Clear Sky Science · nl
Intrinsieke stabilisatie van synaptische plasticiteit verbetert leren en robuustheid in kunstmatige neurale netwerken
Hoe hersenen stabieler leren in machines inspireren
Als we een nieuwe vaardigheid leren, blijven onze hersenen op de een of andere manier flexibel genoeg om nieuwe informatie op te nemen, en toch stabiel genoeg om niet te vergeten wat we al weten. Moderne kunstmatige intelligentie worstelt vaak met dit evenwicht: het leert snel maar kan soms kwetsbaar of instabiel worden. Deze studie put inspiratie uit de feedbacksignalen van de hersenen om een nieuwe manier te ontwerpen waarop kunstmatige neurale netwerken efficiënter kunnen leren en tegelijk robuust blijven bij ruis, veranderende taken en misleidende voorbeelden.
Een nieuw sturend signaal binnen leermachines
De meeste machine learning-systemen volgen een eenvoudige regeling: vergelijk wat het netwerk voorspelt met het juiste antwoord en pas de verbindingen aan om dat verschil te verkleinen. Deze bottom-upbenadering werkt goed, maar negeert de rijke top-downsignalen die in echte hersenen stromen en verwachtingen, context en voorspellingen dragen. De auteurs introduceren een extra ingrediënt genoemd intrinsieke Top-Down Stabilisatie (iTDS). In plaats van alleen het juiste antwoord na te jagen, leert het netwerk ook een trager, intern signaal dat zijn eigen eerdere output volgt. Dit langzaam veranderende signaal wordt teruggevoerd in de leerregel, zodat elke verbinding niet alleen door externe fouten wordt gevormd, maar ook door hoe het netwerk zich in de loop van de tijd gedraagt.
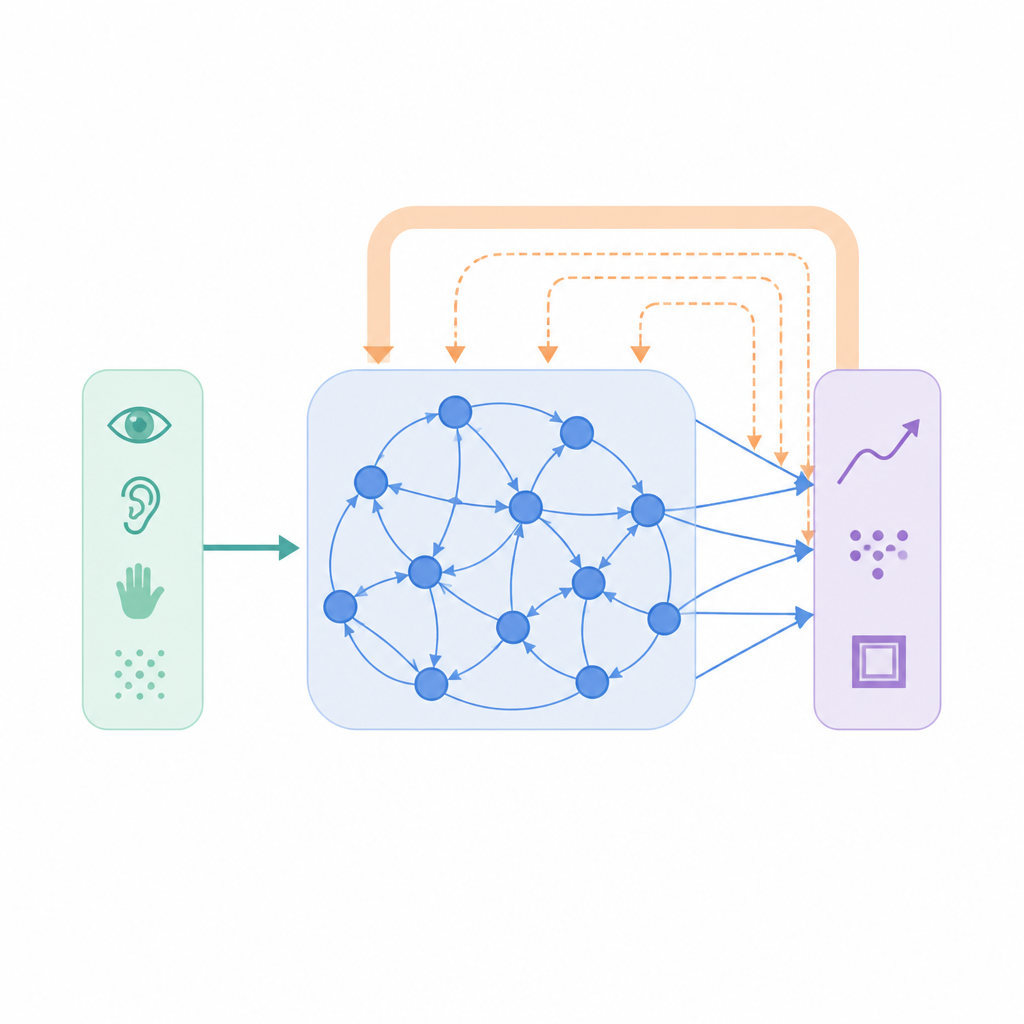
Netwerken leren hun eigen gewoonten te onthouden
Bij iTDS houdt het netwerk een lopend, gladgesmeerd verslag bij van zijn recente outputactiviteit. Deze interne trace probeert geen toekomstige data of ruwe zintuiglijke input te voorspellen; het wordt eenvoudigweg een gefilterde echo van wat het netwerk al geproduceerd heeft. Tijdens training drukt de gebruikelijke foutterm de verbindingen richting het juiste doel, terwijl de top-downterm de huidige output vergelijkt met deze echo. Wanneer de activiteit van het netwerk sterk varieert, wijzen deze twee invloeden vaak in een vergelijkbare richting, versterken ze elkaar en versnellen ze het leren. Naarmate de training vordert en het netwerk in een consistenter patroon stabiliseert, verzwakt de top-downinvloed geleidelijk en werkt ze meer als stabilisator dan als aanjager van verandering.
Betere timing, categorisering en omgaan met chaos
De onderzoekers testten iTDS in verschillende typen neurale netwerken, waaronder recurrente, feedforward- en reservoirmodellen, over zestien taken. Deze varieerden van het volgen van vloeiende signalen in de tijd, tot het herkennen van handgeschreven cijfers, tot het oplossen van eenvoudige logische problemen. In veel gevallen leidde het toevoegen van iTDS tot snellere training en lagere fouten dan standaard supervised learning alleen, zelfs wanneer de onderliggende netwerkdynamiek chaotisch was. De methode bleek vooral effectief wanneer de netwerken veel actieve eenheden hadden of wanneer de outputsignalen sterk fluctueren — omstandigheden die zowel in biologische als kunstmatige systemen vaak voorkomen.
Leren van ruwe en misleidende voorbeelden
Data uit de echte wereld zijn zelden zuiver. Om de robuustheid te testen, voegden de auteurs opzettelijk ruis toe aan inputs, draaiden ze beelden weg van hun gebruikelijke oriëntatie en voegden ze zelfs "tegenproeven" toe waarin voorbeelden aan het verkeerde antwoord werden gekoppeld. Onder deze stressvolle omstandigheden neigden netwerken die alleen standaard leren gebruikten te overreageren en hun verbindingen op ongewenste manieren te herschikken. Met iTDS functioneerde het trage top-downsignaal als een rem: wanneer een verrassend of tegenstrijdig voorbeeld verscheen, hieven de twee leerinvloeden elkaar deels op, waardoor de grootte van de gewichtsverandering kleiner werd. Daardoor waren netwerken met iTDS beter bestand tegen zowel willekeurige vervormingen als doelbewust gekozen perturbaties die classifiers normaal gesproken misleiden.
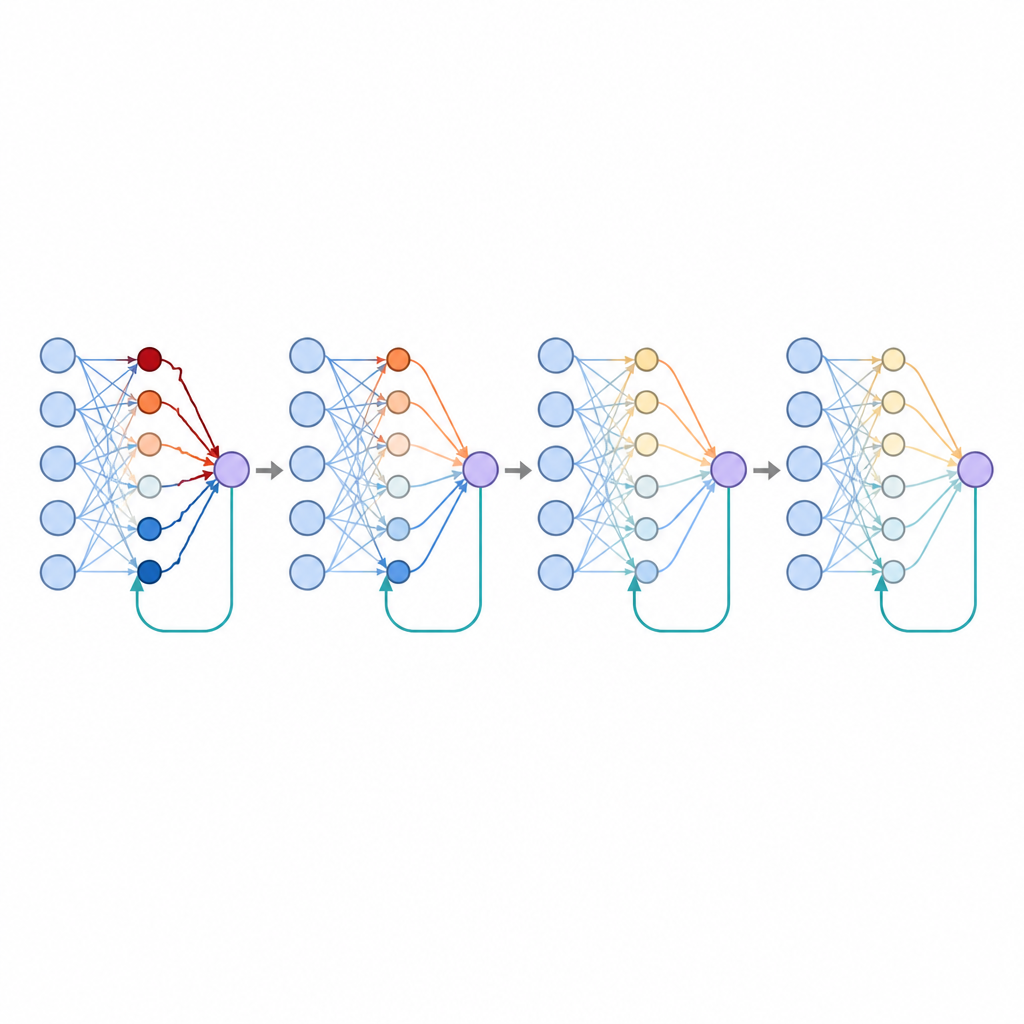
Waarom het scheiden van positieve en negatieve feedback ertoe doet
De studie onderzocht ook wat er gebeurt als sommige verbindingen zich specialiseren in het alleen volgen van positieve fouten en andere alleen negatieve fouten volgen, waarmee wordt geëmuleerd hoe bepaalde hersencellen verschillend reageren op beloningen en tegenslagen. Deze scheiding bracht op natuurlijke wijze spaarzamere patronen van connectiviteit voort, waarbij veel verbindingen dicht bij nul bleven terwijl een kleinere subset het grootste deel van de invloed droeg. Zulke sparsity staat bekend om het verbeteren van generalisatie en verlaagde hier verder de foutpercentages. De auteurs toonden aan dat het simpelweg dwingen van veel gewichten om op nul te blijven veel van dit voordeel nabootste, wat suggereert dat gespecialiseerde feedback een biologische route kan zijn om zuinige, efficiënte representaties te bereiken.
Wat dit betekent voor toekomstige hersenen en machines
Al met al laat het iTDS-kader zien dat het geven van een leermachine van een langzaam veranderend besef van haar eigen recente gedrag ze snellere leerlingen en stabielere probleemoplossers kan maken. In plaats van uitsluitend te vertrouwen op de onmiddellijke mismatch met het juiste antwoord, kunnen netwerken die snelle correcties combineren met zachte, top-down stabilisatie beter omgaan met ruis, verwarring en verandering. Voor de hersenwetenschap biedt het model concrete voorspellingen over hoe terugkoppelingspaden leren kunnen vormgeven. Voor kunstmatige intelligentie suggereert het dat het inbouwen van zelfmonitorende signalen, over meerdere tijdschalen, een praktische weg kan zijn naar systemen die meer zoals wij leren en minder vaak falen wanneer de wereld rommelig wordt.
Bronvermelding: Pilzak, A., Pennington, B. & Thivierge, JP. Intrinsic stabilization of synaptic plasticity improves learning and robustness in artificial neural networks. Nat Commun 17, 4164 (2026). https://doi.org/10.1038/s41467-026-70920-3
Trefwoorden: synaptische plasticiteit, top-down terugkoppeling, recurrente neurale netwerken, robuust leren, ruisbestendigheid