Clear Sky Science · sv
En ända-till-ända generaliserbar djupinlärningsram för att omfattande analysera transkriptionell reglering
Läsa DNA utan att köra varje laboratorietest
Modern biologi kräver ofta dussintals kostsamma laboratorieexperiment för att kartlägga hur våra gener styrs i varje celltyp. Denna studie visar hur en enda genomtänkt kombination av sekvenseringsdata och artificiell intelligens kan ersätta många av dessa tester, och erbjuda ett snabbare och billigare sätt att läsa genomets styrsystem.
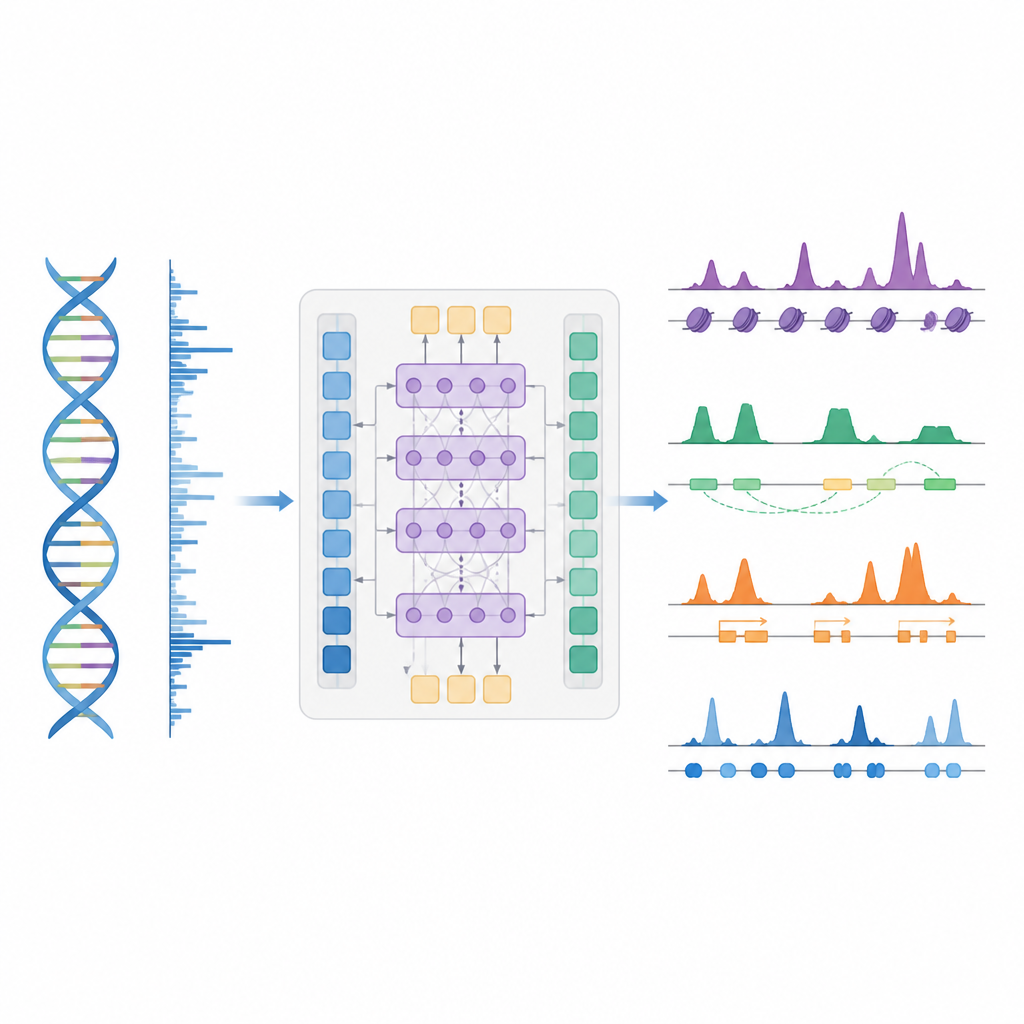
En smartare genväg för att kartlägga genkontroll
Författarna presenterar BioSeq2Seq, en djupinlärningsram utformad för att härleda många typer av regulatorisk information från genomet. Istället för att upprepa separata experiment för varje kemiskt märke eller protein lär sig BioSeq2Seq från två huvudinsatser. Den ena är själva DNA-sekvensen, som är densamma i nästan alla celler. Den andra är data från en run-on-sekvenseringsanalys som visar var RNA-polymeras aktivt rör sig längs DNA och i vilken riktning. Denna analys fångar ett levande ögonblick av vilka delar av genomet som används i en viss celltyp. Genom att kombinera dessa två källor kan modellen förutsäga ett brett spektrum av egenskaper som biologer vanligtvis mäter med separata experiment.
Hur modellen ser mönster i genomet
BioSeq2Seq bygger på en transformerarkitektur, en typ av neuralt nätverk som ursprungligen användes i språkmodeller. Här är “språket” sekvensen av baser i DNA plus mönstret av transkriptionssignaler längs kromosomen. Modellen konverterar först både DNA och run-on-signaler till numeriska funktioner och använder sedan attention-lager som kan koppla samman avlägsna platser över mer än 100 000 DNA-bokstäver. Denna långa vy är viktig eftersom kontroll-element som enhancers kan agera långt från de gener de reglerar. Ur dessa inlärda mönster ger modellen ut tätplacerade prediktioner längs genomet, såsom var aktiverande eller tystande märken på histonproteiner bör uppträda, var transkription startar eller slutar och var specifika proteiner tenderar att binda.
Testning över många celler, vävnader och arter
Forskarna tränade BioSeq2Seq främst på data från en mänsklig blodkancercellinje och utmanade den sedan i många andra kontexter. Dessa inkluderade flera mänskliga celltyper, mus- och hästlever samt bananflugaäggstock. För tio typer av histonmärken matchade modellens förutsägelser de experimentella mätningarna väl, särskilt för märken kopplade till aktiva gener. Den presterade också bra i regioner kring genstartplatser och inom promotorer och enhancers, där genkontroll är som mest intensiv. Jämfört med tidigare verktyg som använde enklare statistiska modeller eller färre datatyper förbättrade BioSeq2Seq noggrannheten för histonmärken med mer än 14 procent i genomsnitt och gjorde det betydligt snabbare, genom att förutsäga alla märken samtidigt istället för ett i taget.
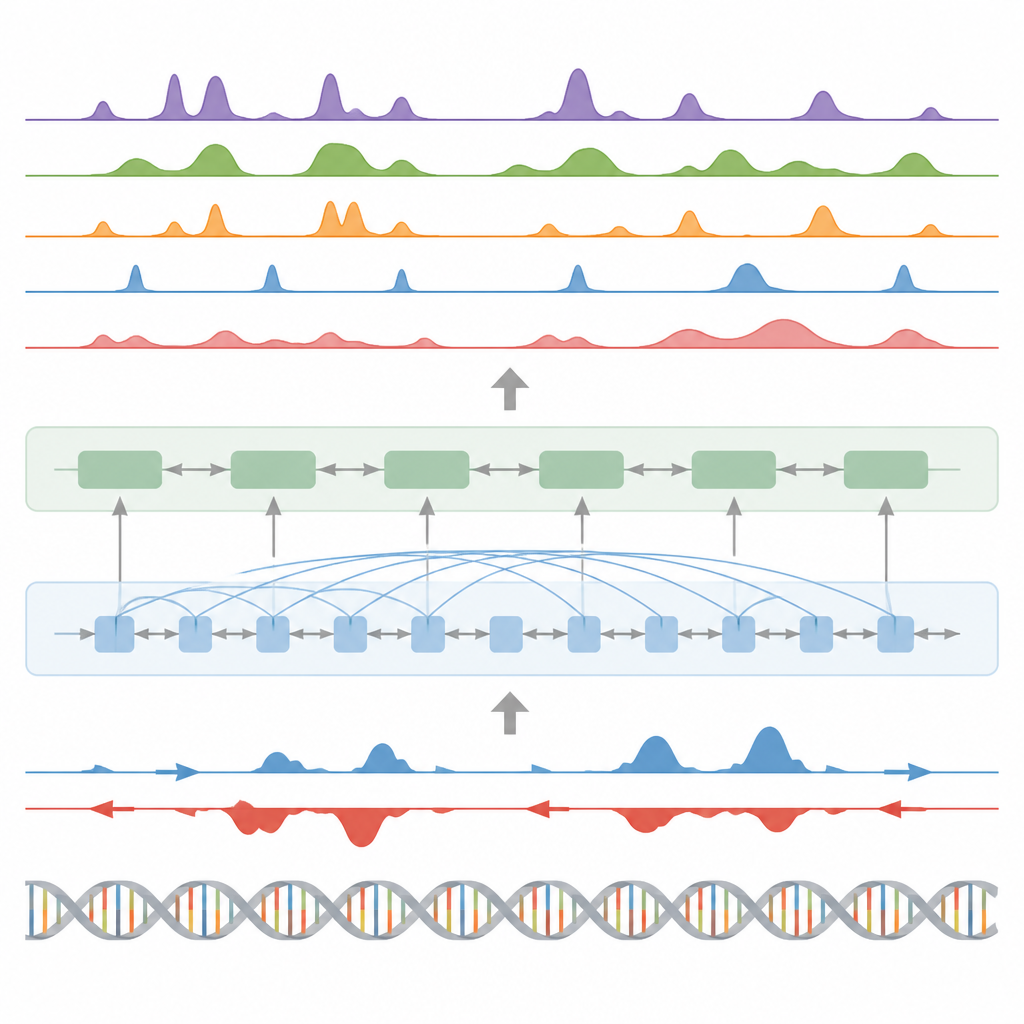
Hitta nyckelströmbrytare, genaktivitet och proteinfotavtryck
Utöver histonmärken testades modellen på tre andra större uppgifter. För det första identifierade den funktionella element såsom transkriptionsstartregioner, isolatorer, poly(A)-ställen och hela genkroppar genom att omvandla sina kontinuerliga signalprediktioner till toppar med en anpassad statistisk peak-caller. För startregioner och genkroppar uppnådde den höga resultat både för noggrannhet och återkallning och överträffade en välanvänd metod för att hitta aktiva regulatoriska platser. För det andra förutspådde BioSeq2Seq fullständiga genuttrycksprofiler, inte bara hög kontra låg, och en enkel klassificerare byggd på dess utsignaler slog flera ledande modeller som förlitar sig på många fler experimentella insatser. För det tredje, med samma ramverk, tränade författarna systemet att förutsäga bindningsställen för nittio olika transkriptionsfaktorer och nådde prestanda liknande en toppmetod som använder öppen-kromatin-data, och förbättrade till och med prestandan för de svåraste faktorerna samtidigt som de använde en enda delad modell.
Vad detta betyder för studiet av genom
Genom att lära sig hur DNA-sekvens och en enda transkriptionsanalys relaterar till flera lager av genkontroll erbjuder BioSeq2Seq ett praktiskt alternativ till att utföra dussintals separata experiment. Det gör det möjligt för forskare att härleda histonmärken, regulatoriska element, genaktivitet och proteinbindning i nya celltyper, vävnader och till och med arter där endast run-on-data och ett referensgenom finns tillgängliga. För en lekman är huvudbudskapet att ett noggrant valt experiment, kombinerat med ett kraftfullt inlärningssystem, nu kan ersätta en hel verktygslåda av kostsamma tester och göra storskaliga studier av genreglering tillgängliga för många fler laboratorier och biologiska frågor.
Citering: Zhang, Z., Fan, X., Zhong, J. et al. An end-to-end generalizable deep learning framework to comprehensively analyze transcriptional regulation. Nat Commun 17, 4708 (2026). https://doi.org/10.1038/s41467-026-70070-6
Nyckelord: genreglering, djupinlärning, genomannotering, transkription, epigenomik