Clear Sky Science · en
Ergodicity and regime recoverability in finite Markov-modulated random walks
Why hidden patterns in random motion matter
Many systems around us look like pure noise: stock prices wiggling up and down, particles jostling in a fluid, or data packets hopping across a network. Yet these noisy motions are often steered by slow, unseen forces or "regimes" that quietly change how movement unfolds. This paper studies a simple but powerful version of that idea: a random walker moving back and forth on a short line, while an unseen environment switches between a few modes that alter how the walker behaves. The authors show, first, how to describe this system cleanly with probability theory, and then how far standard machine-learning tools can go in uncovering the hidden regimes just from watching the walker’s path.
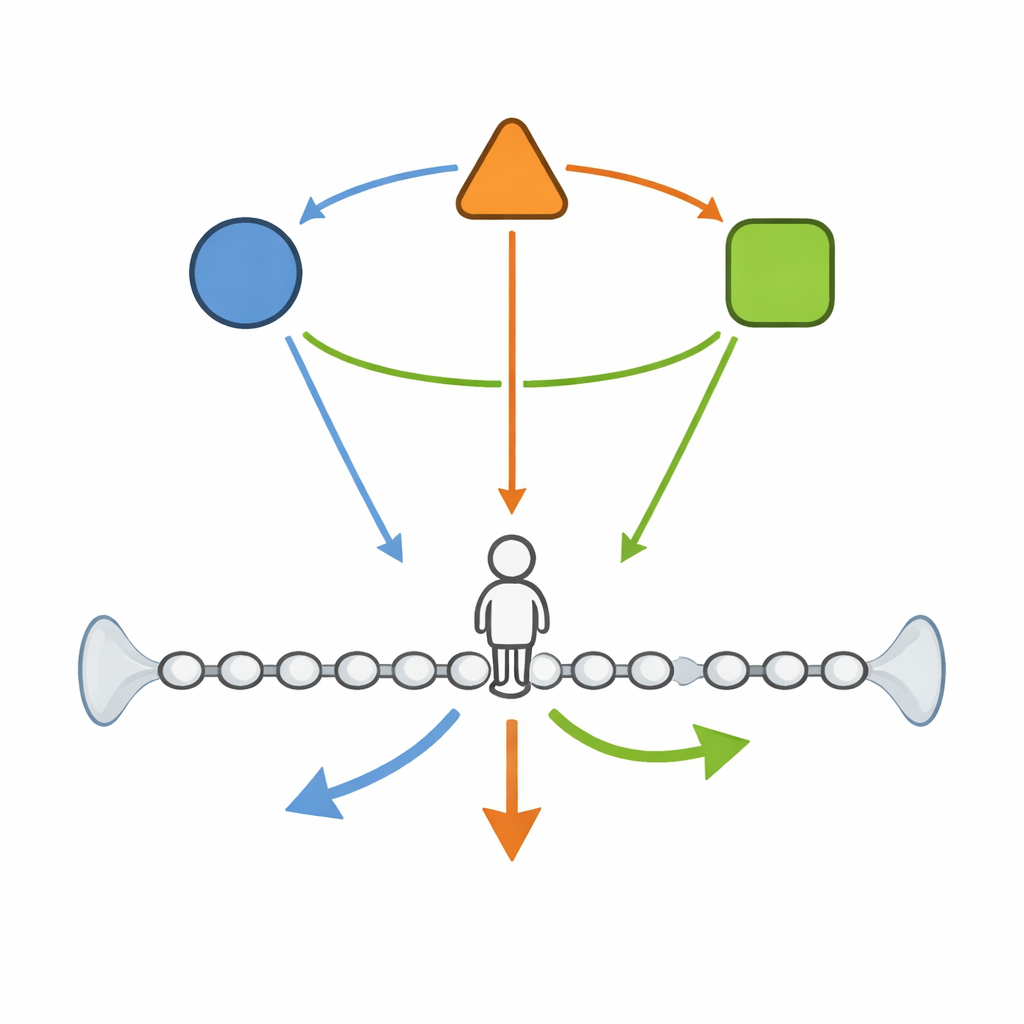
How a walker feels an unseen environment
The starting point is a walker that lives on a finite one-dimensional lattice, a row of sites from one end to the other with reflecting walls so it cannot escape. At each time step the walker can move left, move right, or stay put. Crucially, the chances of going left or right are not fixed: they depend on an invisible "environment" that itself jumps between a few states according to its own Markovian rules. When the environment is in one state, the walker may be biased to drift right; in another, it may prefer to step left or pause more often. Mathematically, the combined system of position and environment forms a joint Markov chain on a finite state space, and the authors write down its full transition rules and a discrete-time master equation describing how the probabilities evolve over time.
Guaranteeing long-term stability and mixing
Because the walker and environment interact, one might worry that the system could get stuck or behave irregularly. The authors identify simple structural conditions that rule this out. They require that the environment can eventually reach any of its states from any other and has some chance to remain where it is, and that in each regime the walker can move left and right along the line, with at least one genuine "stay where you are" move available in the joint system. Under these natural assumptions, standard finite Markov chain theory kicks in: the combined process is irreducible and aperiodic, has a unique long-run stationary distribution, and the joint behavior converges to this distribution as time goes on. This ergodicity result justifies treating long simulated paths as if they were generated from a stable, well-mixed system when feeding them into learning algorithms.
Teaching machines to read the hidden regimes
On top of this probabilistic backbone, the authors treat the simulated walker as a data source for supervised learning. They slice the walker’s increment sequence (the succession of small movements) into overlapping windows and convert each window into simple summary features: averages and variability of the steps, how often they are positive or zero, short-run dependence, and basic descriptors of the last few moves. Each window gets two labels: the environment state at the end of the window, and the sign of the next step. Using only these low-level features, off-the-shelf classifiers such as support vector machines, random forests, and gradient boosting machines can recover the hidden environment surprisingly well in a two-regime setting, with accuracy and balanced F1 scores close to 0.9. A likelihood-based hidden Markov model that is allowed to use the true simulator parameters but only the same local window provides a useful reference point and yields comparable regime-detection performance.
Predicting the next step and reconstructing the environment
The authors then ask whether knowing, or guessing, the current regime helps predict the walker’s next move. They compare three predictors: one that ignores regimes, one that augments features with estimated regime probabilities from the first task, and an idealized "oracle" that sees the true regime. In their default configuration, feeding in predicted regimes leads to only modest and not fully stable improvements over the baseline. By contrast, the oracle predictor performs clearly better, especially in probabilistic scoring, revealing that perfect regime knowledge would offer substantial predictive gains that current classifiers only partially realize. Finally, the authors use the decoded environment sequence to estimate how often the system remains in the same regime or switches, and to compute the implied long-term regime frequencies and mixing speeds. Despite individual misclassifications, the reconstructed transition matrix, stationary distribution, and spectral gap are close to those derived from the true environment, although there is a systematic slight underestimation of regime persistence.
What this means for finding hidden structure in noisy systems
Overall, the study shows that a seemingly simple random walk, when driven by a small hidden Markov environment, offers a clean testbed for connecting rigorous probability with practical machine learning. Under mild conditions the joint system settles into a stable long-run behavior, and the hidden regimes leave a detectable fingerprint in short windows of the walker’s motion. Standard classifiers using basic features can reliably uncover these regimes and even recover coarse properties of the unseen environment’s dynamics from a single long trajectory. At the same time, the modest gains in near-term prediction when using imperfect regime estimates highlight the gap between "in principle" value and what current methods extract from finite data. This gap, and the clear link between probabilistic structure and learnability, points the way to richer models and inference tools for uncovering hidden drivers in noisy time series.
Citation: Pambukyan, A., Saudagar, A.K.J. & Kumar, S. Ergodicity and regime recoverability in finite Markov-modulated random walks. Sci Rep 16, 12376 (2026). https://doi.org/10.1038/s41598-026-45019-w
Keywords: Markov-modulated random walk, hidden regimes, ergodic Markov chains, time series classification, hidden Markov models