Clear Sky Science · it
FaceScanPaliGemma modelli visione-linguaggio multi-agente per il riconoscimento degli attributi facciali
Perché leggere i volti in modo più intelligente è importante
Ogni giorno le fotocamere catturano innumerevoli immagini di persone: nei post sui social, nelle riunioni online e negli spazi pubblici. Dietro le quinte, i sistemi informatici cercano sempre più spesso di “leggere” questi volti, ipotizzando età, stato d’animo e altri tratti. Tali strumenti possono alimentare servizi utili, dall’accessibilità alla ricerca sanitaria, ma sollevano anche questioni profonde su equità, privacy e bias. Questo articolo presenta FaceScanPaliGemma, un nuovo sistema di IA progettato non solo per migliorare il modo in cui i computer leggono i volti, ma anche per prestare maggiore attenzione a chi potrebbe essere escluso o trattato in modo ingiusto.
Un nuovo approccio a squadra per leggere i volti
La maggior parte dei sistemi di analisi facciale passati si basa su un unico grande modello che cerca di fare tutto insieme: rilevare razza, genere, fascia d’età ed emozione da un’immagine. FaceScanPaliGemma prende una strada diversa. Usa una “squadra” di modelli più piccoli e specializzati che collaborano, ciascuno concentrato su un solo compito. Questi modelli sono costruiti su un design visione–linguaggio, il che significa che possono guardare un’immagine e allo stesso tempo elaborare un prompt scritto su ciò che l’utente vuole sapere. Per esempio, il sistema può rispondere a domande come “Qual è la fascia d’età e l’emozione del bambino in questa foto?” combinando ciò che vede con ciò che gli viene chiesto.
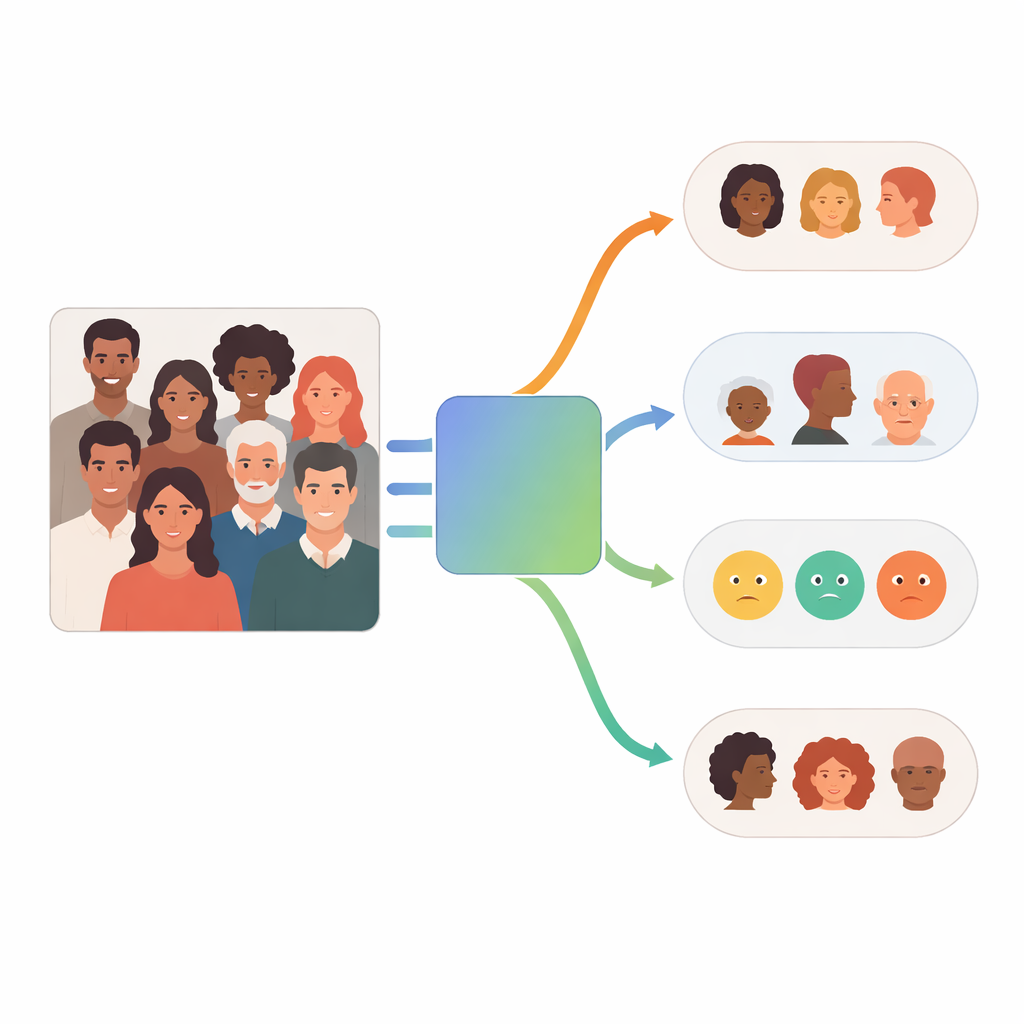
Come funziona il sistema multi-agente
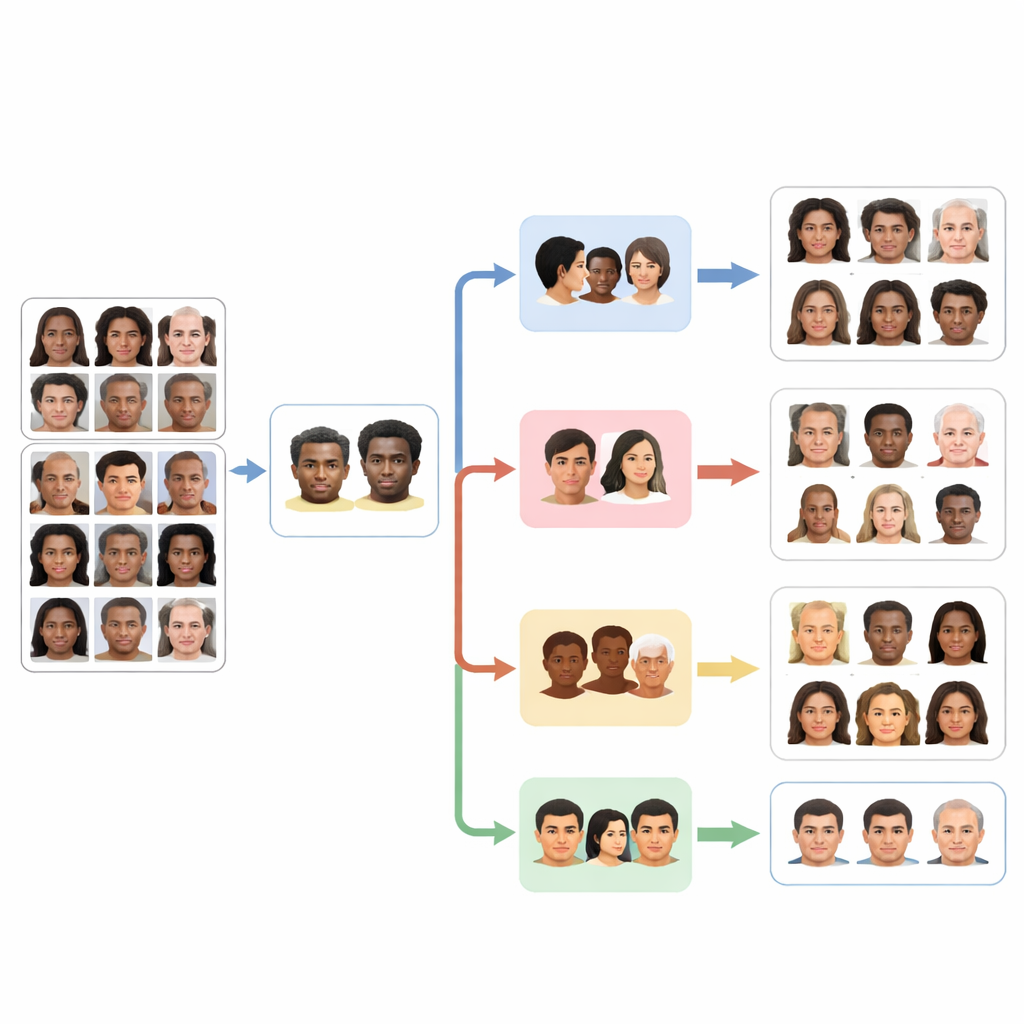
Al centro di FaceScanPaliGemma c’è un agente di analisi che legge la richiesta dell’utente e la scompone in passaggi. Se la query menziona una persona specifica in una scena affollata—per esempio, “il ragazzo con la palla” o “la donna mediorientale”—l’agente di analisi richiama prima un modello di rilevamento dei volti per localizzare i volti rilevanti. Quindi invia quei volti ritagliati a uno o più agenti specialisti dedicati a razza, genere, fascia d’età o emozione. Ciascun specialista è una versione fine-tuned del modello visione–linguaggio PaliGemma di Google, addestrata su immagini facciali etichettate per diventare molto precisa nel suo singolo compito. L’agente di analisi infine combina i pezzi in una risposta che segue la richiesta originale.
Costruire su dataset facciali più equi e più grandi
Per addestrare e testare questi agenti, i ricercatori si sono appoggiati a due importanti dataset pubblici. Il primo, FairFace, comprende oltre centomila volti accuratamente bilanciati tra diversi gruppi razziali e include etichette per genere e fasce d’età dettagliate. Questa progettazione aiuta a ridurre il problema comune di avere molti più esempi di alcuni gruppi, come i volti bianchi, rispetto ad altri. Il secondo dataset, AffectNet, contiene centinaia di migliaia di immagini etichettate con otto espressioni facciali di base, dalla felicità al disprezzo, raccolte dal web in più lingue. Affinando i modelli PaliGemma su questi dataset, il team ha adattato uno strumento visione–linguaggio di uso generale in quattro esperti focalizzati per il riconoscimento di razza, genere, fascia d’età ed emozione.
Quanto bene si comporta il sistema
In test estesi, FaceScanPaliGemma è stato confrontato con sistemi di IA noti e generici come GPT-4o e Gemini, oltre che con modelli di deep learning tradizionali basati esclusivamente sull’elaborazione delle immagini. Per il riconoscimento della razza, il nuovo sistema ha raggiunto circa l’81% di accuratezza raggruppando diverse categorie razziali, un chiaro miglioramento rispetto sia ai precedenti sistemi di visione che ai modelli visione–linguaggio pronti all’uso. Ha ottenuto circa il 96% di accuratezza per il genere e l’80% per fasce d’età più ampie, e ancora eguagliando o superando solide baseline. Il riconoscimento delle emozioni si è rivelato più difficile: qui FaceScanPaliGemma ha raggiunto circa il 59% di accuratezza—meglio dei modelli visione–linguaggio pre-addestrati e di alcuni metodi classici, ma ancora sotto i migliori sistemi focalizzati sulle emozioni addestrati su milioni di immagini. Gli autori hanno anche esaminato come le prestazioni varino tra diversi gruppi demografici e hanno trovato piccoli divari per il genere ma differenze maggiori per alcune razze e per espressioni sottili, che collegano alla difficoltà intrinseca del giudicare tratti basati sull’aspetto.
Equità, rischi e uso nel mondo reale
Poiché il riconoscimento degli attributi facciali tocca identità, privacy e discriminazione, gli autori dedicano particolare attenzione all’etica. Sottolineano che FaceScanPaliGemma è stato addestrato su dataset di ricerca pubblici e che i modelli sono rilasciati con indicazioni chiare contro l’abuso in ambiti come la sorveglianza di massa o il processo decisionale automatizzato. Il design multi-agente aiuta inoltre: separando razza, genere, età ed emozione in moduli distinti, diventa più semplice misurare e ridurre il bias in ciascuno indipendentemente. Tuttavia, il sistema ha limiti. È stato testato soprattutto su dataset di riferimento piuttosto che su immagini del mondo reale più disordinate, e non spiega ancora come giunge alle sue decisioni—due fronti importanti per lavori futuri.
Cosa significa questo lavoro per il futuro
In termini pratici, questo studio mostra che una squadra coordinata di modelli di IA più piccoli e specializzati può leggere i volti con maggiore accuratezza e flessibilità rispetto a molti sistemi più grandi a modello singolo, soprattutto se guidata da dati di addestramento scelti con cura. FaceScanPaliGemma è più veloce e meno costoso da eseguire rispetto a molti modelli giganti, eppure li rivaleggia o li supera su diversi compiti chiave. Allo stesso tempo, la ricerca sottolinea che inferire tratti umani dai volti resta incerto e carico di implicazioni etiche, in particolare per le emozioni e per gruppi visivamente ambigui. Gli autori sostengono che i progressi futuri dovrebbero accoppiare innovazioni tecniche—come dati di addestramento migliori e apprendimento a stadi—with garanzie più forti su equità, privacy e trasparenza prima che tali sistemi vengano ampiamente dispiegati.
Citazione: AlDahoul, N., Tan, M.J.T., Kasireddy, H.R. et al. FaceScanPaliGemma multi-agent vision language models for facial attribute recognition. Sci Rep 16, 10246 (2026). https://doi.org/10.1038/s41598-026-39584-3
Parole chiave: riconoscimento degli attributi facciali, modelli visione-linguaggio, IA multi-agente, dataset fairface, riconoscimento delle emozioni