Clear Sky Science · ru
Конечная обобщаемая система глубокого обучения для всестороннего анализа транскрипционной регуляции
Чтение ДНК без запуска множества лабораторных тестов
Современная биология часто требует десятков дорогостоящих лабораторных экспериментов, чтобы составить карту управления генами в каждом типе клеток. В этом исследовании показано, как одна продуманная комбинация данных секвенирования и методов искусственного интеллекта может заменить многие из этих тестов, предложив более быстрый и экономичный способ «прочитать» систему управления геномом.
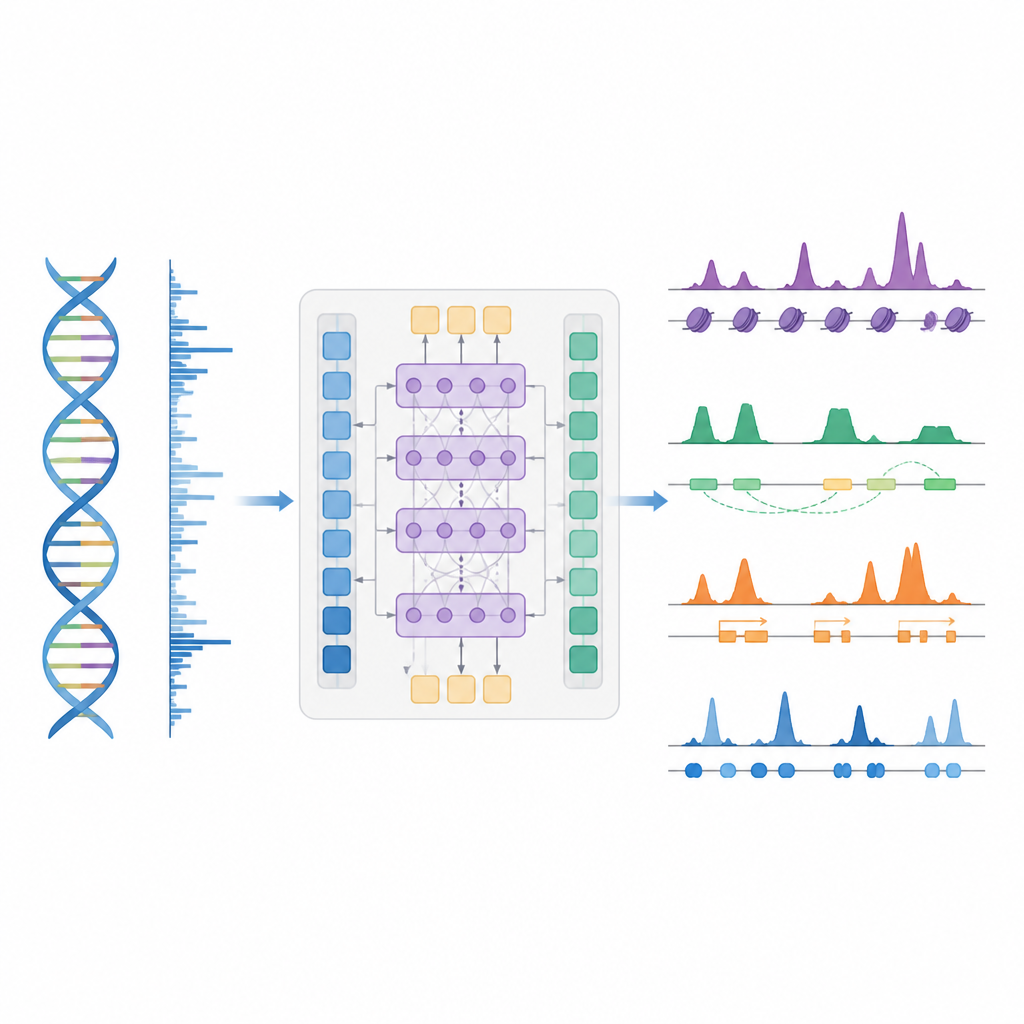
Более умный короткий путь для картирования управления генами
Авторы представляют BioSeq2Seq — систему глубокого обучения, разработанную для вывода множества типов регуляторной информации из генома. Вместо того чтобы повторять отдельные эксперименты для каждой химической метки или белка, BioSeq2Seq обучается на двух основных входах. Первый — сама последовательность ДНК, которая в основном одинакова во всех клетках. Второй — данные run-on секвенирования, которые показывают, где РНК-полимераза активно движется по ДНК и в каком направлении. Этот метод фиксирует моментальный снимок того, какие участки генома используются в конкретном типе клеток. Объединяя эти два источника, модель способна предсказывать широкий набор признаков, которые биологи обычно измеряют отдельными экспериментами.
Как модель видит закономерности в геноме
BioSeq2Seq опирается на архитектуру трансформера — тип нейронной сети, изначально использованный в языковых моделях. Здесь «язык» — это последовательность нуклеотидов ДНК вместе с шаблоном транскрипционных сигналов вдоль хромосомы. Модель сначала преобразует как ДНК, так и run-on сигналы в числовые признаки, а затем использует слои внимания, которые могут связывать удалённые участки на расстоянии более 100 000 букв ДНК. Такой широкий охват важен, потому что регуляторные элементы, например энхансеры, могут действовать далеко от регулируемых ими генов. На основе этих изученных закономерностей модель выдает детальные предсказания вдоль генома — например, где должны появиться активирующие или репрессирующие метки на гистонах, где начинается и останавливается транскрипция, и где склонны связываться определённые белки.
Тестирование в разных клетках, тканях и видах
Исследователи в основном обучали BioSeq2Seq на данных одной линии человеческой клеточной опухоли крови, а затем испытывали его в многочисленных других контекстах. Это включало несколько человеческих типов клеток, печень мыши и лошади, а также яичник плодовой мушки. По десятку типов гистоновых меток предсказания модели хорошо соответствовали экспериментальным измерениям, особенно для меток, связанных с активностью генов. Модель также показала высокую точность в регионах вокруг сайтов начала транскрипции и внутри промоторов и энхансеров, где регулирование генов наиболее интенсивно. По сравнению с ранними инструментами, которые использовали более простые статистические модели или меньше типов данных, BioSeq2Seq улучшил точность предсказания гистоновых меток в среднем более чем на 14 процентов и сделал это гораздо быстрее, предсказывая все метки одновременно вместо пошагового подхода.
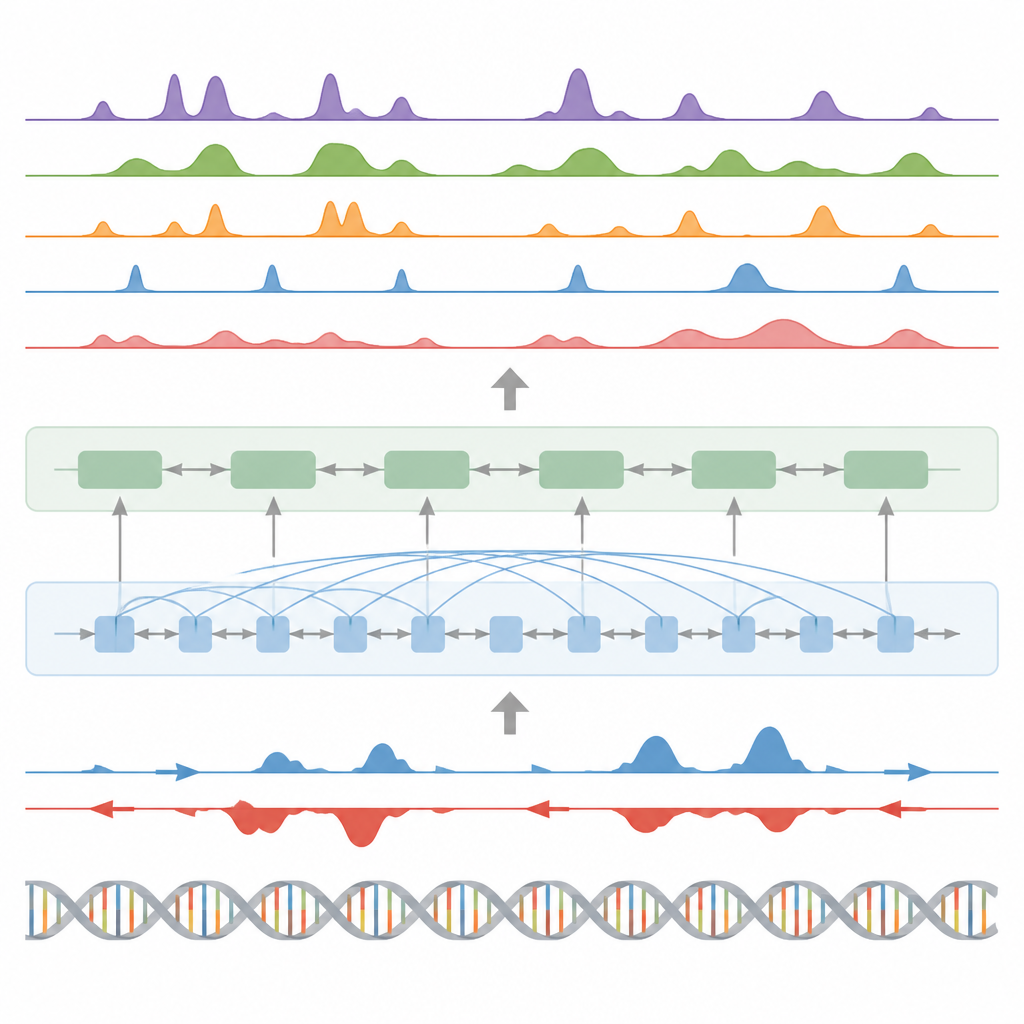
Нахождение ключевых переключателей, активности генов и следов белков
Кроме гистонов, модель проверяли на трёх других важных задачах. Во‑первых, она идентифицировала функциональные элементы — такие как регионы начала транскрипции, изоляторы, поли(А)-сайты и целые телa генов — превращая свои непрерывные сигналовые предсказания в пики с помощью специального статистического детектора пиков. Для регионов начала и тел генов модель достигла высоких показателей как по точности, так и по полноте, превзойдя широко используемый метод поиска активных регуляторных сайтов. Во‑вторых, BioSeq2Seq прогнозировал полные профили экспрессии генов, а не только высокий/низкий уровень, и простой классификатор, построенный на его выходах, обошёл несколько ведущих моделей, которые полагаются на значительно больше экспериментальных входов. В‑третьих, на той же базе авторы обучили систему предсказывать сайты связывания для девяноста разных транскрипционных факторов, достигнув производительности, сопоставимой с лучшим методом, использующим данные о доступности хроматина, и даже улучшив результаты для самых трудных факторов при использовании одной общей модели.
Что это значит для изучения геномов
Изучив взаимосвязь между последовательностью ДНК и одним экспериментом по транскрипции на множестве уровней управления генами, BioSeq2Seq предлагает практичную альтернативу проведению десятков отдельных экспериментов. Он позволяет исследователям выводить гистоновые метки, регуляторные элементы, активность генов и связывание белков в новых типах клеток, тканях и даже видах, где доступны только данные run-on и эталонный геном. Для неспециалиста ключевой вывод таков: один тщательно выбранный эксперимент в сочетании с мощной системой обучения теперь может заменить целый набор дорогостоящих тестов, делая масштабные исследования регуляции генов доступными для гораздо большего числа лабораторий и биологических задач.
Цитирование: Zhang, Z., Fan, X., Zhong, J. et al. An end-to-end generalizable deep learning framework to comprehensively analyze transcriptional regulation. Nat Commun 17, 4708 (2026). https://doi.org/10.1038/s41467-026-70070-6
Ключевые слова: регуляция генов, глубокое обучение, аннотация генома, транскрипция, эпигеномика