Clear Sky Science · de
Aminosäurezusammensetzung treibt Aggregation während der Peptidsynthese
Warum winzige Ketten für große Medikamente wichtig sind
Viele moderne Medikamente sind kurze Aminosäureketten, sogenannte Peptide. Chemiker bauen diese Ketten Baustein für Baustein auf winzigen Kügelchen auf, doch der Prozess stockt oft, weil die wachsenden Ketten verkleben. Diese Studie zeigt, dass nicht die exakte Reihenfolge der Bausteine vorwiegend diese Verklebung bestimmt, sondern die Gesamtanzahl der einzelnen Typen. Mit Hilfe von maschinellem Lernen und gezielten Experimenten identifizieren die Autoren, welche Aminosäuren stark zu Aggregation beitragen oder diese verhindern, und zeigen, wie dieses Wissen genutzt werden kann, um schwer zu synthetisierende Peptide deutlich effizienter herzustellen.
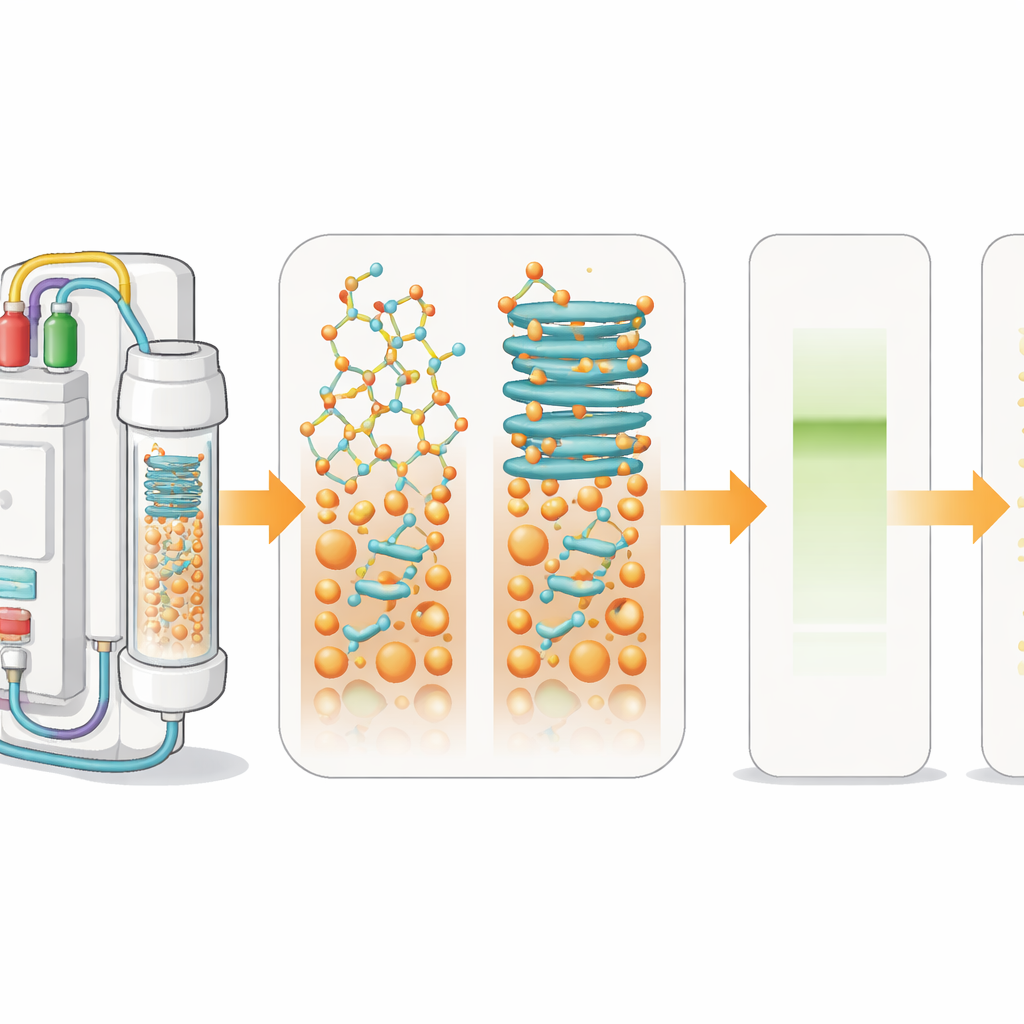
Wie Peptidmedikamente zusammengesetzt werden
Im Labor stellen Chemiker Peptide mit der sogenannten Festphasen-Peptidsynthese her. Die erste Aminosäure wird an ein unlösliches Kügelchen gebunden, dann werden in Zyklen weitere Aminosäuren hinzugefügt, ähnlich wie Perlen auf einer Schnur. In jedem Schritt wird eine Schutzgruppe entfernt und eine neue Einheit gekoppelt. Ein eingebauter Lichtsensor verfolgt diese Schritte in Echtzeit, indem er Größe und Form der Signale misst, die beim Entfernen der Schutzgruppen entstehen. Wenn die wachsenden Ketten auf den Kügelchen zu verklumpen beginnen und sich blattartige Strukturen falten, werden die Signale breiter. Diese „Aggregation“ verlangsamt die Reaktionen und führt zu Gemischen fehlerhafter Produkte statt zu einem sauberen Einzelpeptid.
Daten sprechen für Tausende von Synthesen
Die Forschenden kombinierten zwei große Datensätze automatisierter, strömungsbasierter Peptidsynthesen mit insgesamt mehr als 500 einzigartigen Sequenzen. Für jeden Schritt jeder Synthese lagen ihnen sowohl die jeweils hinzugefügte Aminosäure als auch eine quantitative Messgröße vor, wie stark die Aggregation war, extrahiert aus den lichtbasierten Signalen. Sie wandten dann eine breite Palette von Methoden des maschinellen Lernens an — von modernen, sprachmodellähnlichen Modellen, die Aminosäurekettentexte wie Sprache lesen, bis zu klassischen statistischen Modellen und Zeitreihenmethoden, die eine Synthese als Folge von Ereignissen behandeln — um eine einfache Ja‑/Nein‑Frage zu beantworten: aggregiert ein gegebenes Peptid unter den getesteten Bedingungen?
Eine überraschende Verschiebung von Ordnung zu Zutaten
Über all diese Methoden hinweg lag die Vorhersagegenauigkeit auf einem ähnlichen, moderaten Niveau, unabhängig davon, wie raffiniert die Reihenfolge der Aminosäuren kodiert wurde. Das führte zu einem entscheidenden Test. Das Team mischte zufällig die Reihenfolge der Aminosäuren in jedem Peptid, behielt aber die Gesamtanzahl jeder Aminosäure bei. Wenn die genaue Reihenfolge entscheidend wäre, hätte die Leistung stark einbrechen müssen. Das tat sie nicht: Die Modelle schnitten bei den gemischten Sequenzen genauso gut ab. Selbst wenn jedes Peptid auf einen 20‑Zahlen‑„Zusammensetzungsvektor“ reduziert wurde, der einfach den Anteil jeder Aminosäure erfasst, blieb die Genauigkeit ähnlich. Um dies experimentell zu bestätigen, wählten die Autoren acht bekannte Peptide — vier aggregierende und vier nicht aggregierende — und synthetisierten jeweils fünf gemischte Varianten. Die meisten gemischten Varianten verhielten sich wie die Originale: aggregierende Sequenzen aggregierten weiterhin, nicht aggregierende blieben weitgehend löslich, und sie begannen tendenziell an ähnlichen Positionen entlang der Kette zu verklumpen.
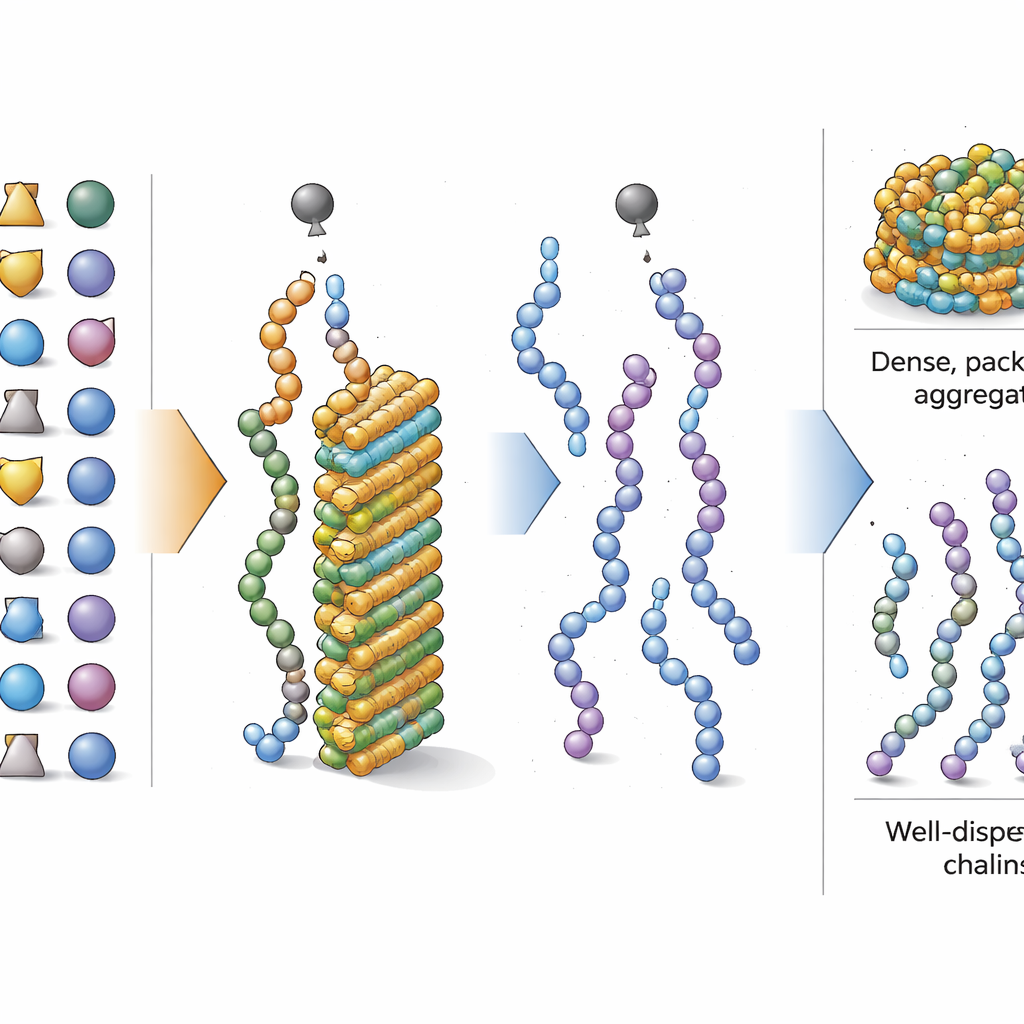
Gute und schlechte Akteure unter den Aminosäuren
Mit dem Fokus auf die Gesamtzusammensetzung fragten die Forschenden als Nächstes, welche Aminosäuren ein Peptid während der Synthese besonders stark in Richtung Aggregation oder Löslichkeit kippen. Mit einem interpretierbaren Werkzeug des maschinellen Lernens bewerteten sie, wie sehr eine Erhöhung des Anteils jeder Aminosäure die Vorhersage des Modells verändert. Sie fanden heraus, dass Bausteine mit einfachen, öligen Seitenketten — etwa Isoleucin und Valin, sowie häufig verwendete geschützte Formen von Serin und Threonin — stark zur Aggregation beitragen, wenn sie in hohen Mengen vorhanden sind. Dagegen reduzierten Aminosäuren mit voluminöseren oder komplexeren Seitenketten, einschließlich geschützter Formen von Phenylalanin, Tyrosin, Asparaginsäure und Arginin, tendenziell die Aggregation. Bestimmte kurzen Zwei‑Aminosäure‑Muster, wie Glycin–Serin und Leucin–Leucin, zeigten ebenfalls eine erhöhte Neigung zum Verklumpen, doch blieb die Gesamtbalance der Aminosäuretypen der dominierende Faktor.
Erkenntnisse in bessere Synthese‑Rezepte übersetzen
Mit dieser Karte von „Verklumpungs“ und „Entklumpungs“‑Aminosäuren baute das Team ein Ensemble von Modellen, das praktische Korrekturen vorschlagen kann, bevor eine Synthese gestartet wird. Für ein vorgeschlagenes Peptid sagt das Programm voraus, ob Aggregation wahrscheinlich ist, und lokalisiert Positionen nahe dem angehefteten Ende der Kette, an denen problematische Aminosäuren den größten Beitrag leisten. Es empfiehlt dann, diese durch spezielle Varianten zu ersetzen, etwa Pseudoprolin‑Bausteine, die die Aggregation vorübergehend stören, aber nach dem finalen Entschutzen wieder in die gewünschten Aminosäuren zurückverwandeln. Beim Test dieser Strategie an zwei notorisch schwierigen Peptidfragmenten führten wenige solche Substitutionen an modell‑ausgewählten Positionen zu einem dramatischen Anstieg der rohen Reinheit — von grob einem Fünftel auf etwa drei Viertel des Produktgemischs — im Einklang mit der Modell‑Rangfolge, welche Positionen den größten Nutzen bringen würden.
Was das für zukünftige Peptidmedikamente bedeutet
Für Nicht‑Spezialisten ist die zentrale Botschaft: Unter diesen Synthesebedingungen verhält sich das Verklumpen von Peptiden weniger wie ein empfindliches Schloss‑und‑Schlüssel‑Muster und mehr wie ein Problem der Gesamtzusammensetzung: die Proportionen der „öligen“ und „voluminösen“ Zutaten sind wichtiger als ihre exakte Reihenfolge. Indem die Autoren dies erkannten und quantifizierten, konnten sie sowohl langjährige Synthese‑Fehlschläge erklären als auch eine einfache, datengetriebene Strategie anbieten, um sie zu vermeiden. Ihre Arbeit zeigt, wie maschinelles Lernen verborgene Regeln in chemischen Prozessen aufdecken und in leicht anwendbare Designwerkzeuge übersetzen kann, wodurch sich der Weg von Peptidideen zu verlässlichen, skalierbaren Medikamenten beschleunigt.
Zitation: Tamás, B., Alberts, M., Laino, T. et al. Amino acid composition drives aggregation during peptide synthesis. Nat. Chem. 18, 677–685 (2026). https://doi.org/10.1038/s41557-026-02090-0
Schlüsselwörter: Peptidsynthese, Aminosäurezusammensetzung, Aggregation, maschinelles Lernen, Festphasenchemie