Clear Sky Science · de
Intrinsische Stabilisierung synaptischer Plastizität verbessert Lernen und Robustheit in künstlichen neuronalen Netzen
Wie das Gehirn stabileres Lernen in Maschinen inspiriert
Wenn wir eine neue Fähigkeit erlernen, bleibt unser Gehirn auf seltsame Weise flexibel genug, um Neues aufzunehmen, und gleichzeitig stabil genug, um bereits Gelerntes nicht zu vergessen. Moderne künstliche Intelligenz hat oft Schwierigkeiten mit diesem Gleichgewicht: Sie lernt schnell, kann dabei aber fragil oder instabil werden. Diese Studie lässt sich von den Feedbacksignalen des Gehirns inspirieren, um eine neue Methode zu entwerfen, mit der künstliche neuronale Netze effizienter lernen und gleichzeitig robust gegenüber Rauschen, wechselnden Aufgaben und irreführenden Beispielen bleiben.
Ein neues leitendes Signal innerhalb lernender Maschinen
Die meisten Machine-Learning-Systeme folgen einem einfachen Rezept: Vergleiche die Vorhersage des Netzes mit der korrekten Antwort und justiere die Verbindungen, um diese Differenz zu verringern. Dieser Bottom-up-Ansatz funktioniert gut, ignoriert aber die reichen Top-down-Signale, die durch reale Gehirne fließen und Erwartungen, Kontext und Vorhersagen transportieren. Die Autoren führen eine zusätzliche Komponente ein, genannt intrinsische Top-Down-Stabilisierung (iTDS). Anstatt nur der korrekten Antwort hinterherzulaufen, lernt das Netzwerk außerdem ein langsameres internes Signal, das seine eigene vergangene Ausgabe nachverfolgt. Dieses sanft veränderliche Signal wird in die Lernregel zurückgespeist, sodass jede Verbindung nicht nur durch externen Fehler geformt wird, sondern auch danach, wie sich das Netzwerk im Zeitverlauf typischerweise verhält.
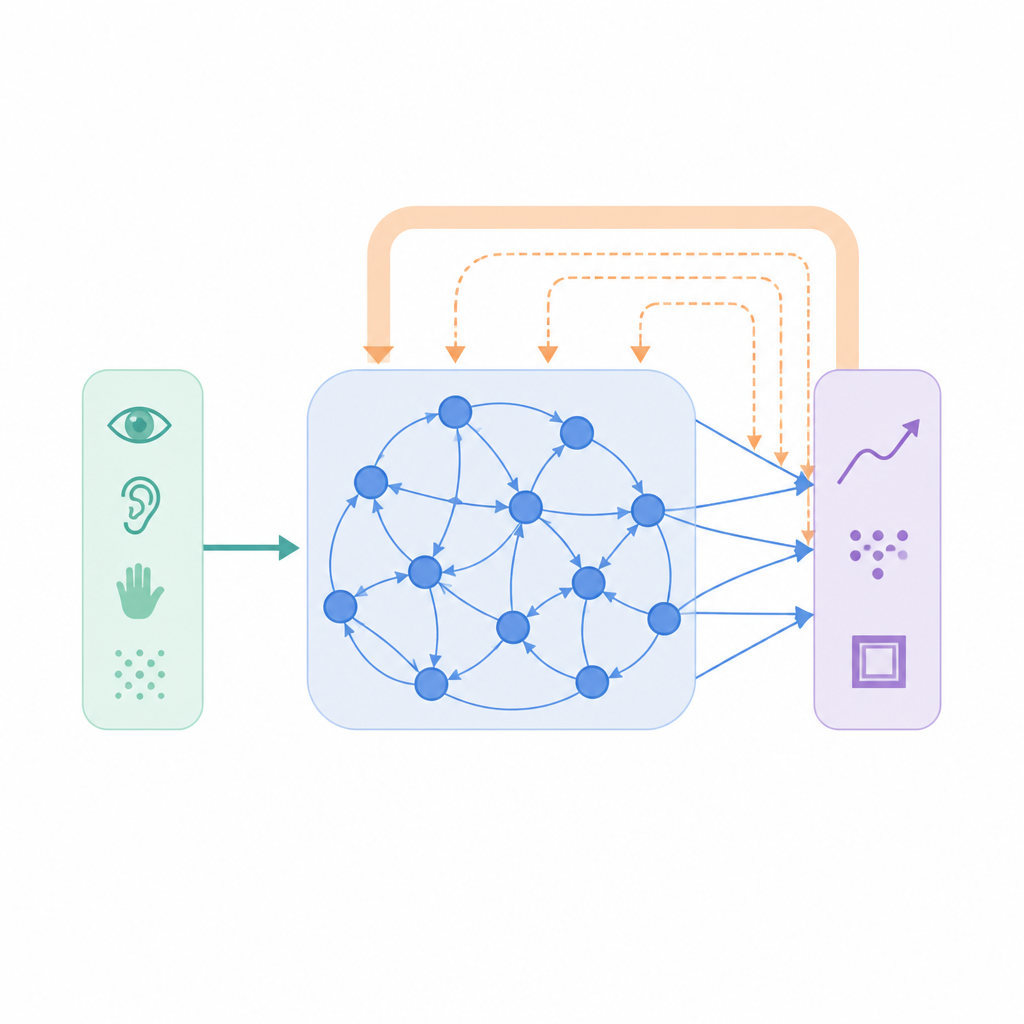
Netze lehren, sich an ihre eigenen Gewohnheiten zu erinnern
Bei iTDS hält das Netzwerk eine laufende, geglättete Aufzeichnung seiner jüngsten Aktivitätsausgaben. Diese interne Spur versucht nicht, zukünftige Daten oder rohe sensorische Eingaben vorherzusagen; sie wird einfach zu einem gefilterten Echo dessen, was das Netzwerk bereits produziert hat. Während des Trainings drängt der übliche Fehlert erm die Verbindungen in Richtung Ziel, während der Top-down-Term die aktuelle Ausgabe mit diesem Echo vergleicht. Wenn die Aktivität des Netzwerks stark variiert, zeigen diese beiden Einflüsse oft in eine ähnliche Richtung, verstärken sich gegenseitig und beschleunigen das Lernen. Mit fortschreitendem Training und zunehmender Konsistenz der Muster schwächt der Top-down-Einfluss allmählich ab und wirkt eher als Stabilisator denn als Triebkraft der Veränderung.
Bessere Zeitsteuerung, Kategorisierung und Umgang mit Chaos
Die Forscher testeten iTDS in mehreren Netztopologien, einschließlich rekurrenter, feedforward- und Reservoir-Modelle, über sechzehn Aufgaben hinweg. Diese reichten vom Verfolgen glatter Signale über die Zeit bis hin zur Erkennung handschriftlicher Ziffern und dem Lösen einfacher logischer Probleme. In vielen Fällen führte die Ergänzung durch iTDS zu schnellerem Training und geringerem Fehler als reines überwachtes Lernen, selbst wenn die zugrundeliegenden Netzwerkdynamiken chaotisch waren. Die Methode war besonders effektiv, wenn die Netze viele aktive Einheiten hatten oder wenn die Ausgangssignale stark schwankten — Bedingungen, die sowohl in biologischen als auch in künstlichen Systemen häufig vorkommen.
Aus verrauschten und irreführenden Beispielen lernen
Echte Daten sind selten sauber. Um die Robustheit zu prüfen, fügten die Autoren absichtlich Rauschen zu Eingaben hinzu, drehten Bilder aus ihrer üblichen Orientierung und mischten sogar „Konterversuche“ bei, in denen Beispiele mit der falschen Antwort gepaart wurden. Unter diesen Stressbedingungen neigten Netze mit nur Standardlernen dazu, überzureagieren und ihre Verbindungen in unproduktive Richtungen umzubauen. Mit iTDS wirkte das langsame Top-down-Signal wie eine Bremse: Wenn ein überraschendes oder widersprüchliches Beispiel auftauchte, hoben sich die beiden Lerneinflüsse teilweise gegenseitig auf, wodurch die Größe der Gewichtsanpassung reduziert wurde. Infolgedessen waren Netze mit iTDS widerstandsfähiger gegenüber zufälligen Verzerrungen und gezielten Störungen, mit denen Klassifikatoren normalerweise getäuscht werden.
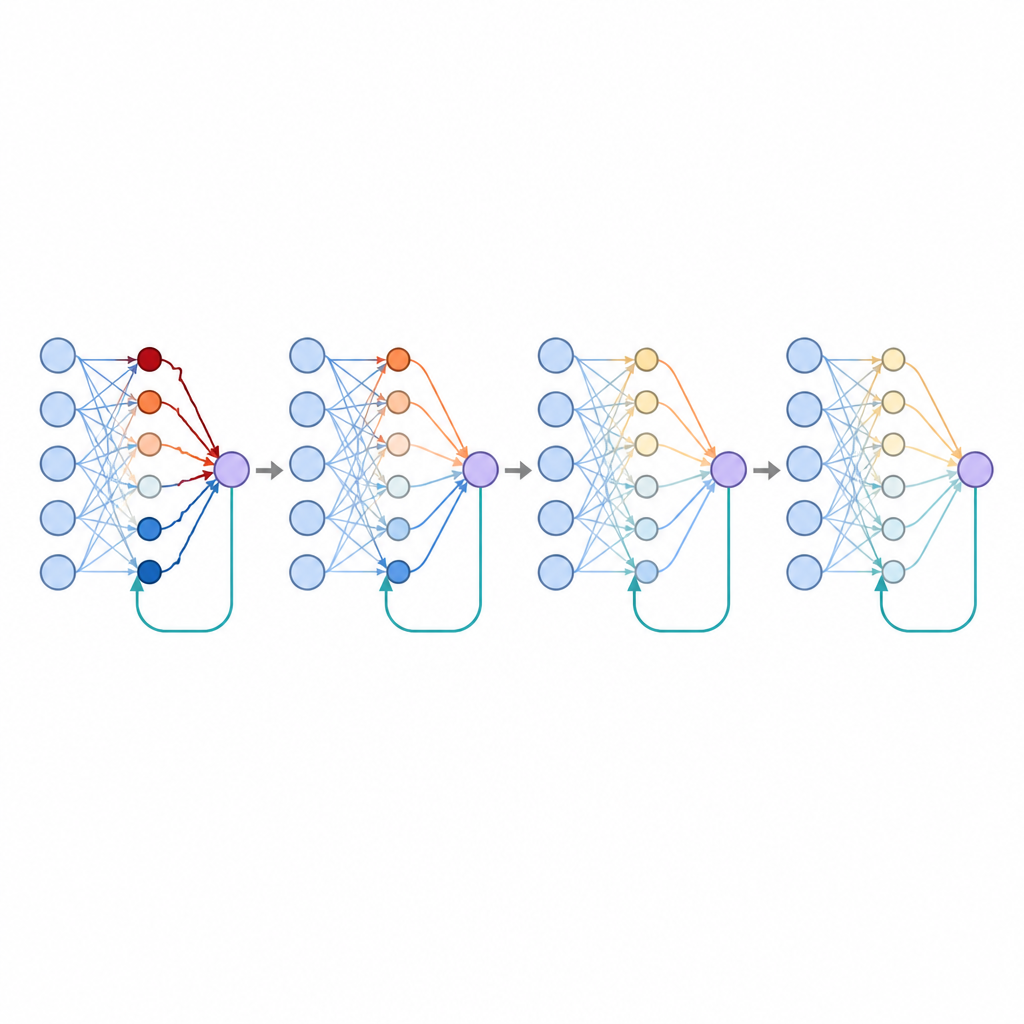
Warum die Trennung von positivem und negativem Feedback wichtig ist
Die Studie untersuchte außerdem, was passiert, wenn sich einige Verbindungen darauf spezialisieren, nur positive Fehler zu verfolgen, während andere nur negative erfassen — ähnlich dem unterschiedlichen Ansprechen bestimmter Gehirnzellen auf Belohnungen und Rückschläge. Diese Trennung erzeugte naturgemäß sparsere Konnektivitätsmuster, bei denen viele Verbindungen nahe Null blieben, während eine kleinere Teilmenge den Großteil des Einflusses übernahm. Solche Sparse-Strukturen verbessern bekanntermaßen die Generalisierung und senkten hier zusätzlich die Fehlerraten. Die Autoren zeigten, dass das erzwungene Verharren vieler Gewichte bei Null einen Großteil dieses Nutzens nachahmt, was darauf hindeutet, dass spezialisierte Rückkopplung ein biologischer Weg sein könnte, sparsame, effiziente Repräsentationen zu erreichen.
Was das für künftige Gehirne und Maschinen bedeutet
Insgesamt zeigt das iTDS-Rahmenwerk, dass ein lernenden Maschinen ein langsam veränderliches Bewusstsein für ihr eigenes jüngstes Verhalten zu geben sie zu schnelleren Lernern und stabileren Problemlösern machen kann. Anstatt sich ausschließlich auf die unmittelbare Abweichung von der korrekten Antwort zu stützen, kommen Netze, die schnelle Korrekturen mit sanfter Top-down-Stabilisierung kombinieren, besser mit Rauschen, Verwirrung und Veränderungen zurecht. Für die Hirnforschung liefert das Modell konkrete Vorhersagen darüber, wie Feedbackpfade das Lernen formen könnten. Für die künstliche Intelligenz legt es nahe, dass die Einbettung von Selbstüberwachungssignalen über mehrere Zeitskalen ein praktischer Weg sein könnte, Systeme zu bauen, die mehr wie wir lernen und seltener versagen, wenn die Welt unordentlich wird.
Zitation: Pilzak, A., Pennington, B. & Thivierge, JP. Intrinsic stabilization of synaptic plasticity improves learning and robustness in artificial neural networks. Nat Commun 17, 4164 (2026). https://doi.org/10.1038/s41467-026-70920-3
Schlüsselwörter: synaptische Plastizität, Top-down-Rückkopplung, rekurrente neuronale Netze, robustes Lernen, Rauschresistenz