Clear Sky Science · it
Rappresentazioni contrastive di trattamenti strutturati
Perché questa ricerca conta per le decisioni di tutti i giorni
Molte delle scelte che influenzano le nostre vite sono guidate da algoritmi: quali prodotti vediamo online, quali farmaci vengono sperimentati, persino come vengono valutati i trattamenti medici. Questi sistemi spesso trattano oggetti complessi — come una recensione scritta, una molecola o la descrizione di un prodotto — come se ogni dettaglio fosse ugualmente importante. Questo articolo mostra che un approccio del genere può distorcere silenziosamente la nostra comprensione di causa ed effetto, e introduce un nuovo metodo che aiuta gli algoritmi a concentrarsi su ciò che realmente determina gli esiti, non sui dettagli fuorvianti.
Il problema di confondere stile e sostanza
Quando scienziati o data scientist stimano l’effetto di un “trattamento” (per esempio mostrare un annuncio, raccomandare un prodotto o prescrivere un farmaco), spesso assumono che il trattamento possa essere descritto con un numero o una categoria semplice. In realtà, i trattamenti sono frequentemente oggetti ricchi e strutturati: una recensione completa, un’immagine o una struttura chimica complessa. Nascosti in questi oggetti ci sono aspetti diversi: alcuni influenzano davvero l’esito (come quanto è positiva una recensione), mentre altri cambiano soprattutto l’aspetto o il tono dell’oggetto (come lo stile di scrittura). Gli autori mostrano che se inseriamo questi trattamenti ricchi direttamente in modelli causali standard, i modelli possono scambiare questi aspetti stilistici o non causali per veri fattori che determinano il cambiamento, anche quando abbiamo misurato con cura tutti i confondenti evidenti. Il risultato sono stime distorte di ciò che funziona davvero.
Separare il segnale significativo dal rumore distrattivo
Per affrontare il problema, l’articolo distingue tra fattori nascosti “causali” — quelle parti di un trattamento che influenzano davvero l’esito — e fattori “non causali”, che possono essere correlati agli esiti ma non li modificano effettivamente. Per una recensione di prodotto, il tono o il sentimento sono causali per le vendite, mentre svolazzi e scelta di parole potrebbero non esserlo. Per una molecola, certe caratteristiche strutturali possono guidare il sollievo dei sintomi, mentre altre sono incidentali. L’idea chiave è che il trattamento osservato è una miscela di entrambi i tipi di fattori. Se un modello impara da questa miscela direttamente, gli aspetti non causali possono agire come sostituti di variabili di contesto e fuorviare le stime d’effetto. Gli autori dimostrano matematicamente che per evitare bias è necessario prima trasformare il trattamento complesso in una nuova rappresentazione che preservi soltanto l’informazione causale e scarti il resto.
Imparare rappresentazioni migliori tramite confronti
Gli autori propongono un approccio di apprendimento contrastivo per costruire automaticamente questa rappresentazione più pulita. Invece di trattare ogni trattamento isolatamente, il metodo considera coppie di esempi simili e dissimili. Due trattamenti che appaiono nello stesso contesto e portano a esiti molto simili vengono trattati come se condividessero gli stessi fattori causali sottostanti, anche se i dettagli superficiali differiscono. Avvicinando queste coppie simili nello spazio di rappresentazione appreso, e allontanando le coppie che condividono lo stesso contesto ma portano a esiti diversi, l’algoritmo è incoraggiato a mantenere ciò che conta per l’esito e a ignorare le variazioni superficiali. Sotto assunzioni matematiche ragionevoli, gli autori dimostrano che questo processo recupera esattamente la parte causale del trattamento e filtra la parte non causale, rendendolo adatto per stime di effetto causale non distorte.
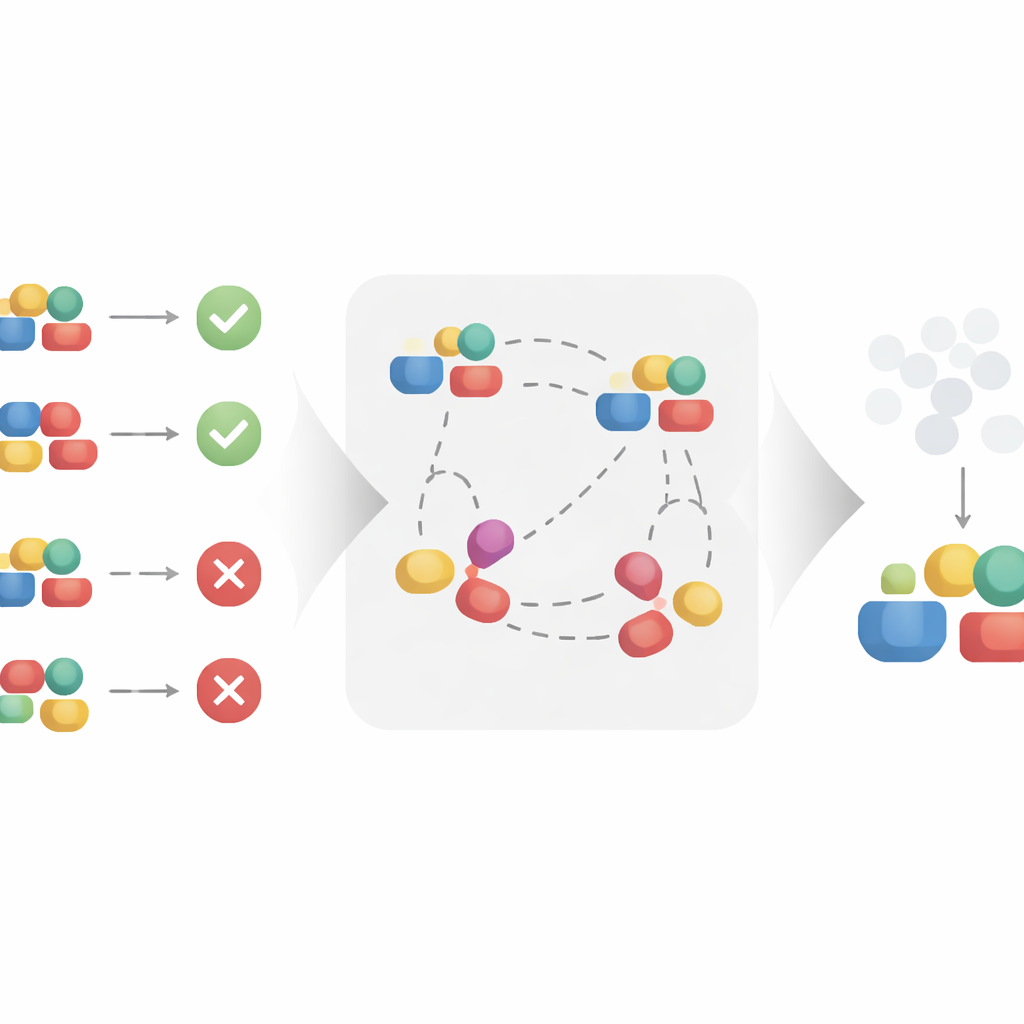
Mettere alla prova l’idea in contesti sintetici e reali
Per verificare se questa teoria regge nella pratica, gli autori applicano il loro metodo a tre tipi di dati. Primo, costruiscono un dataset sintetico in cui le componenti causali e non causali del trattamento sono note per progettazione. Questo permette di testare se il metodo può veramente ignorare le parti non causali anche quando viene aggiunto rumore agli esiti. Poi esaminano dati su molecole, dove i trattamenti sono strutture chimiche e gli esiti riguardano proprietà come l’efficacia, e un dataset di raccomandazioni di cappotti, dove gli articoli sono prodotti in un mercato online. In questi contesti diversi, confrontano il loro modello contrastivo con modelli causali standard e con un forte concorrente recente progettato per trattamenti strutturati. Pur riuscendo tutti a adattare ragionevolmente i dati osservati, solo l’approccio contrastivo rimane stabile quando le parti non causali del trattamento vengono perturbate, indicando che ha imparato con successo a concentrarsi sui veri fattori causali.
Cosa significa questo per sistemi più intelligenti e più equi
Per un lettore generico, il messaggio principale è che non tutti i dettagli nei dati hanno lo stesso valore. I sistemi che guidano decisioni — da ciò che vedi in un feed di shopping a quali candidati farmaceutici vengono avanzati — possono essere ingannati da pattern che sembrano predittivi ma non sono veramente causali. Questo articolo mostra che insegnando ai modelli a confrontare situazioni ed esiti simili, possiamo costruire rappresentazioni di trattamenti complessi che si concentrano sulle leve reali del cambiamento. A loro volta, ciò porta a stime più affidabili di “ciò che funziona”, aprendo la strada a raccomandazioni di prodotto migliori, a una scoperta di farmaci più efficiente e a sistemi di IA più dignitosi e affidabili che ragionano su cause ed effetti anziché su correlazioni di superficie.
Citazione: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
Parole chiave: inferenzacausale, apprendimentorappresentazioni, apprendimentocontrastivo, trattamenti ad alta dimensionalità, apprendimentomacchine