Clear Sky Science · pt
Representações contrastivas de tratamentos estruturados
Por que esta pesquisa importa para decisões do dia a dia
Muitas das escolhas que afetam nossas vidas são guiadas por algoritmos: quais produtos vemos online, quais medicamentos são testados, até como tratamentos médicos são avaliados. Esses sistemas frequentemente tratam objetos complexos — como uma avaliação escrita, uma molécula ou a descrição de um produto — como se cada detalhe tivesse a mesma importância. Este artigo mostra que essa abordagem pode distorcer silenciosamente nossa compreensão de causa e efeito e introduz um novo método que ajuda os algoritmos a focar no que realmente impulsiona os resultados, em vez de detalhes que distraem.
O problema de confundir estilo com substância
Quando cientistas ou cientistas de dados estimam o efeito de um “tratamento” (por exemplo, mostrar um anúncio, recomendar um produto ou prescrever um medicamento), eles frequentemente assumem que o tratamento pode ser descrito por um número ou categoria simples. Na realidade, tratamentos são frequentemente objetos ricos e estruturados: uma avaliação completa em texto, uma imagem ou uma estrutura química complexa. Ocultos nesses objetos estão aspectos diferentes: alguns influenciam genuinamente o resultado (como o quão positiva é uma avaliação), enquanto outros mudam principalmente a aparência ou o som do objeto (como o estilo de escrita). Os autores mostram que, se alimentarmos esses tratamentos ricos diretamente em modelos causais padrão, os modelos podem confundir esses aspectos estilísticos ou não causais com verdadeiros motores de mudança, mesmo quando medimos cuidadosamente todos os fatores de confusão óbvios. O resultado são estimativas viesadas do que realmente funciona.
Separando o sinal significativo do ruído que distrai
Para enfrentar isso, o artigo distingue entre fatores ocultos “causais” — partes do tratamento que realmente afetam o resultado — e fatores “não causais”, que podem estar correlacionados com os resultados, mas não os alteram de fato. Para uma avaliação de produto, tom ou sentimento são causais para as vendas, enquanto floreios e escolhas de palavras podem não ser. Para uma molécula de medicamento, certas características estruturais podem conduzir ao alívio dos sintomas, enquanto outras são incidentais. A ideia central é que o tratamento que observamos é uma mistura desses dois tipos de fatores. Se um modelo aprende diretamente dessa mistura, aspectos não causais podem funcionar como substitutos de variáveis de contexto e induzir a erro nas estimativas de efeito. Os autores provam matematicamente que, para evitar viés, é preciso primeiro transformar o tratamento complexo em uma nova representação que preserve apenas a informação causal e descarte o restante.
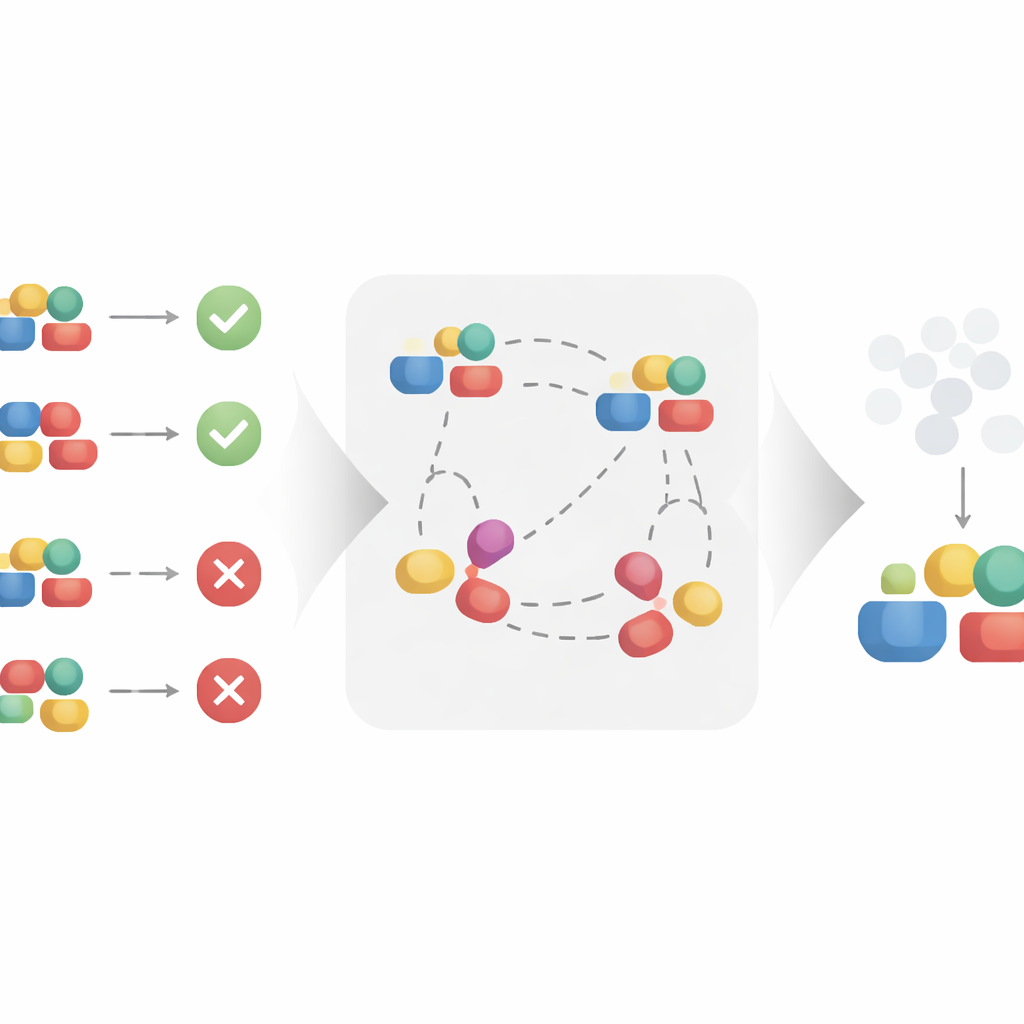
Aprendendo representações melhores por meio de comparações
Os autores propõem uma abordagem de aprendizado contrastivo para construir automaticamente essa representação mais limpa. Em vez de tratar cada tratamento isoladamente, o método analisa pares de exemplos semelhantes e dissimilares. Dois tratamentos que aparecem no mesmo contexto e levam a resultados muito similares são tratados como se compartilhassem os mesmos fatores causais subjacentes, mesmo que seus detalhes superficiais difiram. Ao aproximar esses pares semelhantes em um espaço de representação aprendido, e afastar pares que compartilham o mesmo contexto mas conduzem a resultados diferentes, o algoritmo é incentivado a manter o que importa para o resultado e a ignorar variações superficiais. Sob suposições matemáticas razoáveis, os autores demonstram que esse processo recupera exatamente a parte causal do tratamento e filtra a parte não causal, tornando-a adequada para estimativas de efeito causal sem viés.
Testando a ideia em cenários sintéticos e do mundo real
Para verificar se essa teoria funciona na prática, os autores aplicam seu método a três tipos de dados. Primeiro, constroem um conjunto de dados sintético em que os componentes causais e não causais do tratamento são conhecidos por projeto. Isso lhes permite testar se o método consegue realmente ignorar as partes não causais mesmo quando ruído é adicionado aos resultados. Em seguida, examinam dados de moléculas, onde os tratamentos são estruturas químicas e os resultados se relacionam a propriedades como eficácia, e um conjunto de recomendações de casacos, em que os itens são produtos em um mercado online. Nesses diversos cenários, eles comparam seu modelo contrastivo com modelos causais padrão e com um concorrente recente e robusto projetado para tratamentos estruturados. Embora todos os métodos consigam ajustar razoavelmente bem os dados observados, apenas a abordagem contrastiva permanece estável quando as partes não causais do tratamento são perturbadas, indicando que aprendeu com sucesso a focar nos verdadeiros motores causais.
O que isso significa para sistemas mais inteligentes e justos
Para um leitor geral, a mensagem principal é que nem todos os detalhes nos dados têm o mesmo peso. Sistemas que orientam decisões — desde o que você vê em um feed de compras até quais candidatos a fármaco são promovidos — podem ser enganados por padrões que parecem preditivos, mas não são verdadeiramente causais. Este artigo mostra que, ao ensinar modelos a comparar situações e resultados semelhantes, podemos construir representações de tratamentos complexos que se concentram nas alavancas reais de mudança. Em consequência, isso leva a estimativas mais confiáveis do “que funciona”, abrindo caminho para melhores recomendações de produto, descoberta de medicamentos mais eficiente e sistemas de IA mais confiáveis que raciocinam sobre causa e efeito em vez de correlações superficiais.
Citação: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
Palavras-chave: inferência causal, aprendizado de representação, aprendizado contrastivo, tratamentos de alta dimensão, aprendizado de máquina