Clear Sky Science · ja
転写制御を包括的に解析するエンドツーエンドで汎化可能な深層学習フレームワーク
すべての実験を行わずにDNAを読み解く
現代生物学では、各細胞型で遺伝子がどのように制御されているかをマップするために、多数のコストのかかる実験が必要になることが多い。本研究は、シーケンシングデータと人工知能をうまく組み合わせることで、それら多くの実験に代わる手法を示し、ゲノムの制御システムをより速く、より安価に読み取る方法を提示する。
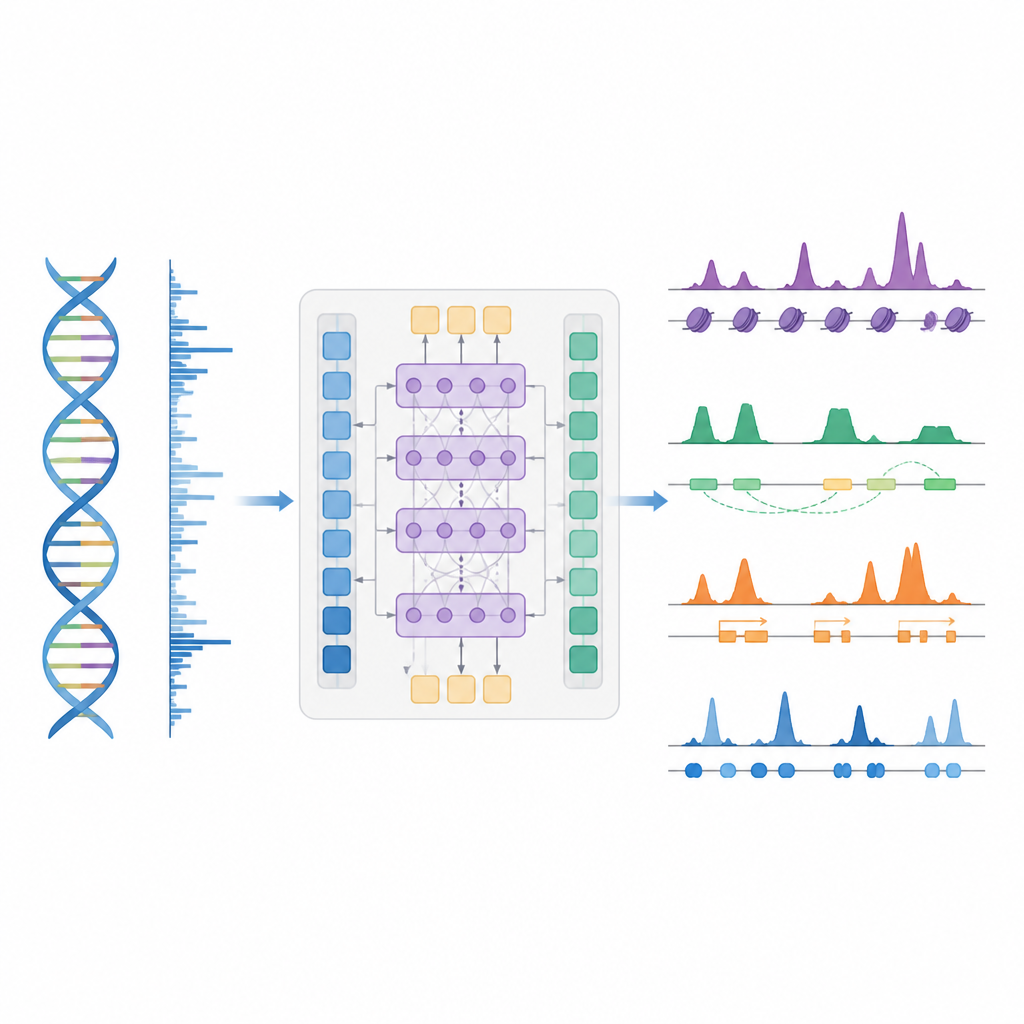
遺伝子制御をマップする賢いショートカット
著者らはBioSeq2Seqを導入する。これはゲノムから多種類の制御情報を推定するよう設計された深層学習フレームワークだ。個々の化学的ラベルやタンパク質ごとに別々の実験を繰り返す代わりに、BioSeq2Seqは主に二つの入力から学習する。一つはほとんどすべての細胞で同じであるDNA配列そのもの。もう一つは、RNAポリメラーゼがDNA上をどこで、どの向きに活発に動いているかを報告するランオン(run-on)シーケンシングアッセイのデータだ。このアッセイは特定の細胞型でゲノムのどの部分が利用されているかの生きたスナップショットを捉える。これら二つの情報源を組み合わせることで、モデルは生物学者が通常別々の実験で測定する多様な特徴を予測できる。
モデルがゲノムのパターンをどう見るか
BioSeq2Seqはトランスフォーマーアーキテクチャに依拠している。これは元々言語モデルに使われたニューラルネットワークだが、ここでの“言語”はDNAの塩基配列と染色体に沿った転写信号のパターンである。モデルはまずDNAとランオン信号の両方を数値的特徴に変換し、その後アテンション層を用いて10万塩基を超える遠方の部位を結びつけることができる。この長距離の視点は、エンハンサーのような制御要素が標的遺伝子から遠く離れて作用することがあるため重要だ。学習されたパターンから、モデルはヒストンタンパク質の活性化や抑制のタグが現れる場所、転写の開始や終了の位置、特定のタンパク質が結合しやすい部位など、ゲノムに沿った細かい間隔の予測を出力する。
多数の細胞、組織、種での検証
研究者たちはBioSeq2Seqを主に1つのヒト血液がん細胞株のデータで訓練し、次に多様な文脈で評価した。これには複数のヒト細胞型、マウスとウマの肝臓、ショウジョウバエの卵巣が含まれる。10種類のヒストン修飾にわたって、モデルの予測は実験測定とよく一致し、特に活性化された遺伝子に関連するマークで顕著だった。また、遺伝子開始部付近やプロモーター・エンハンサー領域でも高い性能を示し、遺伝子制御が最も活発なこれらの領域で優れた予測を行った。より単純な統計モデルや少ないデータタイプを用いた従来のツールと比べ、BioSeq2Seqはヒストンマークの精度を平均で14%以上改善し、しかも一度にすべてのマークを予測してより高速に処理できた。
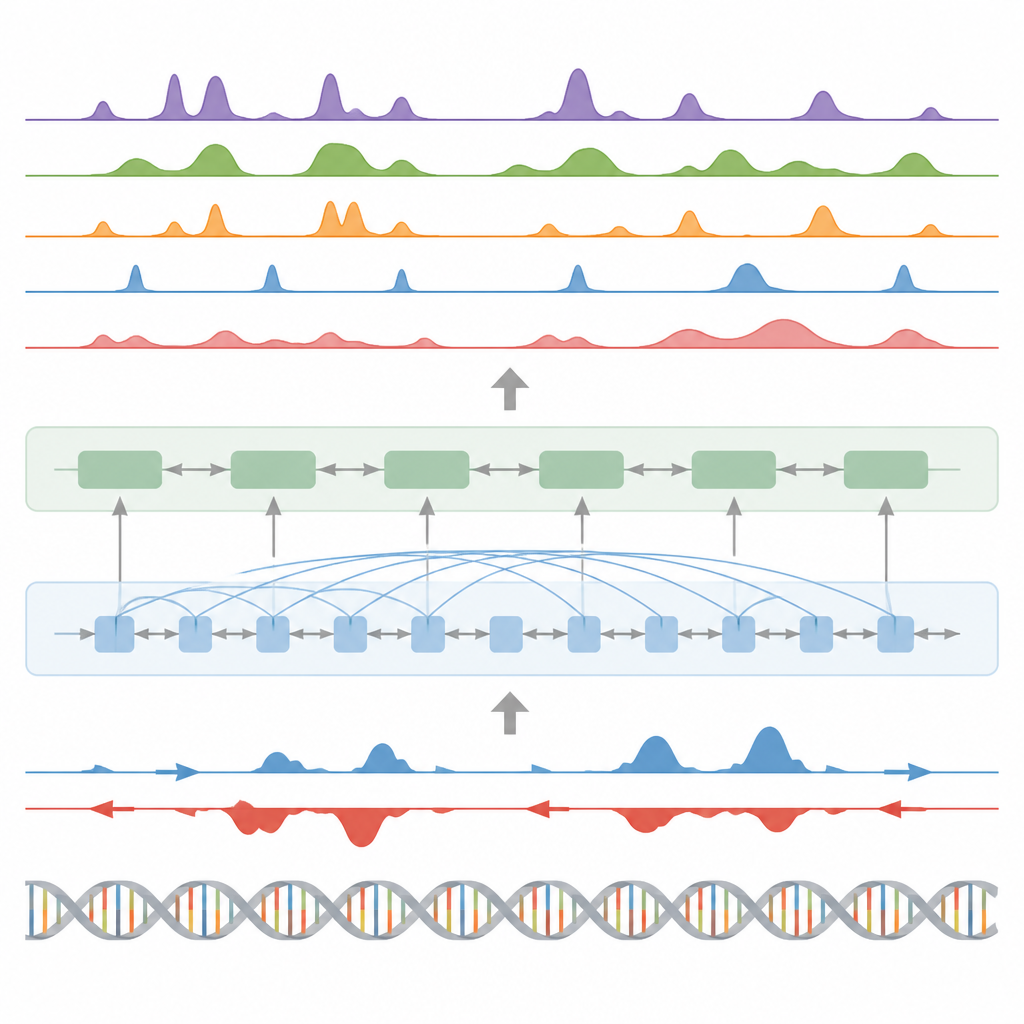
重要なスイッチ、遺伝子活動、タンパク質のフットプリントの発見
ヒストンマークに加え、モデルは三つの主要なタスクでもテストされた。第一に、モデルは連続的な信号予測をカスタムの統計的ピークコーラーでピークに変換することで、転写開始領域、インシュレーター、ポリ(A)部位、そして遺伝子本体などの機能要素を同定した。開始領域や遺伝子本体では、精度と再現率の両方で高いスコアを達成し、活性化された制御部位を見つける広く使われる手法を上回った。第二に、BioSeq2Seqは単なる高・低の二値ではなく完全な遺伝子発現プロファイルを予測し、その出力に基づくシンプルな分類器は、はるかに多くの実験入力に依存する既存の有力モデルを凌駕した。第三に、同じフレームワークを用いて九十種類の転写因子の結合部位を予測するよう学習させたところ、オープンクロマチンデータを用いる最先端の手法と同等の性能に達し、最も予測が難しい因子群では改善も示した。いずれも単一の共有モデルで実現した。
ゲノム研究にとっての意義
DNA配列と単一の転写アッセイが多層の遺伝子制御とどのように関連するかを学習することで、BioSeq2Seqは多数の別個の実験を行う実用的な代替手段を提供する。ランオンデータとリファレンスゲノムだけが得られる新しい細胞型、組織、あるいは他種に対しても、ヒストンマーク、制御要素、遺伝子活動、およびタンパク質結合を推定できる。一般読者にとっての要点は、注意深く選ばれた1つの実験と強力な学習システムの組み合わせが、コストのかかる多数の試験に代わり得るようになり、大規模な遺伝子制御の研究がより多くの研究室や生物学的課題にとって手の届くものになるということだ。
引用: Zhang, Z., Fan, X., Zhong, J. et al. An end-to-end generalizable deep learning framework to comprehensively analyze transcriptional regulation. Nat Commun 17, 4708 (2026). https://doi.org/10.1038/s41467-026-70070-6
キーワード: 遺伝子制御, 深層学習, ゲノム注釈, 転写, エピゲノム