Clear Sky Science · fr
La composition en acides aminés gouverne l’agrégation lors de la synthèse peptidique
Pourquoi les courtes chaînes comptent pour les grands médicaments
Beaucoup de médicaments modernes sont de courtes chaînes d’acides aminés appelées peptides. Les chimistes peuvent construire ces chaînes bloc par bloc sur de minuscules billes, mais le procédé s’interrompt souvent parce que les chaînes en croissance s’agglomèrent. Cette étude montre que ce n’est pas tant l’ordre exact des blocs qui contrôle principalement cette agglomération, mais le nombre de chaque type présent globalement. En combinant apprentissage automatique et expériences ciblées, les auteurs révèlent quels acides aminés favorisent ou empêchent le plus l’agglomération et montrent comment utiliser ces connaissances pour synthétiser beaucoup plus efficacement des peptides difficiles.
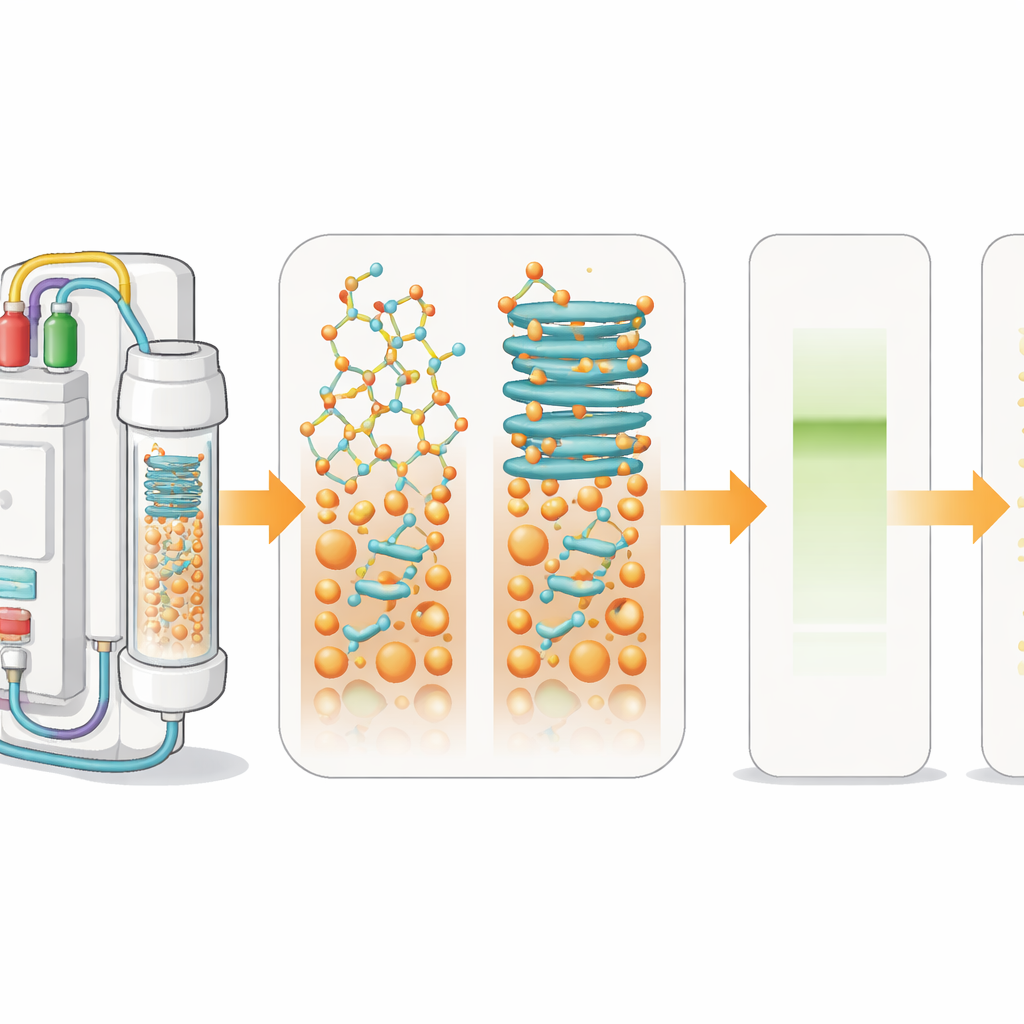
Comment on assemble les médicaments peptidiques
Pour fabriquer des peptides en laboratoire, les chimistes utilisent une méthode appelée synthèse peptidique en phase solide. Le premier acide aminé est fixé sur une bille insoluble, puis des acides aminés supplémentaires sont ajoutés par cycles, comme enfiler des perles sur un bracelet. À chaque étape, un groupe protecteur est enlevé puis une nouvelle unité est couplée. Un détecteur optique intégré suit ces étapes en temps réel en mesurant la taille et la forme des signaux produits lorsque les groupes protecteurs sont retirés. Quand les chaînes en croissance sur les billes commencent à se coller et se replier en structures de type feuillet, les signaux s’élargissent. Cette « agrégation » ralentit les réactions et conduit à des mélanges de produits défectueux plutôt qu’à un peptide unique et propre.
Laisser parler les données de milliers de synthèses
Les chercheurs ont combiné deux grands jeux de données de synthèses peptidiques automatisées en flux, totalisant plus de 500 séquences uniques. Pour chaque étape de chaque synthèse, ils disposaient à la fois de l’acide aminé ajouté et d’une mesure quantitative de l’ampleur de l’agrégation, extraite des signaux optiques. Ils ont ensuite appliqué une large palette d’approches d’apprentissage automatique — des modèles modernes de type langage qui lisent les chaînes d’acides aminés comme du texte, aux modèles statistiques classiques et aux méthodes de séries temporelles qui traitent une synthèse comme une suite d’événements — pour répondre à une question simple oui–non : un peptide donné s’agrège-t-il dans les conditions testées ?
Un retournement surprenant : de l’ordre aux ingrédients
Avec toutes ces méthodes, la précision de la prédiction est restée à peu près au même niveau modéré, indépendamment de la façon dont l’ordre des acides aminés était encodé. Cela a motivé un test clé. L’équipe a mélangé aléatoirement l’ordre des acides aminés dans chaque peptide tout en conservant les comptes globaux de chaque type. Si l’ordre précis était crucial, la performance aurait dû s’effondrer. Ce ne fut pas le cas : les modèles ont tout aussi bien performé sur les séquences mélangées. Même lorsque chaque peptide était réduit à un « vecteur de composition » en 20 nombres enregistrant simplement la fraction de chaque acide aminé présent, la précision est restée similaire. Pour confirmer cela expérimentalement, les auteurs ont pris huit peptides connus — quatre qui s’agrègent et quatre qui ne le font pas — et ont synthétisé cinq versions mélangées de chacun. La plupart des variantes mélangées se sont comportées comme les originaux : les séquences qui s’agrégeaient continuaient à le faire, et celles qui restaient solubles l’étaient généralement toujours, avec une tendance à démarrer l’agrégation à des positions similaires le long de la chaîne.
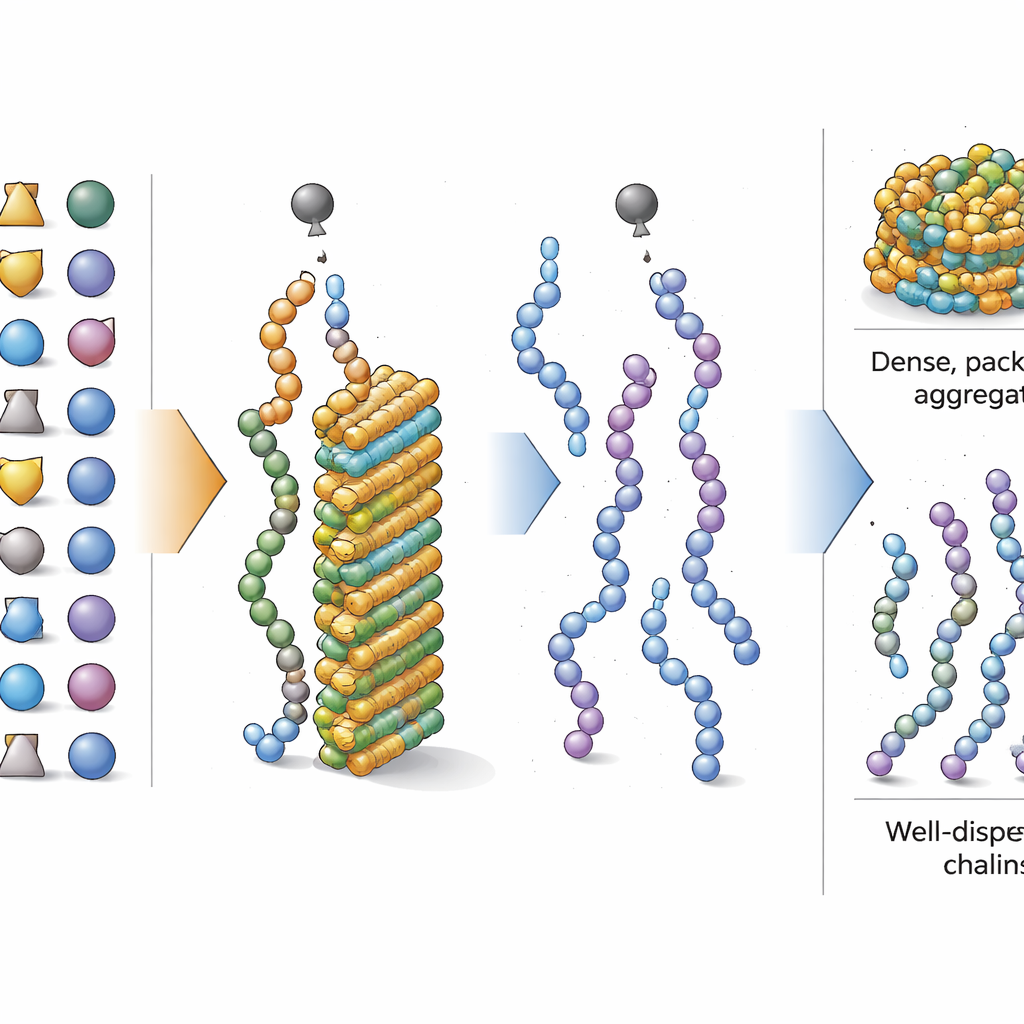
Les bons et mauvais acteurs parmi les acides aminés
Avec l’accent déplacé sur la composition globale, les chercheurs ont ensuite cherché quels acides aminés poussent le plus un peptide vers ou loin de l’agrégation pendant la synthèse. En utilisant un outil d’apprentissage automatique interprétable, ils ont noté dans quelle mesure l’augmentation de la fraction de chaque acide aminé modifiait la prédiction du modèle. Ils ont constaté que les blocs de construction avec des chaînes latérales simples et « huilées » — comme l’isoleucine et la valine, ainsi que des formes protégées couramment utilisées de la sérine et de la thréonine — favorisent fortement l’agrégation lorsqu’ils sont présents en grande quantité. En revanche, les acides aminés aux chaînes latérales plus volumineuses ou plus complexes, y compris des formes protégées de la phénylalanine, de la tyrosine, de l’aspartate et de l’arginine, ont tendance à réduire l’agrégation. Certains motifs courts de deux acides aminés, comme glycine–sérine et leucine–leucine, montraient aussi une tendance supplémentaire à provoquer l’agglomération, mais l’équilibre global des types d’acides aminés restait le facteur dominant.
Transformer les connaissances en meilleures recettes de synthèse
Armée de cette carte des acides aminés « agglomérants » et « désagglomérants », l’équipe a construit un ensemble de modèles capable de proposer des corrections pratiques avant de lancer une synthèse. Pour un peptide proposé, le programme prédit si l’agrégation est probable et identifie des positions proches de l’extrémité ancrée de la chaîne où des acides aminés problématiques contribuent le plus. Il recommande alors de remplacer ceux-ci par des versions spéciales, comme des blocs pseudoprolines, qui perturbent temporairement l’agrégation mais redeviennent les acides aminés souhaités après l’étape finale de déprotection. En testant cette stratégie sur deux fragments peptidiques notoirement difficiles, les chercheurs ont introduit un petit nombre de telles substitutions aux positions choisies par le modèle. Le résultat a été un bond spectaculaire de la pureté brute — d’environ un cinquième à près des trois quarts du mélange de produits — en accord avec le classement du modèle des positions les plus utiles.
Ce que cela signifie pour les futurs médicaments peptidiques
Pour un non-spécialiste, le message central est que, dans ces conditions de synthèse, le comportement d’agrégation des peptides ressemble moins à un mécanisme délicat de serrure et clé qu’à un problème de recette en vrac : les proportions des ingrédients « huilés » et « volumineux » importent plus que leur ordre exact. En reconnaissant et en quantifiant cela, les auteurs ont pu à la fois expliquer des échecs de synthèse de longue date et proposer une manière simple et pilotée par les données de les éviter. Leur travail illustre comment l’apprentissage automatique peut découvrir des règles cachées dans des processus chimiques et les convertir en outils de conception directs, accélérant en fin de compte le chemin des idées peptidiques vers des médicaments fiables et évolutifs.
Citation: Tamás, B., Alberts, M., Laino, T. et al. Amino acid composition drives aggregation during peptide synthesis. Nat. Chem. 18, 677–685 (2026). https://doi.org/10.1038/s41557-026-02090-0
Mots-clés: synthèse peptidique, composition en acides aminés, agrégation, apprentissage automatique, chimie en phase solide