Clear Sky Science · de
Erkennung und Klassifizierung von Chromosomen mit Defekten der Schwesterchromatid‑Kohäsion mithilfe von Objekterkennungsmodellen
Warum kleine Verdrehungen in der DNA wichtig sind
Jedes Mal, wenn sich eine Zelle teilt, muss sie eine exakte Kopie ihres genetischen Materials weitergeben. Damit diese Kopien bis zum richtigen Zeitpunkt zusammenbleiben, verlassen sich Zellen auf einen molekularen „Klebstoff“, der die gepaarten Chromosomen nebeneinander hält. Versagt dieser Klebstoff, können sich Chromosomen zu früh trennen, was zu gebrochenen Genomen, Entwicklungsstörungen und Krebs führen kann. Die hier beschriebene Studie widmet sich einem sehr praktischen Problem: Wie man diese subtilen Klebstofffehler automatisch in Mikroskopbildern erkennt, mithilfe moderner künstlicher Intelligenz statt müder menschlicher Augen.
Wie Chromosomen zusammenbleiben
Bevor eine Zelle sich teilt, wird jedes Chromosom kopiert, sodass zwei identische Stränge, die Schwesterchromatiden, entstehen. Eine Proteinanlage namens Cohesin hilft, diese Schwestern zu paaren, bis die Zelle bereit ist, sie auseinanderzuziehen. Wenn Cohesin oder seine Helferproteine nicht richtig funktionieren, können sich die Schwestern zu früh voneinander entfernen. Einer dieser Helfer ist DDX11, ein DNA‑Aufwicklungsenzym, dessen Defekte mit einer seltenen menschlichen Erkrankung namens Warsaw‑Breakage‑Syndrom in Verbindung gebracht werden. Unter dem Mikroskop zeigen Zellen mit Kohäsionsproblemen oft Chromosomen, deren zwei Stränge in der Mitte auffällig geöffnet oder gespalten erscheinen, doch normale von abnormalen Formen zu unterscheiden erfordert Geduld und Urteilskraft.
Warum manuelle Kontrollen nicht ausreichen
Traditionell verteilen Forschende Chromosomen auf einem Objektträger, färben sie an und klassifizieren dann pro Probe von Hand mindestens 50 bis 100 Chromosomen. Jedes Chromosom wird nach seiner Form und dem Abstand der Schwesterstränge beurteilt. Diese Arbeit ist langsam, subjektiv und ermüdend, was das Risiko für Fehler und inkonsistente Ergebnisse zwischen Forschenden erhöht. Frühere Versuche derselben Forschungsgruppe nutzten Deep Learning zur Klassifikation einzelner Chromosomenbilder, aber diese Systeme erforderten separate Software‑Schritte, um einzelne Chromosomen aus überfüllten Mikroskopaufnahmen auszuschneiden und verwirrende Überlappungen zu verwerfen. Diese zusätzliche Bildverarbeitung hing weiterhin stark von menschlichem Feintuning und Nachbearbeitung ab und verhinderte eine echte „Knopf‑drücken“-Automatisierung.
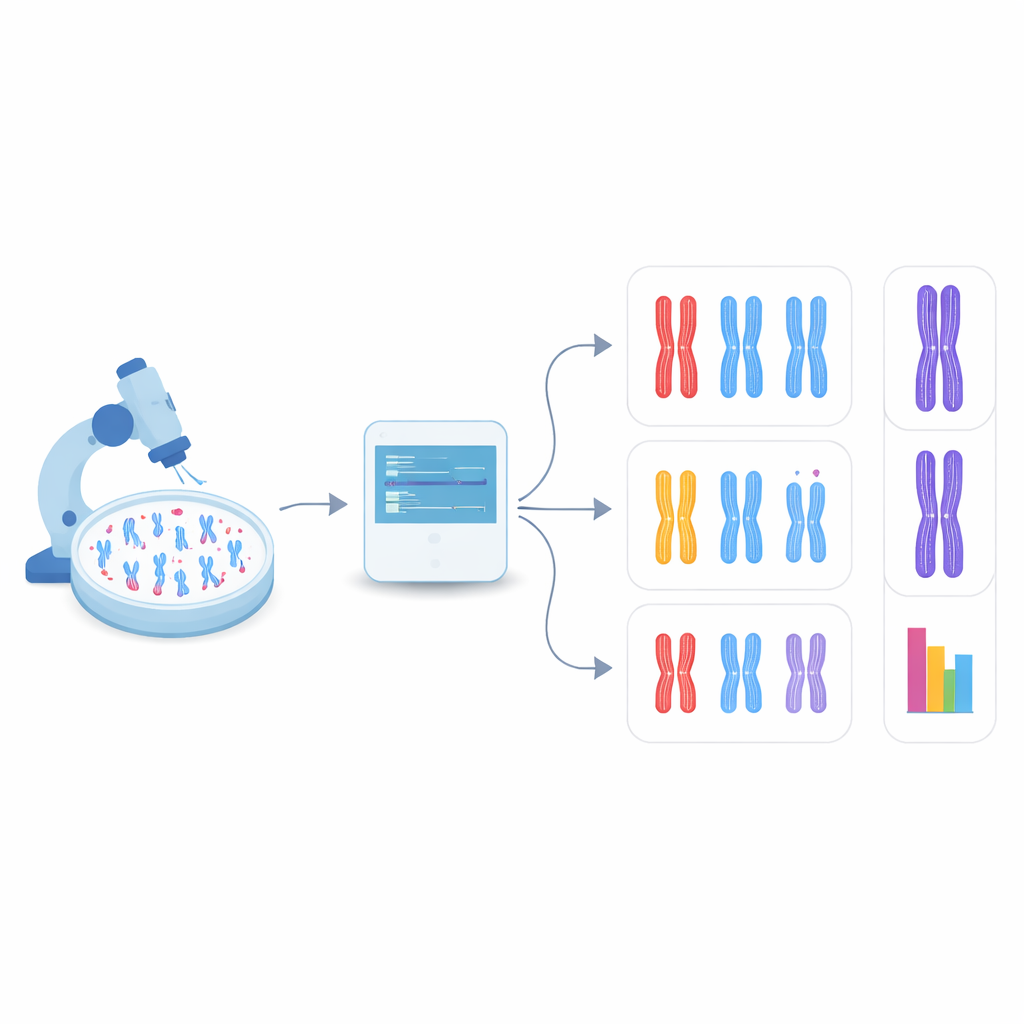
Den Computer die Chromosomen selbst finden lassen
In der neuen Studie wandte sich das Team der Objekterkennung zu, einem Bereich der Computer Vision, der mehrere Objekte in einem Bild sowohl finden als auch kategorisieren kann. Sie konzentrierten sich auf eine Familie schneller, weit verbreiteter Modelle namens YOLO (kurz für „You Only Look Once“) sowie auf mehrere konkurrierende Methoden. Zuerst bauten sie ein Testsystem auf, indem sie menschliche Zellen so veränderten, dass DDX11 fehlt und daher starke Kohäsionsprobleme zeigt, und bereiteten Mikroskopbilder dieser Chromosomen zusammen mit denen normaler Zellen vor. Jedes sichtbare Chromosom in diesen Bildern wurde mit einer Box umrandet und in eine von drei Formkategorien eingeordnet: eng gepaart, teilweise entlang der Arme getrennt oder deutlich in der Mitte gespalten. Diese von Hand erstellten Beschriftungen dienten den Algorithmen als Lernmaterial.
Der KI beibringen, subtile Formunterschiede zu sehen
Die Forschenden feinabgestimmten mehrere vortrainierte Objekterkennungsmodelle an etwas mehr als tausend beschrifteten Chromosomen und reservierten andere Bilder zur Leistungsüberprüfung. Sie verglichen, wie gut jedes Modell zunächst Chromosomen überhaupt finden konnte und dann diesen die richtige der drei Formkategorien zuordnete. Unter den getesteten Systemen erzielte eine Version namens YOLOv8 die besten Ergebnisse. Sie stimmte fast neun von zehn Chromosomen korrekt mit den menschlichen Beschriftungen überein, obwohl die Unterschiede zwischen den Kategorien oft sehr subtil waren. Wichtig ist: Auf Bilder aus normalen und DDX11‑defizienten Zellen angewendet, reproduzierte YOLOv8 das zentrale biologische Muster, das menschliche Experten sehen: Die fehlerhaften Zellen hatten deutlich weniger eng gepaarte Chromosomen und viel mehr Chromosomen mit deutlich getrennten Schwestersträngen.
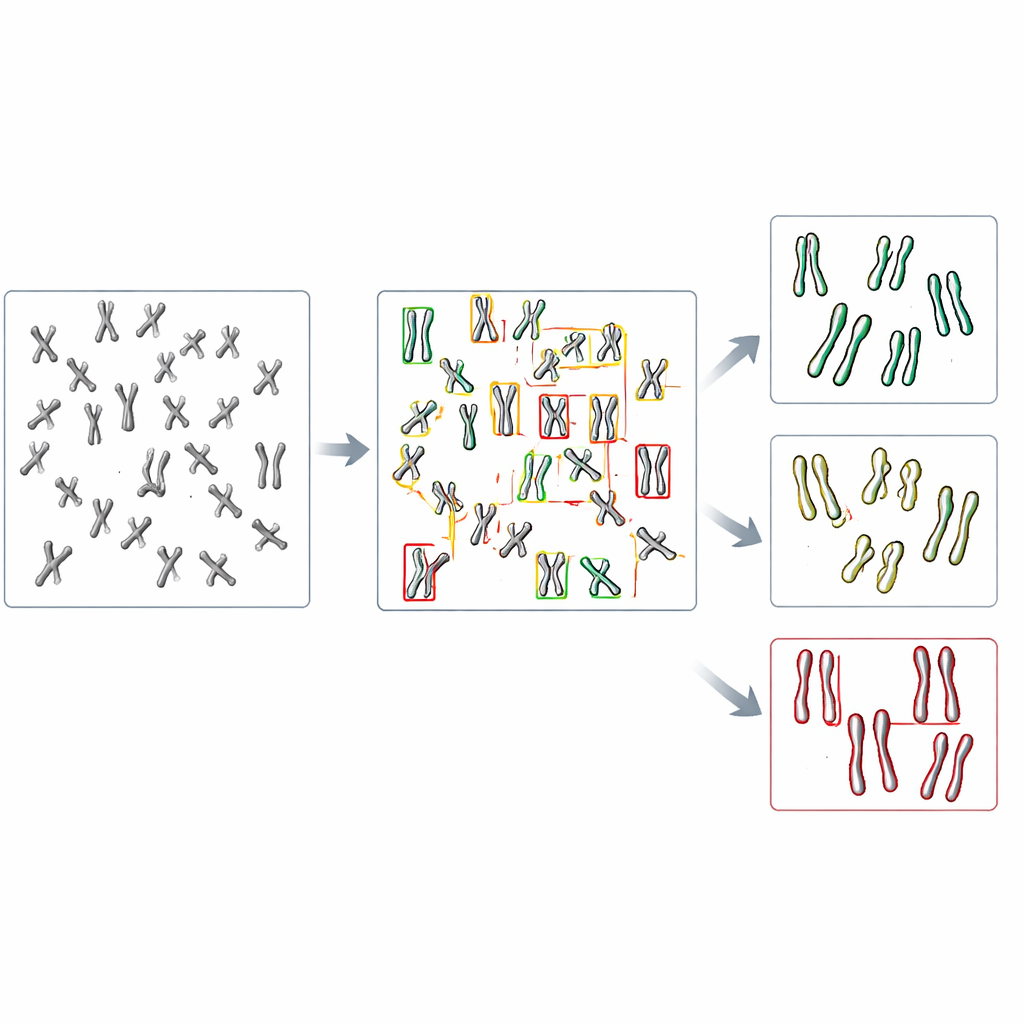
Was das für die zukünftige Laborarbeit bedeutet
Die Studie zeigt, dass ein KI‑Modell vollständige Chromosomenaufnahmen scannen und Kohäsionsdefekte automatisch markieren kann, ohne zusätzliche Zuschneide‑Schritte oder manuelle Nachbearbeitung. Zwar gibt es noch Verbesserungsmöglichkeiten – insbesondere bei überlappenden Chromosomen und Grenzformen –, doch die Methode ist bereits mit früheren Ansätzen konkurrenzfähig, die mehr menschliches Eingreifen erforderten. Da die Modelle durch Anpassung vorhandener Open‑Source‑Werkzeuge erstellt wurden und mit überschaubaren Bilddatensätzen nachtrainiert werden können, könnten Labore ohne tiefe Rechenkenntnisse eigene, angepasste Systeme entwickeln. Langfristig könnten ähnliche Strategien die Wirkstoffsuche beschleunigen, den Vergleich vieler genetischer Mutanten erleichtern und über Kohäsion hinaus auf andere feine Chromosomenveränderungen ausgeweitet werden, die für die menschliche Gesundheit relevant sind.
Zitation: Matsumoto, S., Sojo, M., Oshima, K. et al. Detection and classification of chromosomes with sister chromatid cohesion defects using object detection models. Sci Rep 16, 13719 (2026). https://doi.org/10.1038/s41598-026-43009-6
Schlüsselwörter: Chromosomenbildgebung, maschinelles Lernen, Objekterkennung, Kohäsionsdefekte, YOLOv8