Clear Sky Science · ru
Генеративная объяснимая модель для предсказания антимикробных пептидов с использованием двунаправленной временной свёрточной нейронной сети
Борьба с инфекциями и раком с помощью «умных» пептидов
Лекарства, способные уничтожать опасные микробы и раковые клетки, не повреждая при этом здоровые ткани, давно являются мечтой медицины. Природа уже производит такие молекулы: антимикробные пептиды — небольшие фрагменты белков, которые проделывают отверстия в мембранах микроорганизмов и могут также модулировать иммунную систему. Но найти самые перспективные пептиды среди огромного множества возможных аминокислотных последовательностей — словно искать иглы в стоге сена. В этом исследовании представлена мощная рамочная модель искусственного интеллекта GAC-BiTCNN-AMP, которая обучается на больших биологических наборах данных и предсказывает, какие пептиды скорее всего будут эффективными антимикробными средствами и потенциальными противораковыми терапевтическими агентами.
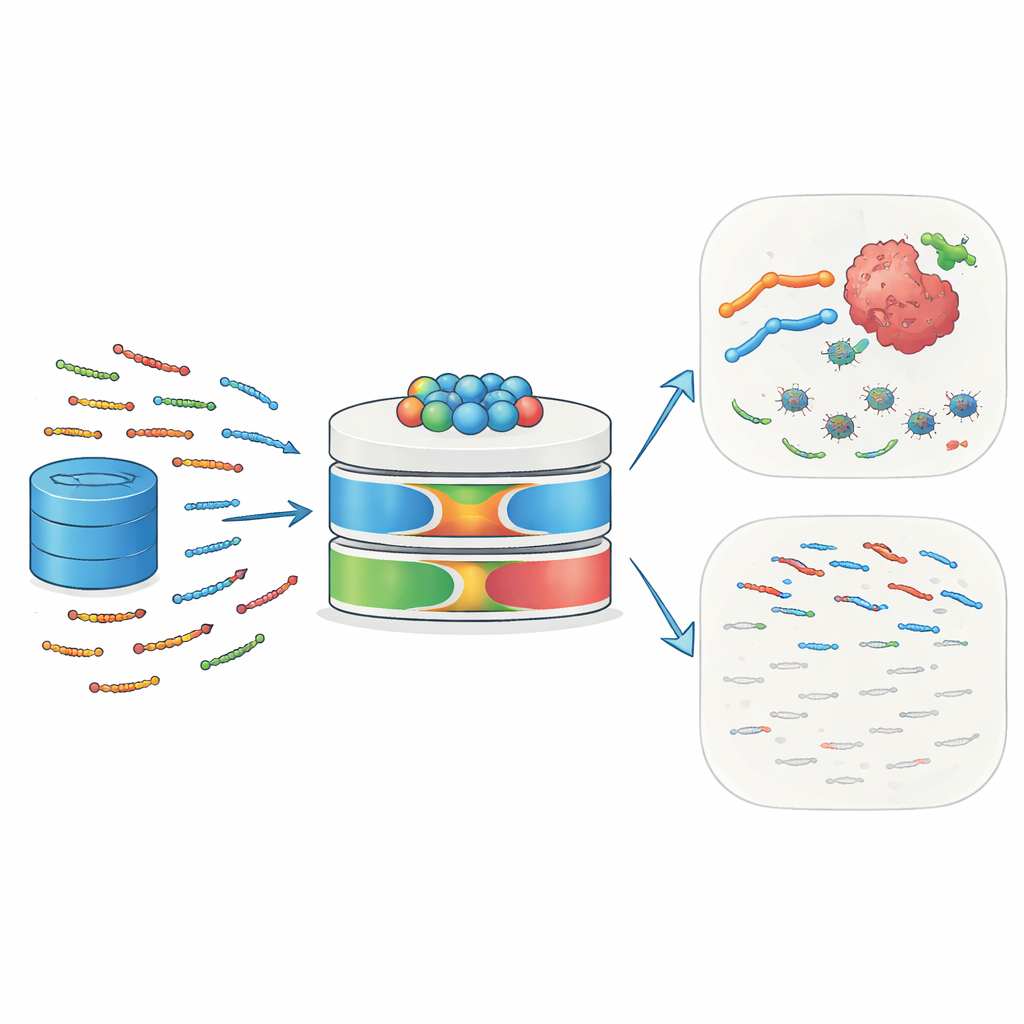
Крошечные телохранители природы
Антимикробные пептиды (AMP) — короткие цепочки из 10–50 аминокислот, встречающиеся у людей, животных, растений и микроорганизмов. Они действуют как первая линия защиты, связываясь с поверхностью микроорганизмов, нарушая их мембраны и вызывая гибель клеток. Многие AMP также привлекают клетки иммунной системы, влияют на воспаление и перестраивают локальную тканевую среду. Раковые клетки с их необычно заряженными и дезорганизованными мембранами особенно уязвимы к таким пептидам. Некоторые известные примеры — включая мелиттин и дефенсины — продемонстрировали способность убивать опухолевые клетки, повышать их чувствительность к химио‑ и радиотерапии и стимулировать иммунные ответы против опухолей. Эта двойная активность против инфекций и рака делает AMP привлекательными кандидатами для препаратов следующего поколения в прецизионной медицине.
Почему традиционные инструменты предсказания недостаточны
Несмотря на перспективность, in silico выявление новых AMP по‑прежнему сложно. Ранние компьютерные модели опирались преимущественно на простые последовательностные шаблоны и классические методы машинного обучения. Они часто игнорировали более богатую информацию о том, как аминокислоты взаимодействуют на дальних расстояниях в белке, как эти последовательности эволюционировали и какие тонкие физические свойства делают пептид одновременно активным и селективным. Многие модели использовали ограниченные или избыточные тренировочные данные, пропускали систематический отбор признаков и предлагали мало интерпретируемости — исследователи не могли легко понять, какие аспекты входа определяют предсказание. В результате их точность и способность обобщать на новые пептиды были ограничены, и они плохо захватывали разнообразные биологические роли AMP.
Построение более полного образа из последовательностей
Чтобы преодолеть эти пробелы, авторы сначала собрали большой, тщательно отфильтрованный набор данных из шести баз AMP и UniProt. Они чётко разделили активные пептиды от неактивных на основе строгих экспериментальных критериев и сократили избыточность, чтобы близкородственные последовательности не искажали результаты. Затем каждая последовательность пептида была преобразована в несколько комплементарных числовых представлений. Три передовые языковые модели для белков — ProtTrans‑T5, UniRep и ESM‑2 — использовались для получения высокоразмерных встраиваний, кодирующих контекст, дальнезависимые зависимости и эволюционные паттерны, извлечённые из миллионов белков. Пользовательский дескриптор PsePSSM‑DCT добавил сведения о том, как каждая позиция в последовательности склонна к мутациям в эволюции и как эти паттерны плавно изменяются вдоль последовательности. Этап отбора признаков на основе XGBoost затем сузил эти богатые представления до наиболее информативных компонент, убирая шум и сохраняя сигнал.
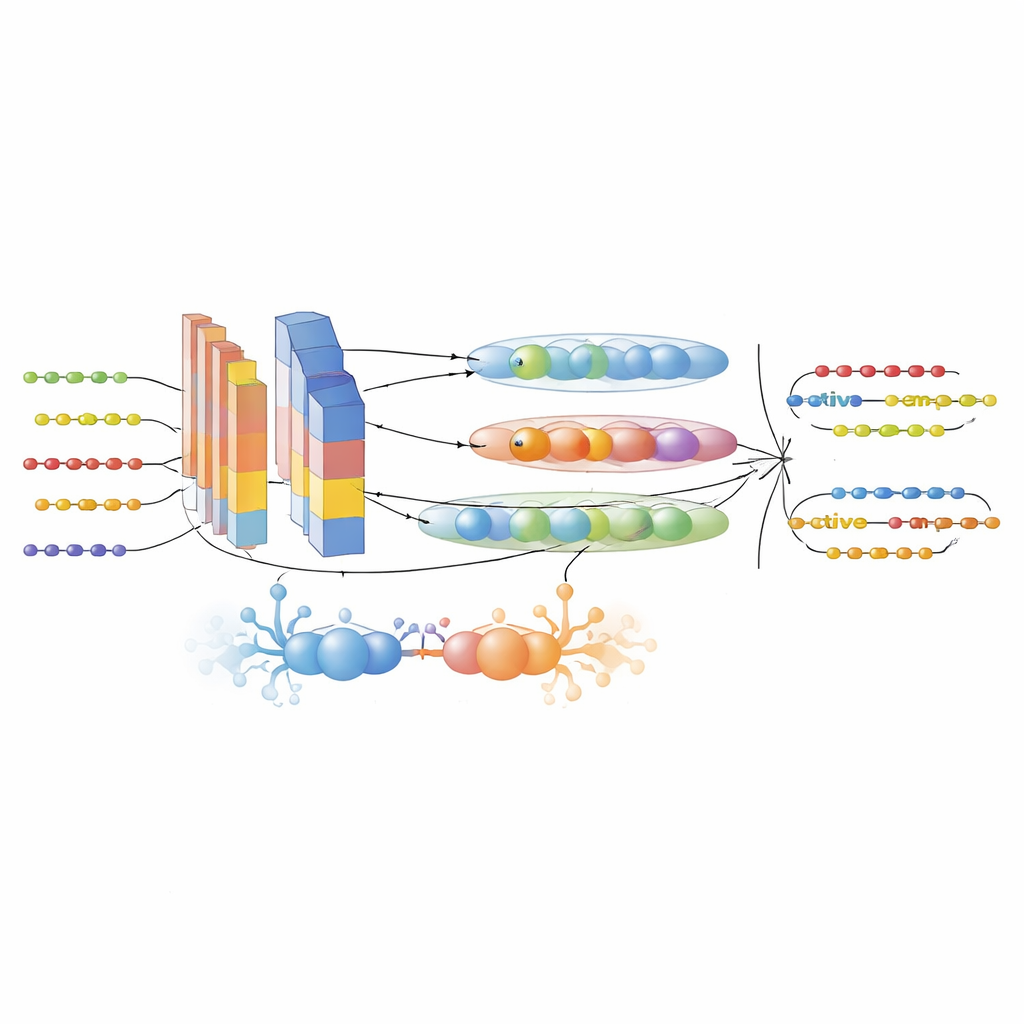
Гибридный ИИ‑движок для поиска пептидов
Сердцем фреймворка является модель GAC‑BiTCNN — гибридная архитектура глубокого обучения, специально адаптированная для последовательных данных. Она сочетает несколько идей: модуль генеративно‑соперничающей сети, создающий реалистичные синтетические векторы признаков для балансировки и обогащения обучающей выборки; свёрточные слои, обнаруживающие локальные мотивы; двунаправленную временную свёрточную сеть, фиксирующую паттерны, идущие вперед и назад вдоль последовательности; и капсульные сети, группирующие связанные признаки в небольшие векторные «капсулы» и сохраняя иерархические отношения. Каждый тип признаков — встраивания языковых моделей и эволюционные дескрипторы — обрабатывался в отдельном потоке и затем объединялся. Модель обучали и настраивали с помощью кросс‑валидации, а затем тестировали на полностью отдельном, разнесённом по времени наборе более новых записей о пептидах, чтобы минимизировать утечку информации.
Результаты, объяснимость и их значение
GAC‑BiTCNN‑AMP показала выдающиеся результаты: до примерно 97% точности и почти идеальные показатели площади под кривой при кросс‑валидации, а также более 95% точности на независимом тестовом наборе, превзойдя ряд существующих предикторов AMP и даже настроенные только трансформерные базовые модели. При комбинировании разных типов признаков результаты улучшались дополнительно, что говорит о том, что каждый источник вносит комплементарную информацию о поведении пептидов. Чтобы исследовать, чему модель научилась, авторы использовали SHAP — популярную технику объяснимого ИИ — для оценки влияния различных латентных признаков на предсказания. Хотя эти признаки абстрактны, анализ подтвердил, что модель опирается на компактный набор дискриминативных, биологически значимых паттернов, а не на случайный шум. Проще говоря, система, по-видимому, «смотрит» на правильные типы сигналов.
Что это означает для будущих препаратов
Для неспециалистов ключевой вывод таков: эта работа предоставляет высокоточный, основанный на данных фильтр для просеивания огромного числа пептидных последовательностей, чтобы отобрать те, которые с наибольшей вероятностью будут действовать как эффективные антимикробные или противораковые агенты. Сочетая генеративное моделирование, несколько языковых моделей белков и объяснимое глубокое обучение, GAC‑BiTCNN‑AMP предлагает масштабируемый способ приоритизации кандидатов для лабораторной проверки, что потенциально ускорит разработку новых средств против инфекций и опухолей, устойчивых к существующим терапиям. В будущем расширения могут не только предсказывать, какие пептиды работают, но и направлять дизайн совершенно новых последовательностей, оптимизированных по мощности, селективности и безопасности.
Цитирование: Ali, F., Khalid, M., Alsini, R. et al. A generative explainable model for antimicrobial peptide prediction using bidirectional temporal convolutional neural network. Sci Rep 16, 13801 (2026). https://doi.org/10.1038/s41598-026-43370-6
Ключевые слова: антимикробные пептиды, языковые модели белков, глубокое обучение, прецизионная онкология, поиск лекарств