Clear Sky Science · zh
结构化处理的对比表示
这项研究为何与日常决策相关
许多影响我们生活的选择由算法驱动:我们在网上看到哪些产品、哪些药物被测试,甚至医疗处理如何被评估。这些系统常把复杂对象——比如一篇书面评论、一种分子或一段产品描述——视为所有细节同等重要。本文表明,这种做法可能悄然扭曲我们对因果关系的理解,并提出了一种新方法,帮助算法关注真正决定结果的要素,而不是令人分心的细节。
把风格与实质混淆的问题
当科学家或数据科学家估计“处理”的效果(例如展示广告、推荐产品或开具药物)时,他们通常假设处理可以用一个简单的数值或类别来描述。实际上,处理往往是富含结构的对象:完整的文本评论、一张图片或复杂的化学结构。这些对象内部隐含着不同方面:有些确实会影响结果(例如评论的积极程度),而另一些主要改变对象的外观或表达方式(例如写作风格)。作者表明,如果我们将这些复杂处理直接输入标准因果模型,模型可能会把这些风格性或非因果的方面误认为是真正的驱动因素,即使我们已经仔细测量了所有明显的混淆变量。结果就是对真正有效因素的估计产生偏差。
将有意义的信号与干扰噪声分离
为了解决这个问题,论文区分了“因果”隐藏因素——那些真正影响结果的处理部分——和“非因果”因素,它们可能与结果相关但并不实际改变结果。对于产品评论,情感或语气对销售有因果作用,而修辞和措辞可能不是。对于药物分子,某些结构特征可能驱动症状缓解,而其他特征则是偶然的。关键观点是我们观察到的处理是这两类因素的混合。如果模型直接从这种混合中学习,非因果方面可能充当背景变量的替代,误导效果估计。作者在数学上证明,为避免偏差,必须先将复杂处理转换为一种新的表示,这种表示只保留因果信息并舍弃其余部分。
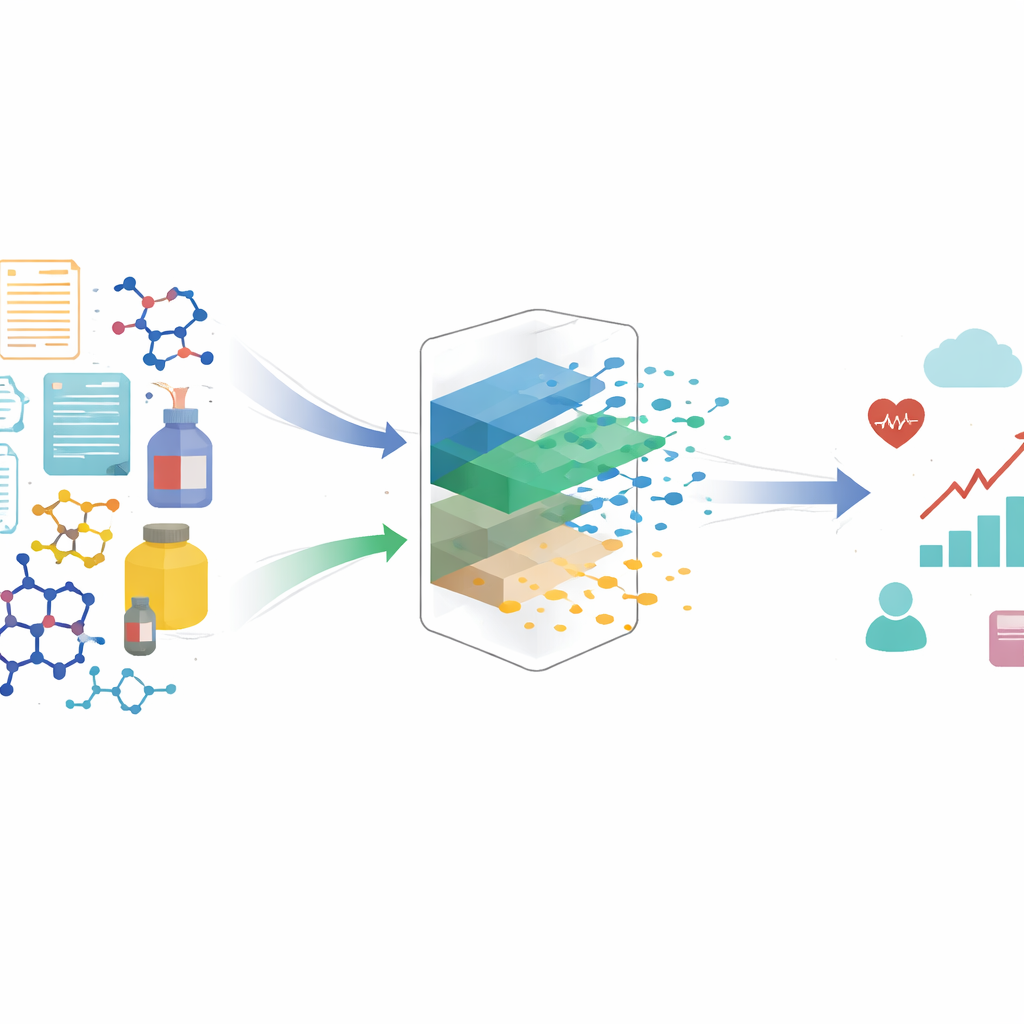
通过比较学习更好的表示
作者提出了一种对比学习方法来自动构建这种更纯粹的表示。该方法不是将每个处理孤立对待,而是查看相似与不相似的示例对。两个在相同背景下出现并产生非常相近结果的处理,即便表面细节不同,也被视为共享相同的潜在因果因素。通过在学习到的表示空间中将这些相似对拉近、并将在相同背景下却产生不同结果的对推远,算法被鼓励保留对结果重要的部分并忽略表面变化。在合理的数学假设下,作者证明了这一过程能够精确恢复处理的因果部分并滤除非因果部分,从而使其适合用于无偏的因果效应估计。
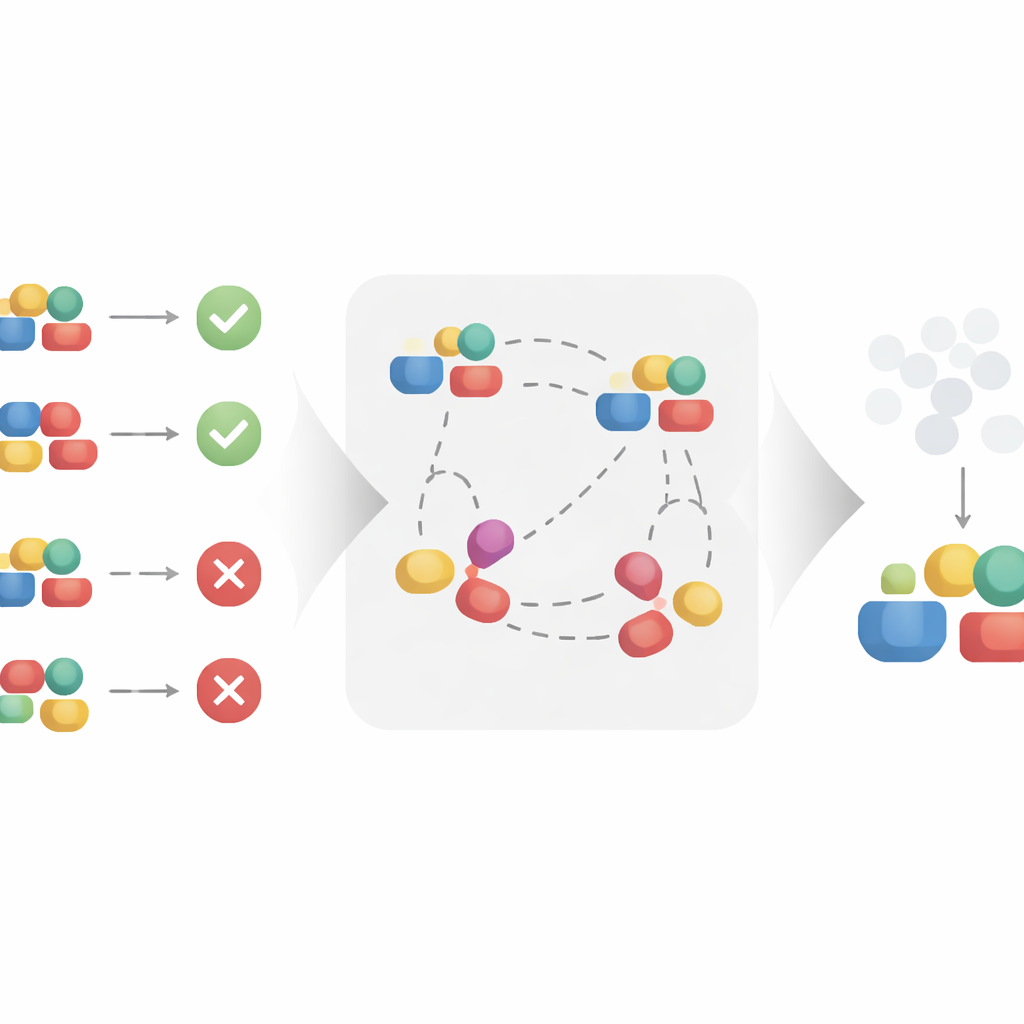
在合成和真实世界场景中的检验
为了验证该理论在实践中是否成立,作者将其方法应用于三类数据。首先,他们构建了一个合成数据集,在该数据集中处理的因果和非因果分量按设计已知。这使他们能够测试在向结果中加入噪声时方法是否仍能忽略非因果部分。接着,他们考察了分子数据,其中处理是化学结构、结果与有效性等性质相关;以及一组外套推荐数据,其中条目为在线市场中的商品。在这些不同设置中,他们将对比模型与标准因果模型以及一项为结构化处理设计的强竞争方法进行比较。虽然所有方法都能合理拟合观测数据,只有对比方法在处理的非因果部分被扰动时仍保持稳定,这表明它已成功学会关注真正的因果驱动因素。
对更智能、更公平系统的意义
对于普通读者,主要信息是数据中的并非所有细节都同等重要。指导决策的系统——从你在购物信息流中看到的内容到被推进的候选药物——可能会被看似有预测性的模式误导,但这些模式并非真正的因果关系。本文展示了通过教模型比较相似情境和结果,我们可以构建专注于真实变动杠杆的复杂处理表示。由此可以得到更可靠的“有效方案”估计,进而推动更好的产品推荐、更高效的药物发现,以及能基于因果而非表面相关性进行推理的更可信的人工智能系统。
引用: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
关键词: 因果推断, 表示学习, 对比学习, 高维处理, 机器学习