Clear Sky Science · fr
Prédire la localisation subcellulaire des circARN en fusionnant séquence et informations réseau
Pourquoi ces petits boucles d'ARN et leurs adresses comptent
À l'intérieur de chaque cellule humaine, d'innombrables molécules d'ARN s'activent, contribuant à réguler l'activation et la désactivation des gènes. Parmi elles figurent les ARN circulaires, ou circARN — des fragments d'ARN en forme de boucle, étonnamment stables et étroitement liés à de nombreuses maladies, y compris des cancers. Pour comprendre le rôle de ces molécules, les chercheurs ont besoin d'une information fondamentale : où elles résident dans la cellule. Or, cartographier les « adresses » des circARN par des expériences de laboratoire classiques est lent, coûteux et incomplet. Cette étude présente une nouvelle méthode informatique, appelée CircLoc, qui prédit la localisation des circARN à l'intérieur des cellules en combinant des informations tirées de leurs séquences et des réseaux biologiques complexes auxquels ils participent.
Petites boucles, grands rôles biologiques
Longtemps considérés comme de simples résidus du traitement des gènes, les circARN sont maintenant reconnus pour influencer de nombreux processus vitaux, de la différenciation cellulaire à la régulation génique. Leur forme circulaire les rend plus stables que beaucoup d'autres ARN, ce qui en fait des candidats attrayants comme biomarqueurs diagnostiques. Les circARN peuvent se lier à des protéines et séquestrer des microARN — de petits régulateurs qui atténuent normalement l'activité génique — modifiant ainsi le comportement cellulaire. Parce que de nombreuses molécules n'agissent que dans des régions précises de la cellule, comme le noyau, le cytoplasme ou les membranes, connaître la localisation subcellulaire d'un circARN fournit des indices importants sur sa fonction et son rôle potentiel dans la santé et la maladie.
Transformer des données dispersées en terrain d'entraînement
Les auteurs ont commencé par rassembler une collection soigneusement curatée de circARN humains à localisation connue à partir de plusieurs bases de données publiques. Après avoir éliminé des catégories rares et des groupes fortement déséquilibrés, ils se sont concentrés sur sept grandes régions cellulaires : le noyau, le nucléole, le nucléoplasme, le cytoplasme, le cytosol, la chromatine et les membranes. Au total, ils ont compilé 1 486 circARN avec une séquence fiable et au moins une localisation connue ; beaucoup étaient associés à plusieurs régions simultanément, faisant de la tâche un véritable problème de prédiction multilabel. Des jeux de données additionnels issus de versions antérieures des bases et d'une large collection liée au cancer ont été mis de côté comme tests indépendants, permettant d'évaluer la capacité du modèle à généraliser à des circARN nouvellement reportés.
Mêler motifs de séquence et cartographies d'interactions cellulaires
L'idée centrale de CircLoc est que l'adresse d'un circARN dépend non seulement de sa propre séquence, mais aussi de son entourage moléculaire. Côté séquence, le modèle analyse de courts fragments (k-mers et leurs complémentaires inversés) et des motifs plus riches appris par un grand modèle de langage spécialisé en ARN appelé RNAErnie, entraîné sur d'énormes jeux de données d'ARN pour capturer des régularités subtiles. Côté réseau, les auteurs ont construit plusieurs cartes montrant comment les circARN se connectent entre eux et à d'autres entités biologiques : recouvrements de séquences, maladies associées, réponses aux médicaments, microARNs interactifs et protéines liantes. Un outil d'embedding de réseau nommé node2vec convertit la structure de chaque carte en caractéristiques numériques, et un auto-encodeur par attention de graphe (GATE) les affine ensuite en mettant l'accent sur les connexions entre circARN ayant des comportements similaires, débruitant et enrichissant ainsi les signaux issus du réseau.
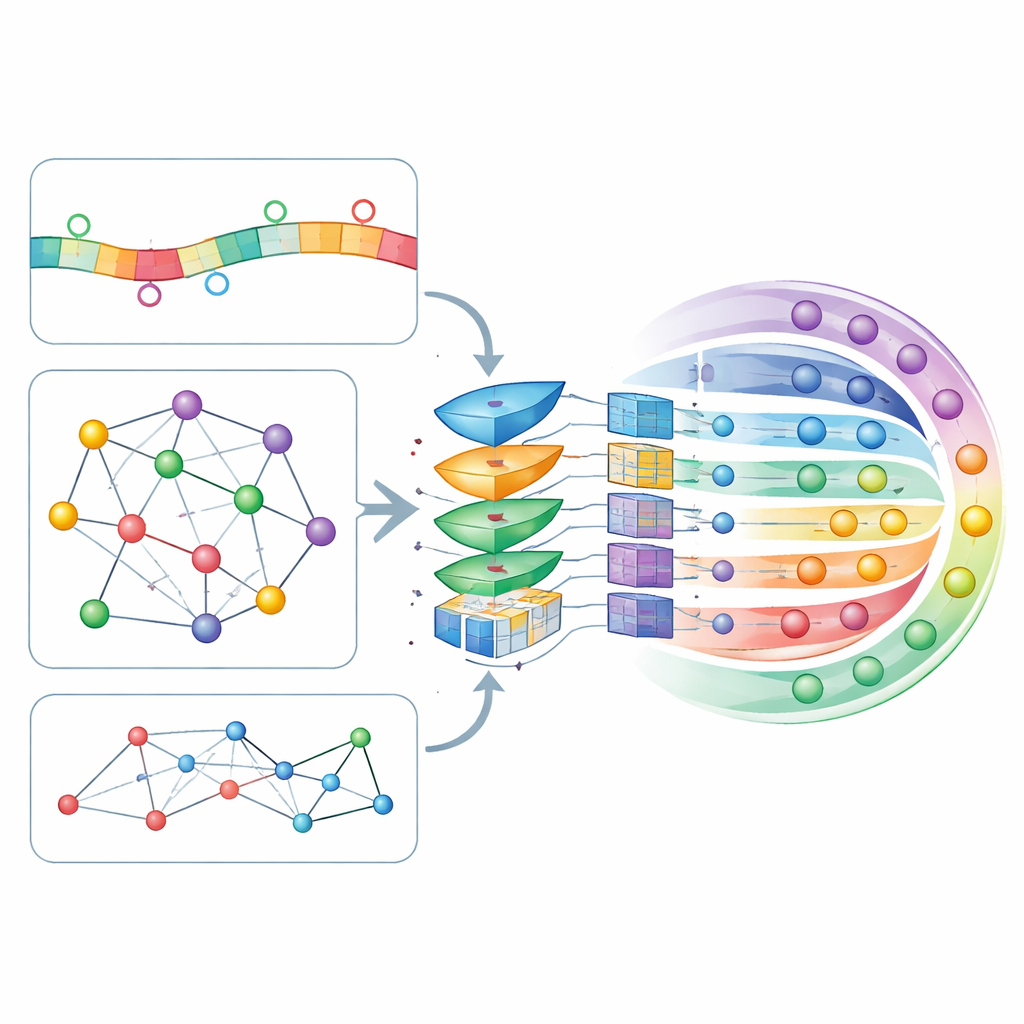
Laisser le modèle décider ce qui compte le plus
Toutes ces caractéristiques issues de la séquence et du réseau sont assemblées en un profil unique pour chaque circARN et passent par une couche d'auto-attention, un mécanisme qui permet au modèle d'apprendre quelles combinaisons de caractéristiques doivent le plus influencer ses décisions. Les profils affinés sont ensuite traités par un réseau neuronal profond entièrement connecté qui délivre une probabilité pour chacune des sept localisations possibles. Les auteurs ont ajusté de nombreux paramètres du modèle en utilisant une validation croisée à dix plis, une procédure rigoureuse qui divise à plusieurs reprises les données en ensembles d'entraînement et de test. CircLoc a obtenu un score moyen d'environ 0,79 sur une mesure de qualité standard (AUC), surpassant nettement les approches antérieures conçues pour les microARN et les méthodes multilabel classiques entraînées sur les mêmes caractéristiques. Des expériences supprimant des caractéristiques ou modules spécifiques ont montré que l'information réseau et le raffinement par GATE étaient particulièrement importants, tandis que les caractéristiques de séquence apportaient encore des améliorations utiles, quoique plus modestes.
Comment le modèle gère-t-il les nouveaux circARN ?
Pour évaluer l'utilité en situation réelle, l'équipe a entraîné CircLoc sur une version d'une base de données de localisation puis l'a testé sur des circARN apparus uniquement dans une version ultérieure, ainsi que sur une ressource séparée axée sur le cancer. Les performances ont diminué par rapport à l'ensemble d'entraînement d'origine, comme prévu face à de nouvelles données provenant de sources différentes, mais sont restées respectables : les scores moyens ont chuté modestement tout en indiquant une puissance prédictive significative. Ces tests, ainsi que des comparaisons avec d'autres méthodes, suggèrent que CircLoc peut fournir des estimations de premier ordre raisonnables pour la localisation de circARN nouvellement découverts, même lorsque certaines informations de soutien — telles que des associations détaillées avec des maladies ou des médicaments — font défaut.
Ce que cela signifie pour la recherche sur les ARN
Ce travail montre que la combinaison d'informations directes de séquence et de réseaux d'interaction riches peut aider les modèles computationnels à anticiper où les circARN sont susceptibles de se situer dans la cellule. Pour les biologistes expérimentateurs, CircLoc offre un moyen de prioriser les circARN à étudier dans des compartiments cellulaires donnés, économisant potentiellement du temps et des ressources. Si la méthode ne peut pas encore remplacer les mesures en laboratoire, et si ses auteurs soulignent des limites comme des données incomplètes et des performances modestes sur certains jeux de test, elle représente une étape importante vers des « annuaires » in silico à grande échelle pour les molécules d'ARN. À mesure que les bases de données s'enrichiront et que les techniques de modélisation s'amélioreront, de tels outils pourraient devenir des compagnons routiniers des expériences, guidant la recherche des circARN les plus pertinents en pathologie et en thérapeutique.
Citation: Chen, L., Hu, J. & Zhou, B. Predicting circRNA subcellular localization by fusing circRNA sequence and network information. Sci Rep 16, 12775 (2026). https://doi.org/10.1038/s41598-026-43808-x
Mots-clés: ARN circulaire, localisation subcellulaire, biologie computationnelle, apprentissage automatique, réseaux d'ARN