطناعي أصغر ومتخصّصة يمكنه قراءة الوجوه بدقة ومرونة أكبر من العديد من أنظمة النموذج الواحد الأكبر، لا سيما عند توجيهه ببيانات تدريب مختارة بعناية. FaceScanPaliGemma أسرع وأرخص في التشغيل من العديد من النماذج الضخمة، ومع ذلك ينافسها أو يتفوق عليها في عدة مهام أساسية. في الوقت نفسه، تؤكد الأبحاث أن قراءة صفات البشر من الوجوه تظل غير مؤكدة ومشحونة أخلاقيًا، خصوصًا بالنسبة للعواطف وللمجموعات البصرية الغامضة. يجادل المؤلفون بأن التقدم المستقبلي ينبغي أن يواكب تحسينات تقنية—مثل بيانات تدريب أفضل وتعلّم مرحلي—مع ضمانات أقوى حول العدالة والخصوصية والشفافية قبل نشر مثل هذه الأنظمة على نطاق واسع.
الاستشهاد: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
الكلمات المفتاحية: التعرّف على صفات الوجه, نماذج الرؤية واللغة, الذكاء الاصطناعي متعدد العملاء, مجموعة بيانات FairFace, التعرّف على العاطفة