Clear Sky Science · pl
Kontrastowe reprezentacje ustrukturyzowanych interwencji
Dlaczego te badania mają znaczenie dla codziennych decyzji
Wiele wyborów wpływających na nasze życie jest kierowanych przez algorytmy: które produkty widzimy w sieci, które leki poddaje się testom, a nawet jak oceniane są terapie medyczne. Systemy te często traktują złożone obiekty — jak napisany komentarz, cząsteczka czy opis produktu — tak, jakby każdy szczegół był równie istotny. Artykuł pokazuje, że takie podejście może po cichu zniekształcać nasze rozumienie przyczyny i skutku, i przedstawia nową metodę, która pomaga algorytmom skupić się na tym, co rzeczywiście wpływa na wyniki, a nie na rozpraszających detalach.
Problem mylenia stylu z istotą
Gdy naukowcy lub analitycy szacują efekt „interwencji” (na przykład pokazanie reklamy, polecenie produktu czy przepisanie leku), często zakładają, że interwencję da się opisać prostą liczbą lub kategorią. W rzeczywistości interwencje bywają bogatymi, ustrukturyzowanymi obiektami: pełnym tekstem recenzji, obrazem czy złożoną strukturą chemiczną. W tych obiektach ukryte są różne aspekty: niektóre naprawdę wpływają na wynik (np. jak pozytywna jest recenzja), podczas gdy inne zmieniają głównie wygląd lub brzmienie obiektu (np. styl pisania). Autorzy pokazują, że jeśli podamy takie bogate interwencje bezpośrednio do standardowych modeli przyczynowych, modele mogą pomylić te stylistyczne lub nieprzyczynowe aspekty z prawdziwymi czynnikami wpływającymi na zmianę, nawet gdy starannie zmierzyliśmy oczywiste czynniki zakłócające. Skutkiem są obciążone (biased) oszacowania tego, co naprawdę działa.
Oddzielanie istotnego sygnału od rozpraszającego szumu
Aby się z tym uporać, artykuł rozróżnia „ukryte czynniki przyczynowe” — części interwencji, które rzeczywiście wpływają na wynik — oraz „czynniki nieprzyczynowe”, które mogą być skorelowane z wynikami, ale ich nie zmieniają. W przypadku recenzji produktu ton lub sentyment mają wpływ na sprzedaż, podczas gdy ozdobne zwroty czy dobór słów mogą nie mieć znaczenia. Dla cząsteczki leku określone cechy strukturalne mogą powodować ulgę w objawach, inne zaś są przypadkowe. Kluczową ideą jest to, że obserwowana interwencja jest mieszaniną obu rodzajów czynników. Jeśli model uczy się bezpośrednio z tej mieszaniny, aspekty nieprzyczynowe mogą pełnić rolę zastępczych zmiennych kontekstowych i wprowadzać w błąd przy szacowaniu efektów. Autorzy dowodzą matematycznie, że aby uniknąć uprzedzeń, najpierw trzeba przekształcić złożoną interwencję do nowej reprezentacji, która zachowuje jedynie informację przyczynową i odrzuca resztę.
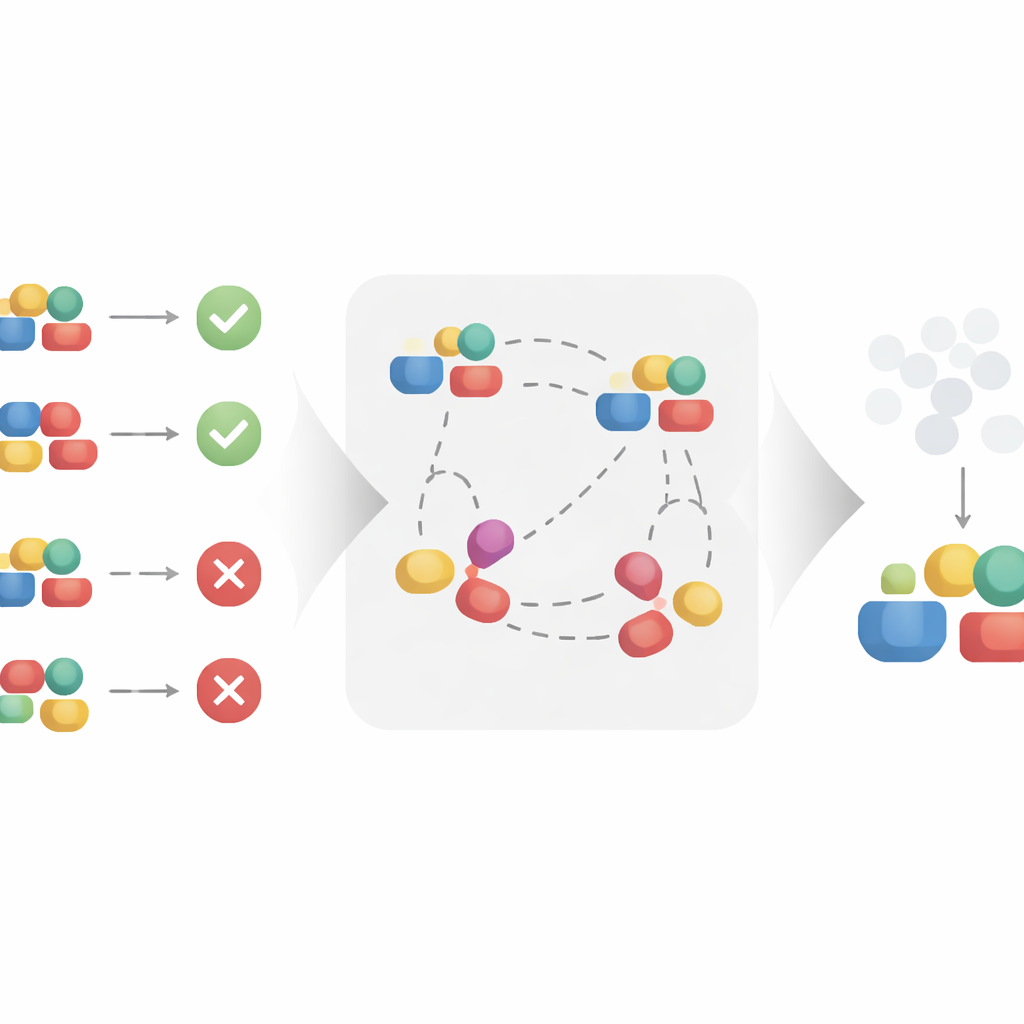
Uczenie lepszych reprezentacji przez porównania
Autorzy proponują podejście oparte na uczeniu kontrastowym, aby automatycznie zbudować czystszą reprezentację. Zamiast traktować każdą interwencję osobno, metoda analizuje pary przykładów podobnych i odmiennych. Dwie interwencje, które pojawiają się w tym samym kontekście i prowadzą do bardzo podobnych wyników, traktowane są tak, jakby dzieliły te same ukryte czynniki przyczynowe, nawet jeśli różnią się powierzchownymi szczegółami. Przyciągając takie podobne pary bliżej w uczonej przestrzeni reprezentacji, a jednocześnie odpychając pary, które mają ten sam kontekst, lecz prowadzą do różnych wyników, algorytm jest zachęcany do zachowania tego, co ważne dla wyniku, i ignorowania powierzchownych różnic. Przy rozsądnych założeniach matematycznych autorzy dowodzą, że ten proces odzyskuje dokładnie przyczynową część interwencji i filtruje część nieprzyczynową, czyniąc ją odpowiednią do nieobciążonego szacowania efektu przyczynowego.
Testowanie koncepcji w ustawieniach syntetycznych i rzeczywistych
Aby sprawdzić, czy teoria sprawdza się w praktyce, autorzy stosują swoją metodę do trzech typów danych. Najpierw konstruują dane syntetyczne, gdzie komponenty przyczynowe i nieprzyczynowe interwencji są znane z założenia. Pozwala to przetestować, czy metoda naprawdę potrafi ignorować części nieprzyczynowe nawet wtedy, gdy do wyników dodany jest hałas. Następnie badają dane dotyczące cząsteczek, gdzie interwencjami są struktury chemiczne, a wyniki odnoszą się do właściwości, takich jak skuteczność, oraz zestaw danych z rekomendacją okryć, gdzie przedmioty to produkty na rynku internetowym. W tych różnych ustawieniach porównują swój model kontrastowy ze standardowymi modelami przyczynowymi i z silnym, niedawnym konkurentem zaprojektowanym dla ustrukturyzowanych interwencji. Chociaż wszystkie metody potrafią dobrze dopasować obserwowane dane, tylko podejście kontrastowe pozostaje stabilne, gdy część nieprzyczynowa interwencji zostanie zmieniona, co wskazuje, że skutecznie nauczyło się skupiać na prawdziwych czynnikach przyczynowych.
Co to oznacza dla mądrzejszych, sprawiedliwszych systemów
Dla ogólnego odbiorcy główne przesłanie jest takie, że nie wszystkie szczegóły w danych są jednakowo ważne. Systemy wspomagające decyzje — od tego, co widzisz w kanale zakupowym, po to, które kandydaty na leki zostaną przesunięte dalej — mogą zostać zwiedzione przez wzorce, które wyglądają na predykcyjne, ale nie są naprawdę przyczynowe. Artykuł pokazuje, że ucząc modele porównywania podobnych sytuacji i wyników, możemy budować reprezentacje złożonych interwencji, które koncentrują się na prawdziwych dźwigniach zmiany. To z kolei prowadzi do bardziej wiarygodnych oszacowań „co działa”, otwierając drogę do lepszych rekomendacji produktów, wydajniejszego odkrywania leków i bardziej godnych zaufania systemów AI, które rozumują o przyczynach i skutkach, a nie o powierzchownych korelacjach.
Cytowanie: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
Słowa kluczowe: wnioskowanie przyczynowe, uczenie reprezentacji, uczenie kontrastowe, treatments o wysokiej wymiarowości, uczenie maszynowe