Clear Sky Science · it
Calcolo con incertezza epistemica per il rilevamento delle intrusioni con spiegabilità e ottimizzazione multicriterio usando AA-NLS e GRUSO-GRU
Perché il traffico internet più sicuro conta
Ogni email che invii, videochiamata che fai o dispositivo intelligente che usi dipende da flussi invisibili di dati che scorrono nelle reti. Nascosti in quel traffico ci sono tentativi di aggressori di intrufolarsi, rubare informazioni o interrompere servizi. Le difese moderne cercano di individuare automaticamente queste intrusioni, ma i dati di rete reali sono disordinati: i pacchetti arrivano in ritardo, fuori ordine o con parti mancanti. Questo studio presenta un nuovo framework per il rilevamento delle intrusioni che non solo affronta quell’incertezza, ma spiega anche le sue decisioni e dà priorità agli avvisi più urgenti per i team di sicurezza.
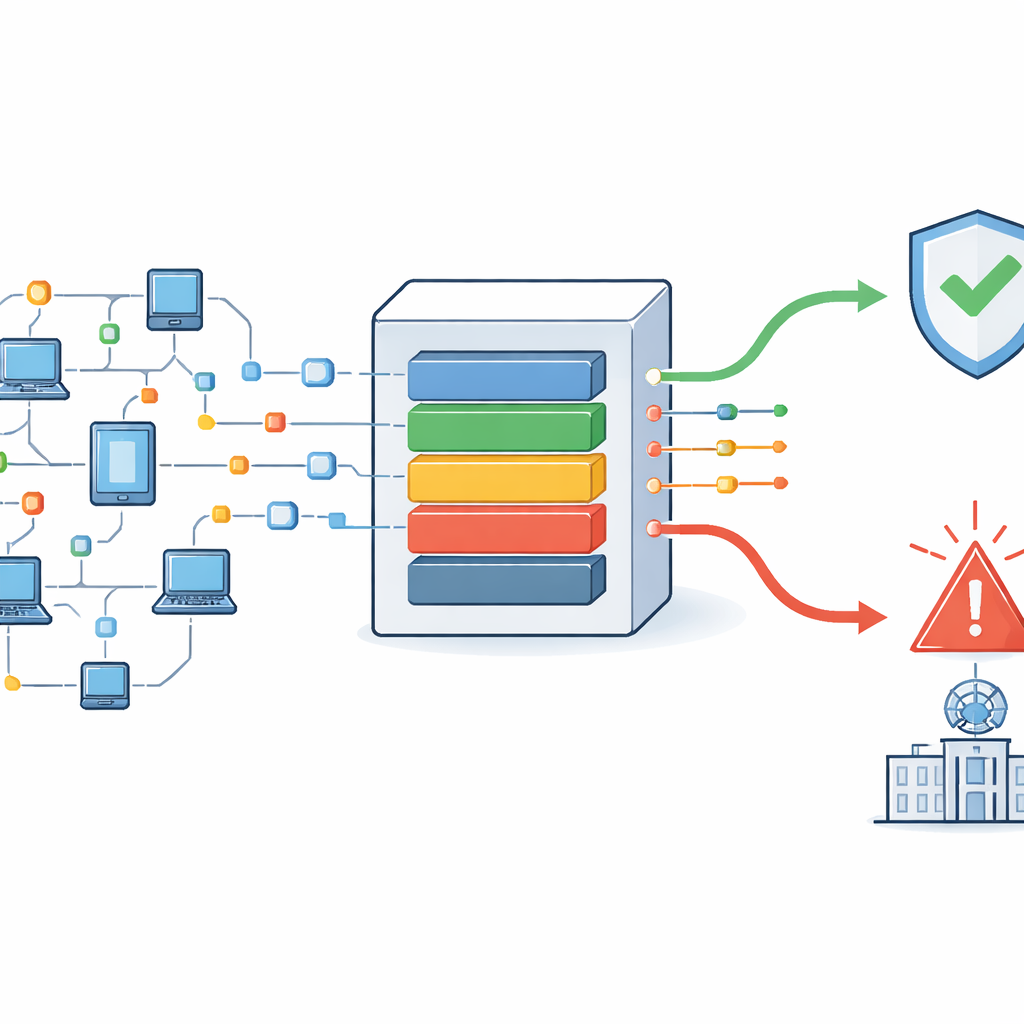
Traffico disordinato e pericoli nascosti
Gli strumenti tradizionali di rilevamento delle intrusioni spesso presumono che i dati di rete siano puliti e ordinati, oppure si concentrano principalmente su pattern di attacco noti. In pratica, il traffico internet è pieno di lacune, ritardi e pacchetti riordinati. Questi problemi possono causare confusione pericolosa: un attacco può sembrare normale se i suoi pacchetti arrivano in ritardo, oppure un’attività innocua può essere segnalata come ostile. Gli autori chiamano questo tipo di “divario di conoscenza” incertezza epistemica. Sostengono che molti sistemi esistenti la ignorano o la gestiscono solo in modo limitato, con conseguenti falsi allarmi, minacce non rilevate e code di avvisi travolgenti che rallentano la risposta umana.
Costruire una pipeline di rilevamento più intelligente
Il sistema proposto affronta l’intero ciclo di vita del monitoraggio di rete, dal traffico grezzo all’avviso finale. Comincia pulendo i dati: vengono rimossi record duplicati e un metodo nearest-neighbor adattato riempie i valori mancanti senza distorcere i pattern locali. Successivamente, una fase di clustering raggruppa comportamenti simili nel traffico in modo che attività insolite o rare risaltino più chiaramente. Da questi gruppi il sistema estrae caratteristiche chiave, come la frequenza di scambio dei pacchetti, la durata dei flussi e la velocità con cui i dati si muovono in ogni direzione. Queste feature forniscono un quadro compatto di come la rete si comporta in ogni momento.
Capire l’incertezza e la sincronizzazione temporale
Un’innovazione centrale del lavoro è un modulo dedicato a giudicare il rischio creato dai pacchetti fuori ordine. Usando un framework logico esteso, ogni pacchetto è trattato come avente gradi di “evidenza di attacco”, “evidenza di normalità” e “evidenza indeterminata”, che vengono combinate con cura in modo che il totale rimanga coerente e significativo. In parallelo, un modello temporale apprende come gli stati della rete evolvono nel tempo, smussando transizioni impossibili e proteggendo da punti ciechi a probabilità zero. Insieme, questi componenti catturano sia l’incertezza introdotta dai ritardi dei pacchetti sia il ritmo nascosto del comportamento normale rispetto a quello anomalo nella rete.
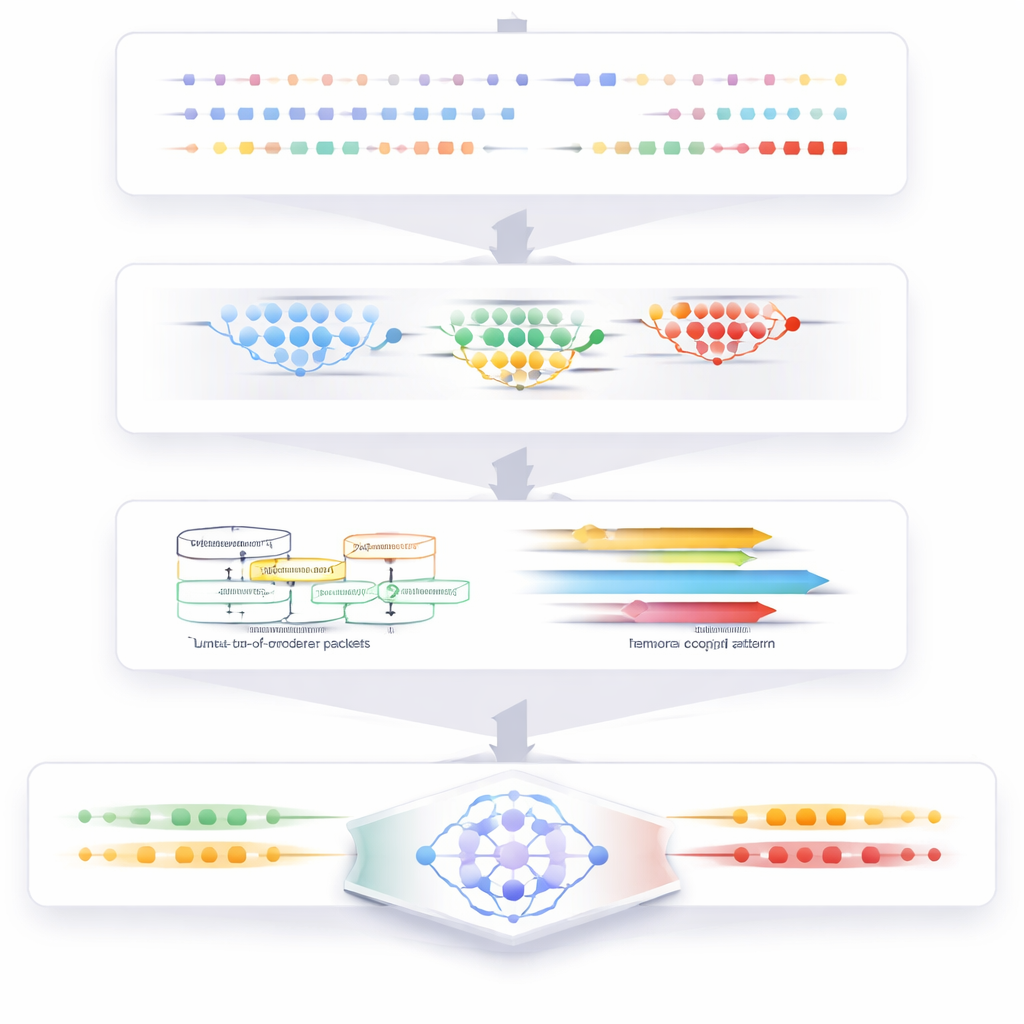
Imparare a individuare gli attacchi e spiegarli
Tutte queste informazioni elaborate alimentano un classificatore di deep learning personalizzato basato su una gated recurrent unit. Gli autori ridisegnano il suo cablaggio interno e le funzioni di attivazione in modo che apprenda più rapidamente, converga in modo più affidabile e si scalhi meglio rispetto ai modelli ricorrenti comuni. Il classificatore etichetta il traffico come benigno o come uno di diversi tipi di attacco, inclusi denial-of-service, brute force, botnet, infiltrazione e attacchi web. Per aiutare gli analisti a fidarsi delle segnalazioni del sistema, un modulo di spiegazione stima quindi quanto ciascuna feature di input abbia contribuito a una data decisione, usando uno schema di pesatura basato sull’informazione che è più stabile sui dati reali sbilanciati.
Concentrare l’attenzione sulle minacce più urgenti
In reti affollate, anche un rilevatore efficace può sommergere gli operatori con più avvisi di quanti ne possano gestire in tempo. Per affrontare questo problema, il framework aggiunge uno strato di ottimizzazione ispirato al comportamento di caccia delle volpi del deserto. Questo strato tratta gli avvisi come candidati da classificare e cerca un ordinamento che massimizzi la qualità del rilevamento minimizzando allo stesso tempo ritardo e uso delle risorse. Una funzione matematica speciale aiuta la ricerca a sfuggire a scelte intermedie scadenti. Esperimenti su diversi dataset pubblici di intrusioni mostrano che questo passaggio di prioritizzazione aumenta la produttività e riduce i tempi di risposta rispetto ad altre strategie di gestione degli avvisi.
Cosa significano i risultati per gli utenti comuni
Gli autori riportano che il loro approccio combinato raggiunge oltre il 99% di accuratezza nel rilevamento multi-classe delle intrusioni offrendo anche spiegazioni più chiare e avvisi più rapidi e meglio ordinati rispetto a metodi concorrenti. Per un non specialista, questo significa un “sistema immunitario” digitale più affidabile che è meno propenso a gridare al lupo e più capace di cogliere attacchi sottili, anche quando i dati sono incompleti o ingannevoli. Sebbene il metodo non cifri né protegga direttamente il contenuto dei dati degli utenti, rafforza in modo significativo un livello difensivo chiave nelle reti moderne. Con ulteriori lavori sulla protezione end-to-end, approcci come questo potrebbero contribuire a rendere i servizi online più fluidi, sicuri e degni di fiducia per tutti.
Citazione: Kiruthika, K., Karpagam, M., Sardar, T.H. et al. Epistemic uncertain computing for intrusion detection with explainability & multi-criteria optimization using AA-NLS and GRUSO-GRU. Sci Rep 16, 14050 (2026). https://doi.org/10.1038/s41598-026-44214-z
Parole chiave: rilevamento delle intrusioni, sicurezza di rete, incertezza, IA spiegabile, alert di cyberattacco