Clear Sky Science · it
Un framework di deep learning end-to-end e generalizzabile per analizzare in modo completo la regolazione trascrizionale
Leggere il DNA senza eseguire ogni test di laboratorio
La biologia moderna spesso richiede dozzine di costosi esperimenti di laboratorio per mappare come i nostri geni sono controllati in ciascun tipo cellulare. Questo studio mostra come una singola combinazione intelligente di dati di sequenziamento e intelligenza artificiale possa sostituire molti di quei test, offrendo un modo più rapido ed economico per leggere il sistema di controllo del genoma.
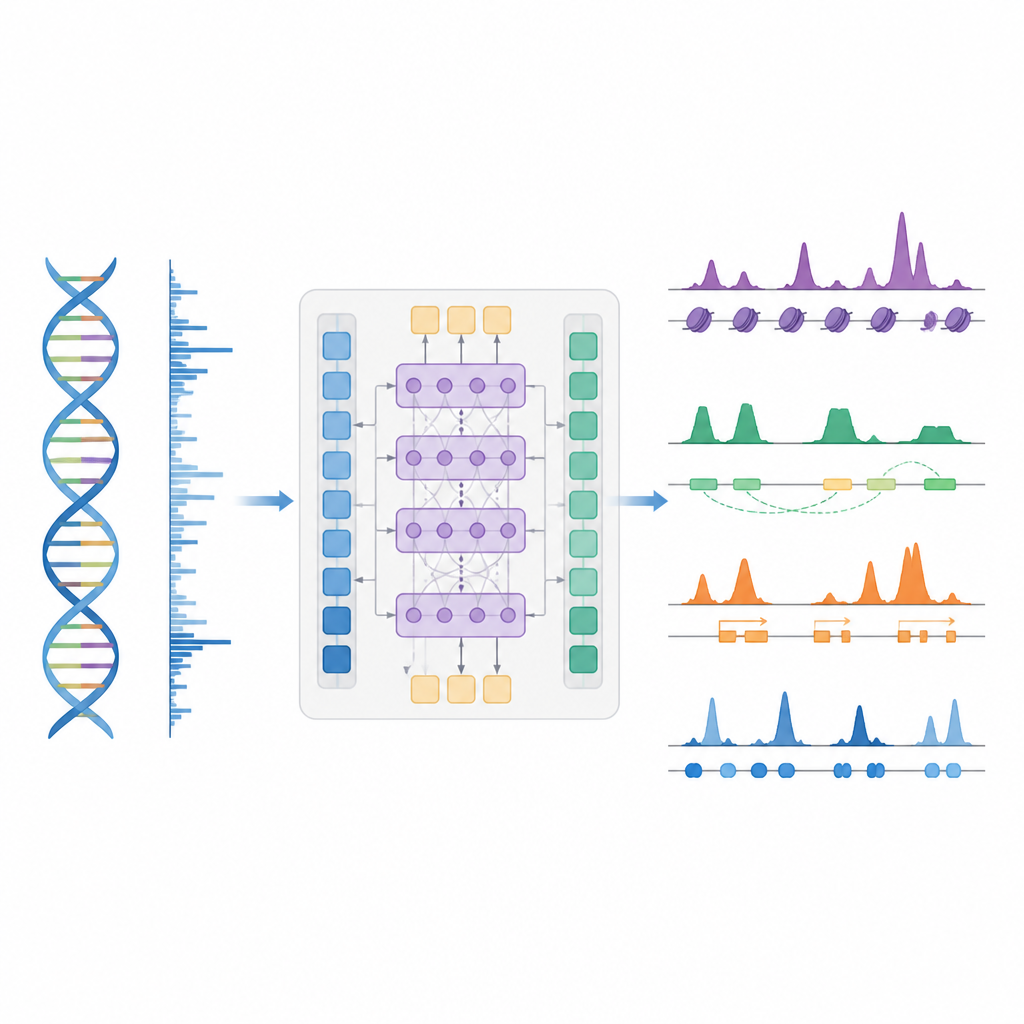
Una scorciatoia più intelligente per mappare il controllo genico
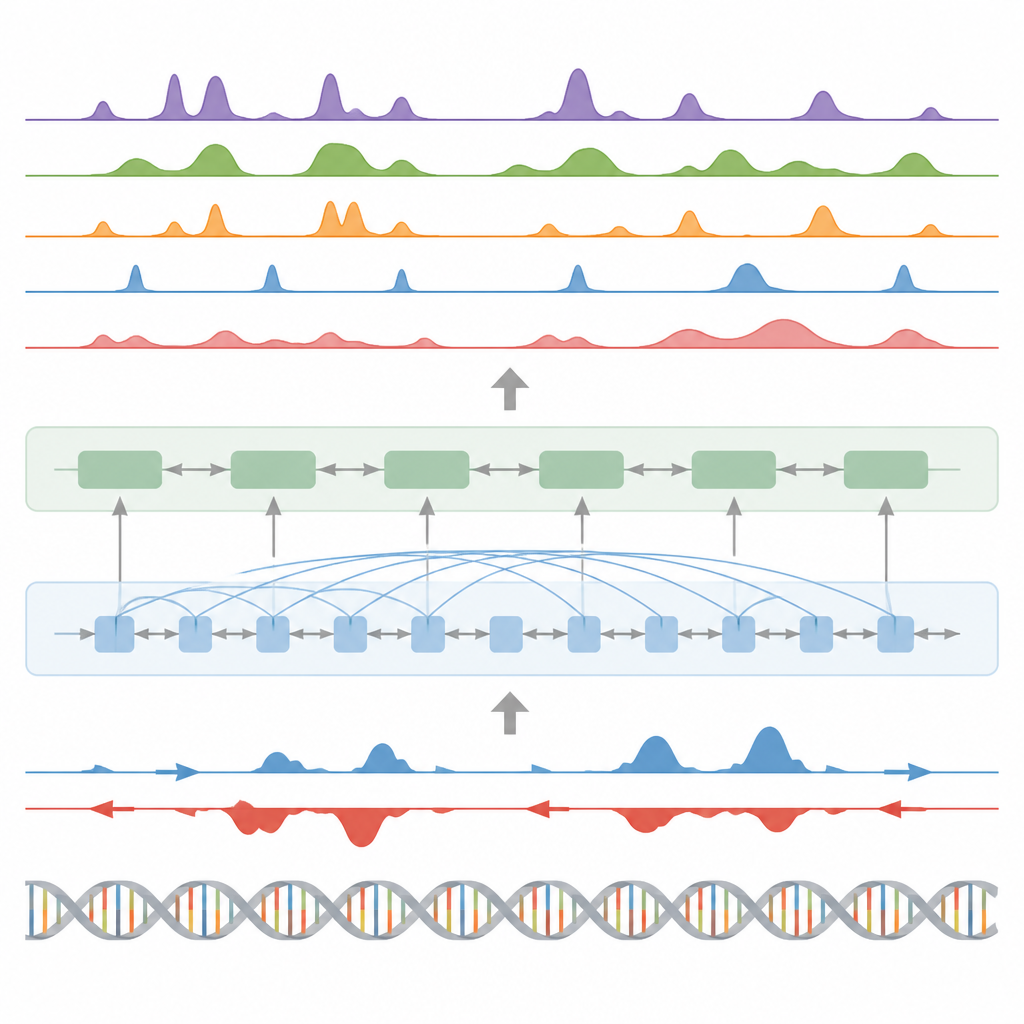
Gli autori presentano BioSeq2Seq, un framework di deep learning progettato per inferire molteplici tipi di informazioni regolatorie dal genoma. Invece di ripetere esperimenti separati per ogni marca chimica o proteina, BioSeq2Seq apprende da due input principali. Il primo è la sequenza del DNA stessa, che è la stessa in quasi tutte le cellule. Il secondo è costituito dai dati di un saggio di run-on sequencing che segnala dove la RNA polimerasi si muove attivamente lungo il DNA e in quale direzione. Questo saggio cattura un’istantanea «viva» delle parti del genoma utilizzate in un dato tipo cellulare. Combinando queste due fonti, il modello può prevedere una vasta gamma di caratteristiche che i biologi normalmente misurano con esperimenti separati.
Come il modello vede i pattern nel genoma
BioSeq2Seq si basa su un’architettura transformer, un tipo di rete neurale originariamente impiegata nei modelli linguistici. Qui la «lingua» è la sequenza di basi del DNA insieme al pattern dei segnali di trascrizione lungo il cromosoma. Il modello converte innanzitutto sia il DNA sia i segnali di run-on in caratteristiche numeriche e poi utilizza strati di attenzione che possono connettere siti distanti su più di 100.000 basi di DNA. Questa prospettiva a lungo raggio è importante perché elementi di controllo come gli enhancer possono agire lontano dai geni che regolano. Da questi pattern appresi, il modello produce previsioni finemente spaziate lungo il genoma, come dove dovrebbero apparire marchi istonici attivanti o silenzianti, dove inizia o termina la trascrizione e dove determinate proteine tendono a legarsi.
Test su molte cellule, tessuti e specie
I ricercatori hanno addestrato BioSeq2Seq principalmente su dati provenienti da una linea cellulare umana di cancro del sangue, quindi lo hanno messo alla prova in molti altri contesti. Questi includevano vari tipi cellulari umani, fegato di topo e di cavallo e ovaio della mosca della frutta. Su dieci tipi di marchi istonici, le previsioni del modello hanno rispecchiato da vicino le misurazioni sperimentali, specialmente per i marchi associati ai geni attivi. Ha inoltre performato bene nelle regioni attorno ai siti di inizio genico e all’interno di promotori ed enhancer, dove il controllo genico è più intenso. Rispetto ad strumenti precedenti che utilizzavano modelli statistici più semplici o meno tipi di dati, BioSeq2Seq ha migliorato l’accuratezza dei marchi istonici di oltre il 14 percento in media e lo ha fatto molto più rapidamente, prevedendo tutti i marchi contemporaneamente invece che uno alla volta.
Trovare interruttori chiave, attività genica e impronte proteiche
Oltre ai marchi istonici, il modello è stato testato su altri tre compiti principali. Primo, ha identificato elementi funzionali come regioni di inizio trascrizionale, isolatori, siti di poliadenilazione (poly(A)) e interi corpi genici trasformando le sue previsioni di segnale continuo in picchi mediante un rilevatore di picchi statistico personalizzato. Per le regioni di inizio e i corpi genici ha raggiunto punteggi elevati sia in accuratezza sia in richiamo, superando un metodo ampiamente usato per trovare siti regolatori attivi. Secondo, BioSeq2Seq ha previsto profili completi di espressione genica, non solo alto vs basso, e un semplice classificatore costruito sui suoi output ha battuto diversi modelli di punta che si basano su molti più input sperimentali. Terzo, utilizzando lo stesso framework, gli autori hanno addestrato il sistema a prevedere i siti di legame per novanta diversi fattori di trascrizione, raggiungendo prestazioni simili a un metodo leader che usa dati di cromatina aperta e migliorando persino sui fattori più difficili pur impiegando un singolo modello condiviso.
Cosa significa per lo studio dei genomi
Apprendendo come la sequenza del DNA e un singolo saggio di trascrizione si relazionano a molti strati di controllo genico, BioSeq2Seq offre un’alternativa pratica all’esecuzione di dozzine di esperimenti separati. Permette ai ricercatori di inferire marchi istonici, elementi regolatori, attività genica e legame proteico in nuovi tipi cellulari, tessuti e persino specie in cui sono disponibili solo dati di run-on e un genoma di riferimento. Per un lettore non specialista, il messaggio chiave è che un esperimento scelto con cura, combinato con un potente sistema di apprendimento, può ora sostituire un intero arsenale di test costosi, rendendo gli studi su larga scala della regolazione genica accessibili a molti più laboratori e a un più vasto insieme di domande biologiche.
Citazione: Zhang, Z., Fan, X., Zhong, J. et al. An end-to-end generalizable deep learning framework to comprehensively analyze transcriptional regulation. Nat Commun 17, 4708 (2026). https://doi.org/10.1038/s41467-026-70070-6
Parole chiave: regolazione genica, deep learning, annotazione del genoma, trascrizione, epigenomica