Clear Sky Science · nl
Aminozuursamenstelling stuurt aggregatie tijdens peptidesynthese
Waarom kleine ketens belangrijk zijn voor grote geneesmiddelen
Veel moderne geneesmiddelen bestaan uit korte ketens van aminozuren, zogenaamde peptiden. Chemici bouwen deze ketens in de praktijk één bouwsteen per keer op kleine bolletjes, maar het proces stokt vaak omdat de groeiende ketens samenklonteren. Deze studie laat zien dat het niet zozeer de exacte volgorde van bouwstenen is die deze klontering bepaalt, maar hoeveel van elk type er in totaal aanwezig zijn. Met behulp van machine learning en gerichte experimenten tonen de auteurs welke aminozuren het sterkst aanzetten tot of juist tegen klontering werken, en hoe die kennis gebruikt kan worden om moeilijk-syntheseerbare peptiden veel efficiënter te maken.
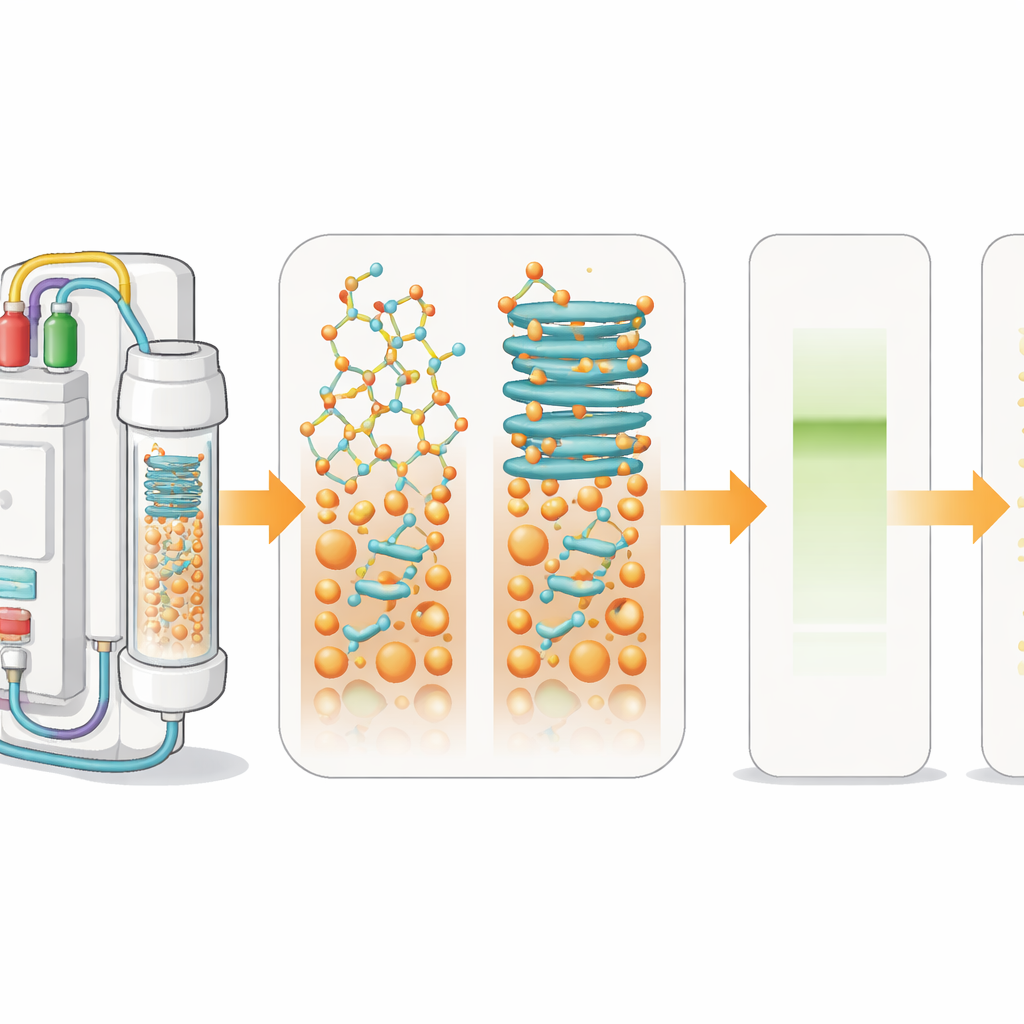
Hoe peptiden als geneesmiddelen aan elkaar worden gezet
Om peptiden in het laboratorium te maken, gebruiken chemici een methode die vastfase-peptidesynthese heet. Het eerste aminozuur wordt aan een onoplosbaar bolletje gebonden, waarna extra aminozuren in cycli worden toegevoegd, als kralen die aan een armband worden geklikt. Bij elke stap wordt een beschermgroep verwijderd en een nieuw onderdeel gekoppeld. Een ingebouwde lichtdetector volgt deze stappen realtime door de grootte en vorm van signalen te meten die ontstaan wanneer beschermgroepen worden verwijderd. Wanneer de groeiende ketens op de bolletjes beginnen samen te plakken en in bladvormige structuren vouwen, worden die signalen verbreed. Deze “aggregatie” vertraagt de reacties en leidt tot mengsels van foutieve producten in plaats van één zuiver peptide.
Data laten spreken voor duizenden synthesen
De onderzoekers combineerden twee grote datasets van geautomatiseerde flow-gebaseerde peptidesynthesen, in totaal meer dan 500 unieke sequenties. Voor elke stap in elke synthese beschikten ze zowel over het toegevoegde aminozuur als over een kwantitatieve maat voor hoeveel aggregatie optrad, afgeleid uit de lichtgebaseerde signalen. Vervolgens pasten ze een breed scala aan machine-learningbenaderingen toe—van moderne modeltypen die aminozuurreeksen als tekst lezen tot klassieke statistische modellen en tijdreeksmethoden die een synthese behandelen als een opeenvolging van gebeurtenissen—om een eenvoudige ja–nee vraag te beantwoorden: aggregateert een gegeven peptide onder de geteste condities?
Een verrassende verschuiving van volgorde naar ingrediënten
Bij al deze methoden bleef de voorspellingsnauwkeurigheid ongeveer op hetzelfde bescheiden niveau, ongeacht hoe inventief de aminozuurvolgorde werd gecodeerd. Dat leidde tot een cruciale test. Het team schudde willekeurig de volgorde van aminozuren in elke peptide door elkaar, maar hield de totale tellingen van elk type gelijk. Als precieze volgorde cruciaal was geweest, had de prestatie moeten instorten. Dat gebeurde niet: de modellen presteerden net zo goed op de geschudde sequenties. Zelfs wanneer elke peptide werd teruggebracht tot een 20‑dimensionale “compositievector” die simpelweg het aandeel van elk aminozuur vastlegt, bleef de nauwkeurigheid vergelijkbaar. Om dit experimenteel te bevestigen, namen de auteurs acht bekende peptiden—vier die aggregeerden en vier die dat niet deden—en synthetiseerden ze vijf geschudde varianten van elk. De meeste geschudde varianten gedroegen zich als de originelen: aggregerende sequenties aggregeerden nog steeds, en niet-aggregerende bleven grotendeels oplosbaar, en ze begonnen vaak op vergelijkbare posities langs de keten te aggregeren.
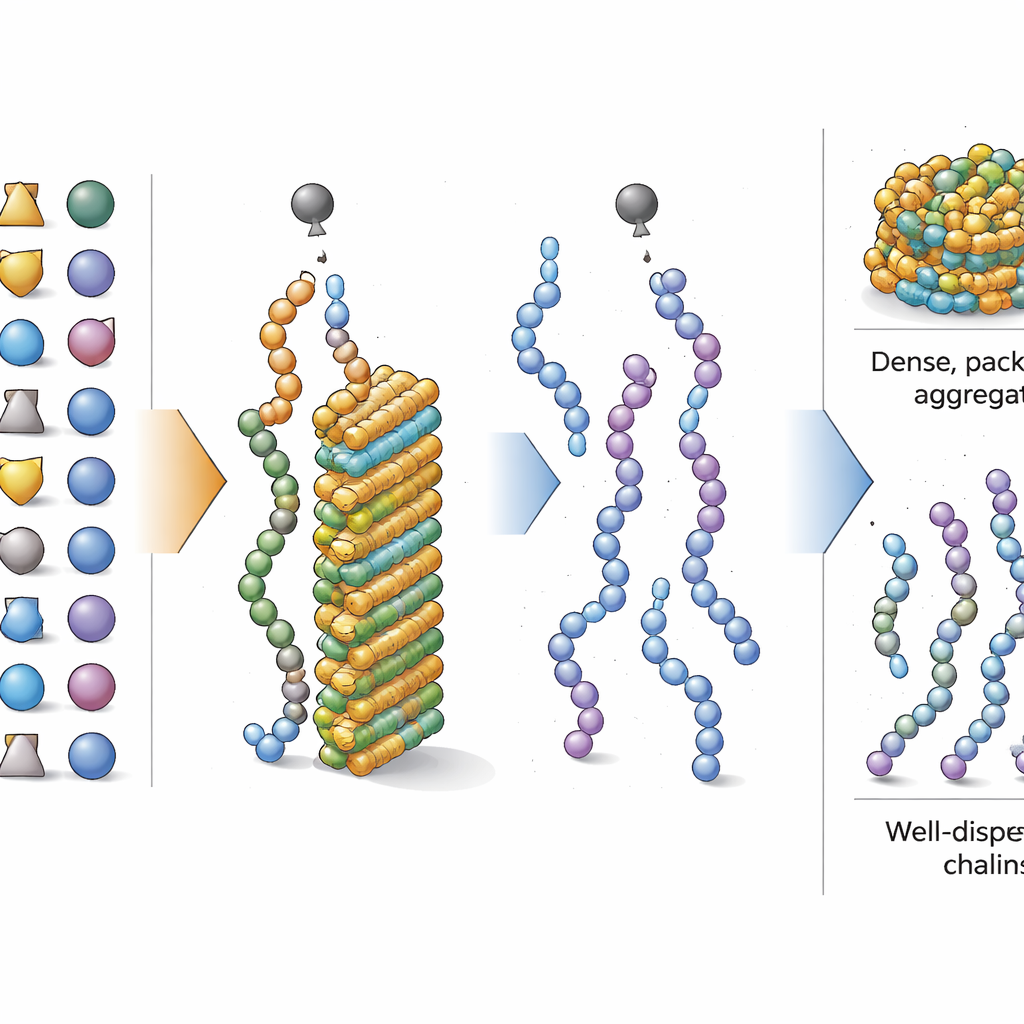
Goede en slechte spelers onder aminozuren
Met de focus verlegd naar de algehele samenstelling vroegen de onderzoekers vervolgens welke aminozuren een peptide tijdens de synthese het meest richting wel of geen aggregatie duwen. Met een interpreteerbare machine-learningtool beoordeelden ze hoe het verhogen van het aandeel van elk aminozuur de voorspelling van het model beïnvloedde. Ze vonden dat bouwstenen met eenvoudige, olieachtige zijketens—zoals isoleucine en valine, evenals vaak gebruikte beschermde vormen van serine en threonine—sterk de aggregatie bevorderen wanneer ze in hoge hoeveelheden aanwezig zijn. Daarentegen leken aminozuren met grotere of complexere zijketens, inclusief beschermde vormen van fenylalanine, tyrosine, asparaginezuur en arginine, aggregatie te verminderen. Bepaalde korte twee‑aminozuurpatronen, zoals glycine–serine en leucine–leucine, toonden ook extra neigingen tot samenklonteren, maar de algehele balans van aminozuurtypes bleef de dominante factor.
Inzichten omzetten in betere syntheserecepten
Gewapend met deze kaart van “klonterende” en “ontklonterende” aminozuren bouwde het team een ensemble van modellen dat praktische oplossingen kan voorstellen voordat een synthese wordt uitgevoerd. Voor een voorgesteld peptide voorspelt het programma of aggregatie waarschijnlijk is en identificeert het posities dicht bij het verankerde uiteinde van de keten waar probleemaminozuren het meest bijdragen. Het raadt vervolgens aan deze te vervangen door speciale varianten, zoals pseudoproline‑bouwstenen, die de aggregatie tijdelijk verstoren maar na de laatste deprotectiestap terugkeren naar de gewenste aminozuren. Het testen van deze strategie op twee berucht lastige peptidefragmenten leverde, na het introduceren van een klein aantal zulke substituties op model‑gekozen posities, een dramatische stijging in ruwe zuiverheid op—van ruwweg een vijfde naar ongeveer driekwart van het productmengsel—in overeenstemming met de rangschikking van het model over welke posities het meest zouden helpen.
Wat dit betekent voor toekomstige peptide‑geneesmiddelen
Voor een niet‑specialist is de kernboodschap dat, onder deze synthetische condities, peptideklontering zich minder gedraagt als een fijnmazig slot‑en‑sleutelpatroon en meer als een probleem van bulkreceptuur: de verhoudingen van de “olieachtige” en “ruigere/bulkere” ingrediënten wegen zwaarder dan hun exacte volgorde. Door dit te herkennen en te kwantificeren konden de auteurs zowel langdurige synthese‑fouten verklaren als een eenvoudige, data‑gedreven manier bieden om ze te vermijden. Hun werk toont hoe machine learning verborgen regels in chemische processen kan onthullen en omzetten in heldere ontwerpinstrumenten, waarmee het pad van peptide‑ideeën naar betrouwbare, opschaalbare geneesmiddelen wordt versneld.
Bronvermelding: Tamás, B., Alberts, M., Laino, T. et al. Amino acid composition drives aggregation during peptide synthesis. Nat. Chem. 18, 677–685 (2026). https://doi.org/10.1038/s41557-026-02090-0
Trefwoorden: peptidesynthese, aminozuursamenstelling, aggregatie, machine learning, vastfasechemie