Clear Sky Science · ar
تُحسّن MetaCAM، كإطار لتعيين تنشيط الفئات قائم على التجميع، قابلية تفسير النماذج
لماذا يهم معرفة ما يدور داخل قرارات الذكاء الاصطناعي
يمكن للذكاء الاصطناعي الحديث اكتشاف الأورام والتعرّف على الوجوه وتصنيف الصور بدقة تفوق البشر، لكنه غالبًا لا يستطيع شرح سبب اتخاذه قرارًا معينًا. هذا السلوك «الصندوق الأسود» يثير القلق في مواقف ذات مخاطر عالية مثل الطب أو السيارات ذاتية القيادة، حيث يحتاج الناس إلى معرفة أي أجزاء الصورة أثرت فعليًا في التنبؤ. تقدم هذه الورقة MetaCAM، طريقة جديدة لدمج العديد من تقنيات التصوير الموجودة في صورة واحدة أوضح لما ينظر إليه الشبكة العصبية المتخصّصة في تمييز الصور، بهدف جعل قرارات الذكاء الاصطناعي أكثر شفافية وقابلية للثقة.
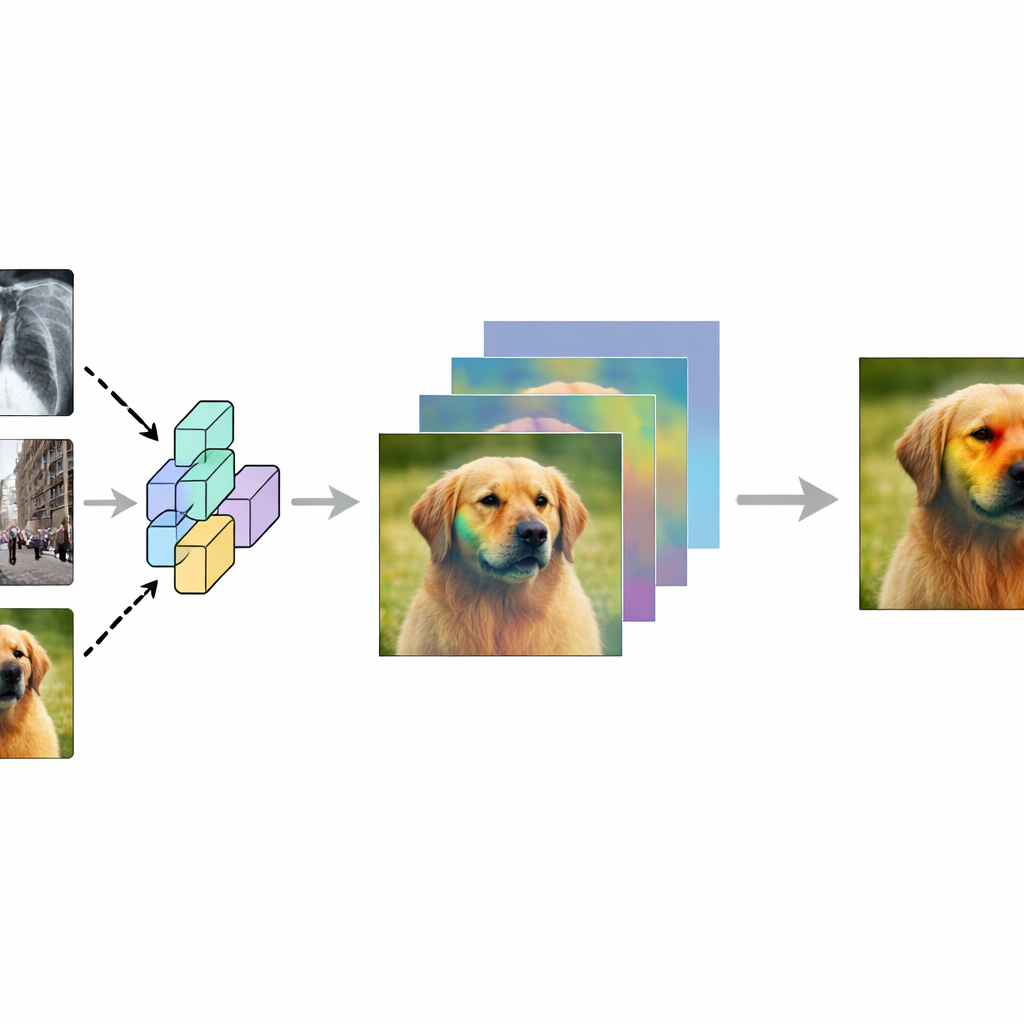
كيف تُظهر الآلات ما «تراه»
تعالج الشبكات العصبية الالتفافية، وهي العمود الفقري للتعرف على الصور، الصور عبر طبقات متعددة ثم تُخرج تسمية مثل «قطة» أو «ورم». أُنشئت خرائط تنشيط الفئات (CAMs) لتمكيننا من إلقاء نظرة داخل هذه الشبكات. تراكب CAM خريطة حرارية على الصورة الأصلية، مبرزًا المناطق التي أسهمت أكثر في التنبؤ المختار. على مر السنين ظهرت العديد من متغيرات CAM تختلف في طريقة استخدامها للتدرجات التراجعية وخرائط الخصائص أو التلاعب بالصورة لتقدير الأهمية. ومع ذلك، أداؤها غير متسق: فقد يعمل أسلوب واحد جيدًا على صورة أو فئة أو نموذج ما لكن يعطى نتائج سيئة في حالة أخرى، ولا يوجد اتفاق عالمي على أي CAM هو «الأفضل».
نهج الفريق لخرائط حرارية أوضح
يقترح المؤلفون MetaCAM، الذي يعامل طرق CAM المختلفة كأعضاء لجنة بدلًا من متنافسين. بدلًا من الثقة في خريطة حرارية واحدة، يبدأ MetaCAM بتوليد عدة خرائط لنفس الصورة والفئة المستهدفة باستخدام تقنيات متنوعة، بما في ذلك الأساليب المعتمدة على التدرجات، والأساليب المعتمدة على التلاعب، وحتى أدوات ذات صلة مثل FullGrad. ثم يبحث عن توافق: تُعتبر البكسلات التي تُبرز مرارًا عبر الأساليب أكثر موثوقية. عن طريق الاحتفاظ فقط بأعلى نسبة مئوية من البكسلات التي تتلقى أقوى وأثابتة درجات الاهتمام عبر التجميع، يُنتج MetaCAM خريطة حرارية مُنقّحة تتأثر أقل بسمات خلل أو فشل أي طريقة واحدة.
اختيار البكسلات الأكثر إقناعًا فقط
ابتكار رئيسي هو «العتبة التكيفية»، التي تقرر عدد البكسلات الأكثر نشاطًا التي يجب الاحتفاظ بها. بدلًا من إبراز، على سبيل المثال، أعلى 30 بالمئة من البكسلات دائمًا، يختبر المؤلفون منهجيًا قطعًا مختلفة ويختارون ذلك الذي يتطابق أفضل مع كيفية تغير تنبؤات الشبكة عندما تُطمس تلك البكسلات بلطف. يعتمدون على اختبار كمي يُسمى Remove and Debias (ROAD)، الذي يقيس مقدار انخفاض ثقة النموذج عندما تُؤثر البكسلات الأكثر «أهمية» ويقيس مدى قلة تغيره عندما تُزعج البكسلات الأقل أهمية. عن طريق المسح عبر عتبات عديدة، يجد MetaCAM المستوى الذي يعطي أقوى فصل بين المناطق الحاسمة فعليًا والمناطق ذات الصلة الضئيلة، ويمكن لهذه الفكرة نفسها أيضًا أن تُحسّن طرق CAM الفردية بمفردها.
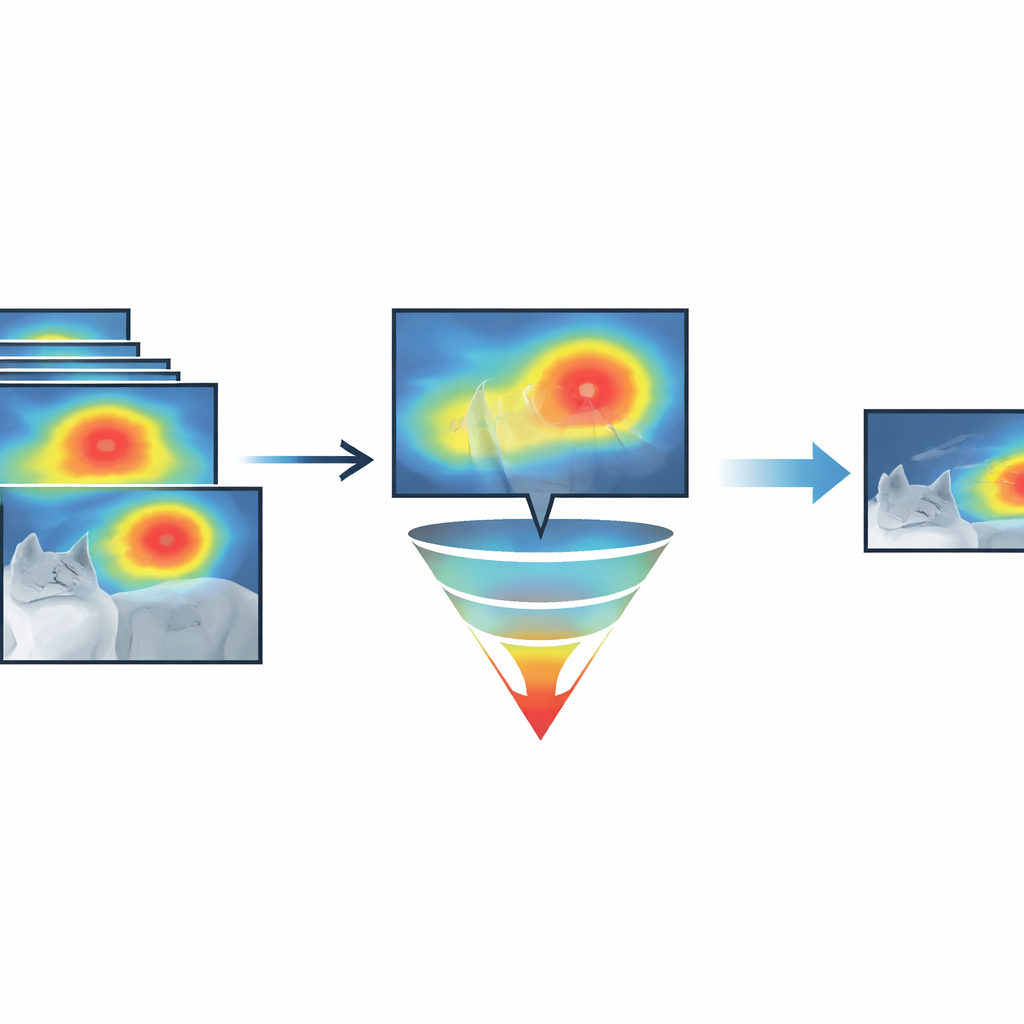
اكتشاف أي الطرق تُفيد—وأيها مفاجئًا يفيد
لفهم أي المكوّنات تصنع أفضل MetaCAM، أجرى الباحثون تجارب واسعة النطاق شغلوا فيها مجموعات من طرق CAM أو أوقفوها بتراكيب مختلفة. باستخدام حوسبة عالية الأداء، قيّموا 64 تركيبة من هذا النوع عبر العديد من الصور والفئات وبنى الشبكات العصبية. ثم قدموا إحصاءً ملخّصًا أطلقوا عليه تأثير الباقي التراكمي (Cumulative Residual Effect)، الذي يجسّد مقدار الرفع أو الخفض في الأداء الذي تميل كل مجموعة إلى إحداثه مقارنة بمتوسط التجارب. ومن المدهش أن الخرائط «السيئة» أو المزعجة — مثل CAM الذي غالبًا ما يبرز الجسم الخطأ أو خريطة مصنوعة من ضجيج عشوائي — قد تحسّن أحيانًا MetaCAM، لأن وجودها يضطر الإجماع إلى التضييق حول البكسلات التي تتفق عليها طرق متعددة، مما يقلل الإضاءات الخاطئة في أماكن أخرى.
ماذا يعني هذا لذكاء اصطناعي أكثر أمانًا وشفافية
عبر مجموعة واسعة من صور الاختبار والنماذج، تفوق MetaCAM مع العتبة التكيفية باستمرار على جميع طرق التصوير الفردية حسب مقياس ROAD. عمليًا، تشير خرائطه الحرارية بدقة أكبر إلى المناطق التي تقود قرار الشبكة فعليًا، مع تصفية قدر كبير من الفوضى والتضليل الذي يظهر في خرائط الطرق الوحيدة. لمجالات مثل تصوير الطب، والمركبات الذاتية، أو الفحص البيومتري — حيث يمكن أن يكون فهم سبب قول النظام «نعم» أو «لا» لا يقل أهمية عن النتيجة نفسها — يقدم MetaCAM نافذة أكثر استقرارًا ومبنية على الأدلة في تفكير الذكاء الاصطناعي، مما يساعد الخبراء على الحكم ما إذا كان النموذج يركز على الميزات الصحيحة قبل أن يثقوا به في العالم الحقيقي.
الاستشهاد: Dick, K., Kaczmarek, E., Miguel, O.X. et al. MetaCAM as an ensemble-based class activation mapping framework improves model explainability. Sci Rep 16, 10613 (2026). https://doi.org/10.1038/s41598-026-42879-0
الكلمات المفتاحية: الذكاء الاصطناعي القابل للتفسير, خرائط تنشيط الفئات, التعلّم العميق, قابلية تفسير النماذج, طرق التجميع