Clear Sky Science · sv
Intrinsisk stabilisering av synaptisk plasticitet förbättrar inlärning och robusthet i artificiella neurala nätverk
Hur hjärnan inspirerar stadigare inlärning i maskiner
När vi lär oss en ny färdighet förblir våra hjärnor på något sätt tillräckligt flexibla för att ta upp ny information men ändå tillräckligt stabila för att inte glömma det vi redan kan. Modern artificiell intelligens brottas ofta med denna balans: den lär sig snabbt men blir ibland skör eller instabil. Denna studie hämtar inspiration från hjärnans återkopplingssignaler för att utforma ett nytt sätt för artificiella neurala nätverk att lära sig mer effektivt samtidigt som de förblir robusta inför brus, skiftande uppgifter och vilseledande exempel.
En ny vägledande signal inne i lärande maskiner
De flesta maskininlärningssystem bygger på ett enkelt recept: jämför nätverkets förutsägelse med rätt svar och justera kopplingarna för att minska skillnaden. Denna bottom-up-strategi fungerar väl men bortser från de rika top-down-signaler som flödar i verkliga hjärnor och förmedlar förväntningar, kontext och prediktioner. Författarna introducerar en tillsats kallad intrinsisk Top-Down Stabilisering (iTDS). Istället för att enbart jaga det korrekta svaret lär sig nätverket också en långsammare, intern signal som följer dess egna tidigare utsignaler. Denna långsamt förändrande signal matas tillbaka in i inlärningsregeln, så varje koppling formas inte bara av extern felinformation utan också av hur nätverket tenderar att bete sig över tid.
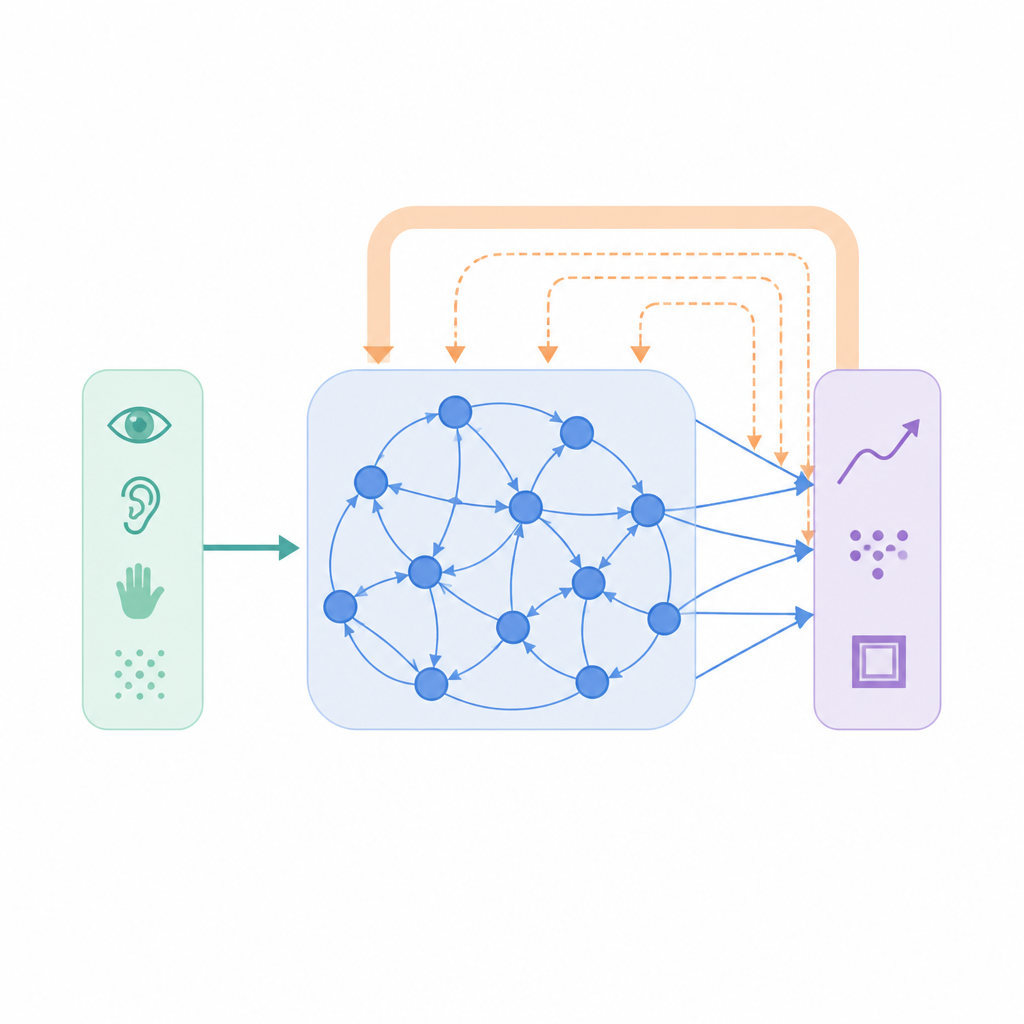
Lära nätverk att minnas sina egna vanor
I iTDS håller nätverket ett löpande, utjämnat register över sin senaste utsignalaktivitet. Detta interna spår försöker inte förutsäga framtida data eller råsensorisk input; det blir helt enkelt en filtrerad ek av vad nätverket redan producerat. Under träning trycker den vanliga feltermen kopplingarna mot rätt mål, medan top-down-termen jämför den aktuella utsignalen med denna eko. När nätverkets aktivitet är starkt variabel tenderar dessa två influenser att peka i liknande riktning, förstärka varandra och påskynda inlärningen. Allteftersom träningen fortskrider och nätverket hittar ett mer konsekvent mönster, försvagas top-down-påverkan gradvis och fungerar mer som en stabilisator än som en drivkraft för förändring.
Bättre tidsingång, kategorisering och att hantera kaos
Forskarna testade iTDS i flera typer av neurala nätverk, inklusive rekurrenta, feedforward och reservoirmodeller, över sexton uppgifter. Dessa varierade från att följa mjuka signaler över tid, till att känna igen handskrivna siffror, till att lösa enkla logiska problem. I många fall ledde tillsats av iTDS till snabbare träning och lägre fel än standardövervakad inlärning ensam, även när de underliggande nätverksdynamikerna var kaotiska. Metoden var särskilt effektiv när nätverken hade många aktiva enheter eller när utsignalerna svängde kraftigt, förhållanden som är vanliga både i biologiska och artificiella system.
Lärande från brusiga och vilseledande exempel
Data i verkliga världen är sällan rena. För att testa robustheten tillsatte författarna avsiktligt brus i input, roterade bilder bort från deras vanliga orientering och smög till och med in "kontramål" där exempel parade ihop med fel svar. Under dessa påfrestande förhållanden tenderade nätverk som endast använde standardinlärning att överreagera och förändra sina kopplingar på ohjälpsamma sätt. Med iTDS fungerade den långsamma top-down-signalen som en broms: när ett överraskande eller motstridigt exempel dök upp, delvis annullerade de två inlärningspåverkningarna varandra och minskade storleken på viktändringen. Som en följd var nätverk med iTDS mer motståndskraftiga mot både slumpmässiga störningar och listigt valda perturbationer som normalt lurar klassificerare.
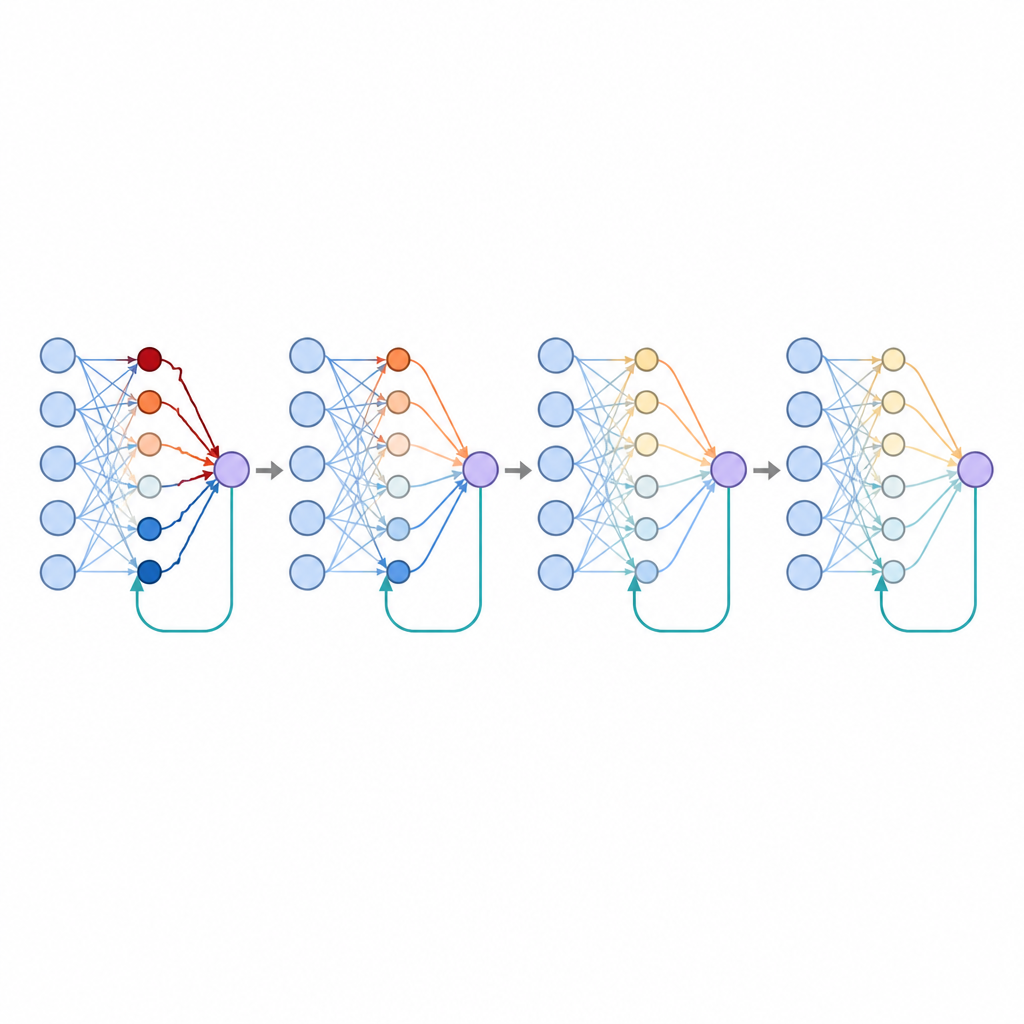
Varför det spelar roll att dela upp positiv och negativ återkoppling
Studien undersökte också vad som händer när vissa kopplingar specialiserar sig på att bara spåra positiva fel och andra bara negativa, vilket speglar hur vissa hjärnceller reagerar olika på belöningar och motgångar. Denna separation gav naturligt upphov till glesare mönster av förbindelser, där många kopplingar förblev nära noll medan en mindre undergrupp bar det mesta av påverkan. Sådan gleshet är känd för att förbättra generalisering, och här sänkte den dessutom felnivåerna ytterligare. Författarna visade att det att tvångshålla många vikter vid noll återspeglade mycket av denna fördel, vilket tyder på att specialiserad återkoppling kan vara en biologisk väg till sparsamma, effektiva representationer.
Vad detta betyder för framtida hjärnor och maskiner
Sammantaget visar iTDS-ramverket att genom att ge lärande maskiner en långsamt föränderlig känsla av sitt eget senaste beteende kan de bli snabbare lärande och mer stabila problemlösare. Istället för att bara förlita sig på den omedelbara avvikelsen från rätt svar klarar nätverk som blandar snabba korrigeringar med mjuk, top-down-stabilisering bättre av brus, förvirring och förändring. För hjärnforskningen erbjuder modellen konkreta förutsägelser om hur återkopplingsvägar kan forma inlärning. För artificiell intelligens antyder den att inbyggda självövervakningssignaler över flera tidsskalor kan vara en praktisk väg mot system som lär sig mer likt oss och som sällar sig mindre ofta när världen blir rörig.
Citering: Pilzak, A., Pennington, B. & Thivierge, JP. Intrinsic stabilization of synaptic plasticity improves learning and robustness in artificial neural networks. Nat Commun 17, 4164 (2026). https://doi.org/10.1038/s41467-026-70920-3
Nyckelord: synaptisk plasticitet, top-down-återkoppling, rekurrenta neurala nätverk, robust inlärning, brusresistens