Clear Sky Science · it
Stabilizzazione intrinseca della plasticità sinaptica migliora apprendimento e robustezza nelle reti neurali artificiali
Come il cervello ispira un apprendimento più stabile nelle macchine
Quando apprendiamo una nuova abilità, il nostro cervello rimane in qualche modo abbastanza flessibile da assimilare nuove informazioni ma anche sufficientemente stabile da non dimenticare ciò che già sappiamo. L’intelligenza artificiale moderna spesso fatica a mantenere questo equilibrio: apprende in fretta ma a volte diventa fragile o instabile. Questo studio prende ispirazione dai segnali di feedback cerebrali per progettare un nuovo modo con cui le reti neurali artificiali possono imparare in modo più efficiente restando robuste davanti a rumore, compiti che cambiano ed esempi fuorvianti.
Un nuovo segnale guida all’interno delle macchine che apprendono
La maggior parte dei sistemi di machine learning si basa su una ricetta semplice: confrontare la previsione della rete con la risposta corretta e aggiustare le connessioni per ridurre quella discrepanza. Questo approccio bottom-up funziona bene ma ignora i ricchi segnali top-down che attraversano i cervelli reali, portando aspettative, contesto e predizioni. Gli autori introducono un ingrediente aggiuntivo chiamato stabilizzazione top-down intrinseca (iTDS). Invece di inseguire solo la risposta corretta, la rete apprende anche un segnale interno più lento che segue il proprio output passato. Questo segnale, che cambia gradualmente, viene reimmesso nella regola di apprendimento, così ogni connessione viene plasmata non soltanto dall’errore esterno, ma anche da come la rete tende a comportarsi nel tempo.
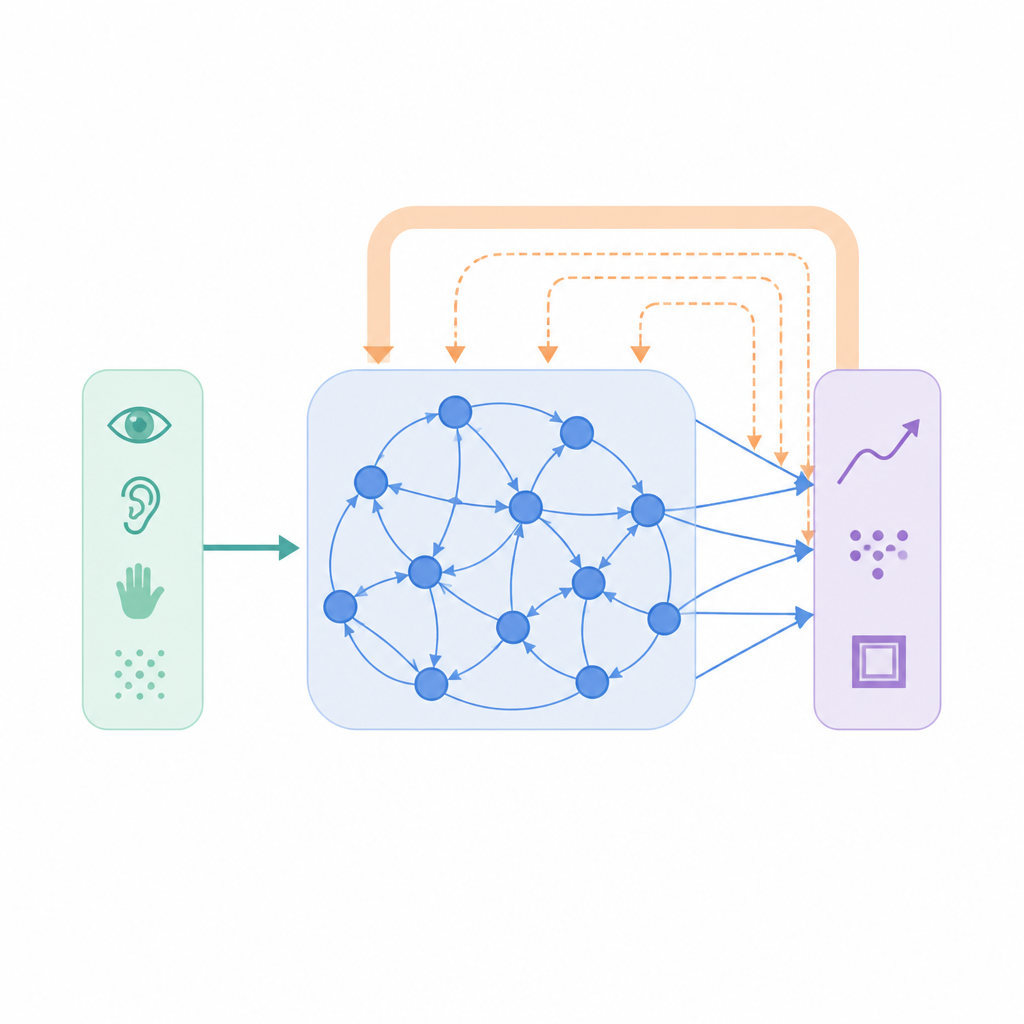
Insegnare alle reti a ricordare le proprie abitudini
In iTDS, la rete conserva un registro scorrevole e smussato della sua attività di output recente. Questa traccia interna non tenta di prevedere dati futuri o input sensoriali grezzi; diventa semplicemente un’eco filtrata di ciò che la rete ha già prodotto. Durante l’addestramento, il termine di errore usuale spinge le connessioni verso il bersaglio corretto, mentre il termine top-down confronta l’output attuale con questa eco. Quando l’attività della rete è molto variabile, queste due influenze tendono a puntare nella stessa direzione, rinforzandosi a vicenda e accelerando l’apprendimento. Con il progredire dell’addestramento e la stabilizzazione della rete in uno schema più coerente, l’influenza top-down si affievolisce gradualmente, agendo più come stabilizzatore che come motore del cambiamento.
Migliore tempistica, categorizzazione e gestione del caos
I ricercatori hanno testato iTDS in diversi tipi di reti neurali, incluse modelli ricorrenti, feedforward e reservoir, su sedici compiti. Questi andavano dal tracciamento di segnali fluidi nel tempo, al riconoscimento di cifre scritte a mano, alla risoluzione di semplici problemi logici. In molti casi, aggiungere iTDS ha portato a un addestramento più rapido e a un errore inferiore rispetto al solo apprendimento supervisionato standard, anche quando la dinamica sottostante della rete era caotica. Il metodo è risultato particolarmente efficace quando le reti avevano molte unità attive o quando i segnali di output fluttuavano intensamente, condizioni comuni sia in contesti biologici sia artificiali.
Imparare da esempi rumorosi e fuorvianti
I dati reali raramente sono puliti. Per testare la robustezza, gli autori hanno intenzionalmente aggiunto rumore agli input, ruotato le immagini lontano dalla loro orientazione abituale e persino introdotto “contro-prove” in cui esempi erano associati alla risposta sbagliata. In queste condizioni stressanti, le reti che usavano solo l’apprendimento standard tendevano a reagire eccessivamente, rimodellando le connessioni in modi poco utili. Con iTDS, il segnale top-down lento fungeva da freno: quando compariva un esempio sorprendente o contraddittorio, le due influenze di apprendimento si annullavano parzialmente, riducendo l’entità della variazione dei pesi. Di conseguenza, le reti con iTDS risultavano più resistenti sia alle distorsioni casuali sia alle perturbazioni scelte appositamente per ingannare i classificatori.
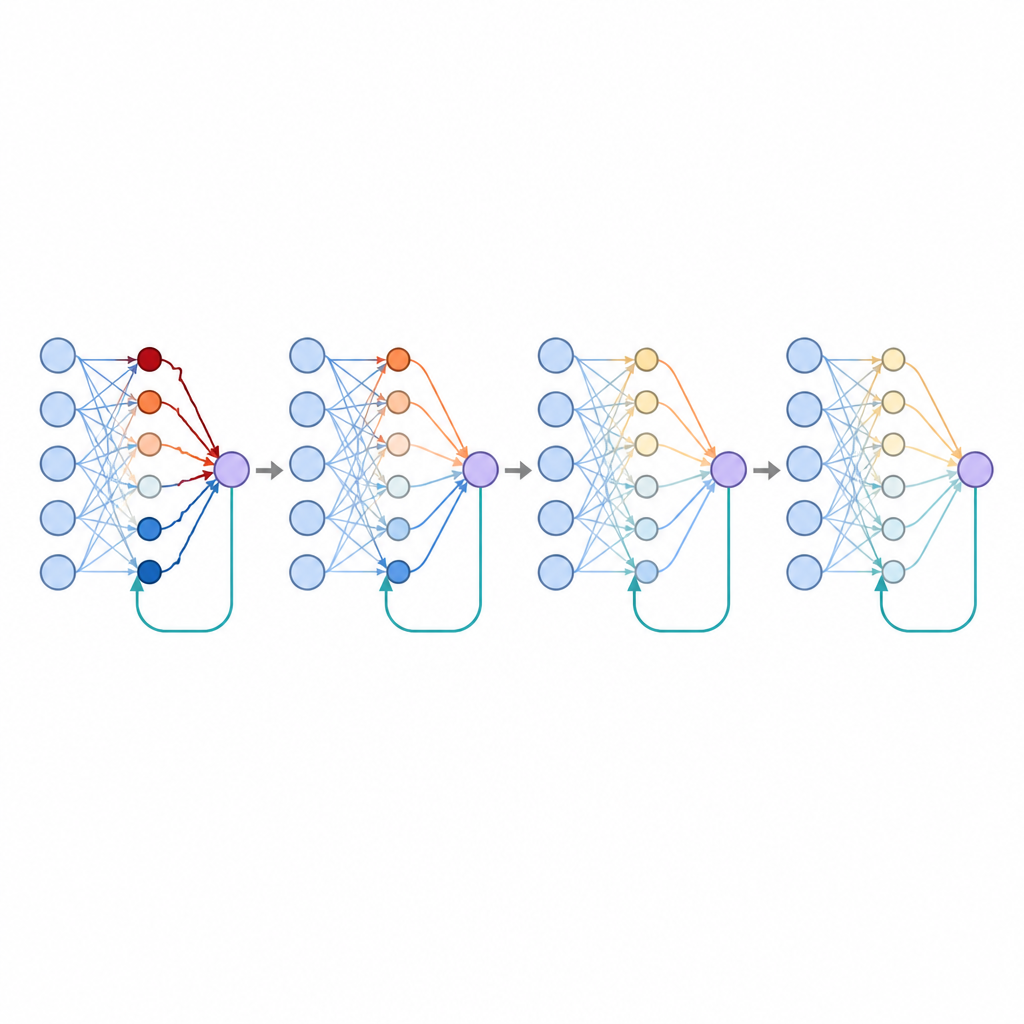
Perché separare feedback positivo e negativo conta
Lo studio ha anche esplorato cosa succede quando alcune connessioni si specializzano nel tracciare solo errori positivi e altre solo errori negativi, riecheggiando come certe cellule cerebrali rispondono diversamente a ricompense e insuccessi. Questa separazione ha prodotto naturalmente schemi di connettività più sparsi, in cui molte connessioni restavano vicine allo zero mentre una sottopopolazione più piccola portava la maggior parte dell’influenza. Tale sparseness è nota per migliorare la generalizzazione e qui riduceva ulteriormente i tassi di errore. Gli autori hanno mostrato che forzare semplicemente molti pesi a rimanere a zero imitava gran parte di questo beneficio, suggerendo che il feedback specializzato potrebbe essere una via biologica per ottenere rappresentazioni sparse ed efficienti.
Cosa significa per futuri cervelli e macchine
Complessivamente, il quadro iTDS mostra che dotare le macchine che apprendono di una percezione lentamente variabile del proprio comportamento recente può renderle apprendenti più rapide e risolutrici di problemi più stabili. Invece di fare affidamento esclusivamente sulla discrepanza immediata con la risposta corretta, le reti che bilanciano correzioni rapide con una gentile stabilizzazione top-down affrontano rumore, confusione e cambiamento in modo più efficace. Per le neuroscienze, il modello offre predizioni concrete su come i percorsi di feedback potrebbero plasmare l’apprendimento. Per l’intelligenza artificiale, suggerisce che integrare segnali di auto-monitoraggio su molteplici scale temporali potrebbe essere una strada pratica verso sistemi che imparano più come noi e falliscono meno quando il mondo diventa disordinato.
Citazione: Pilzak, A., Pennington, B. & Thivierge, JP. Intrinsic stabilization of synaptic plasticity improves learning and robustness in artificial neural networks. Nat Commun 17, 4164 (2026). https://doi.org/10.1038/s41467-026-70920-3
Parole chiave: plasticità sinaptica, feedback top-down, reti neurali ricorrenti, apprendimento robusto, resilienza al rumore