Clear Sky Science · es
Representaciones contrastivas de tratamientos estructurados
Por qué esta investigación importa para las decisiones cotidianas
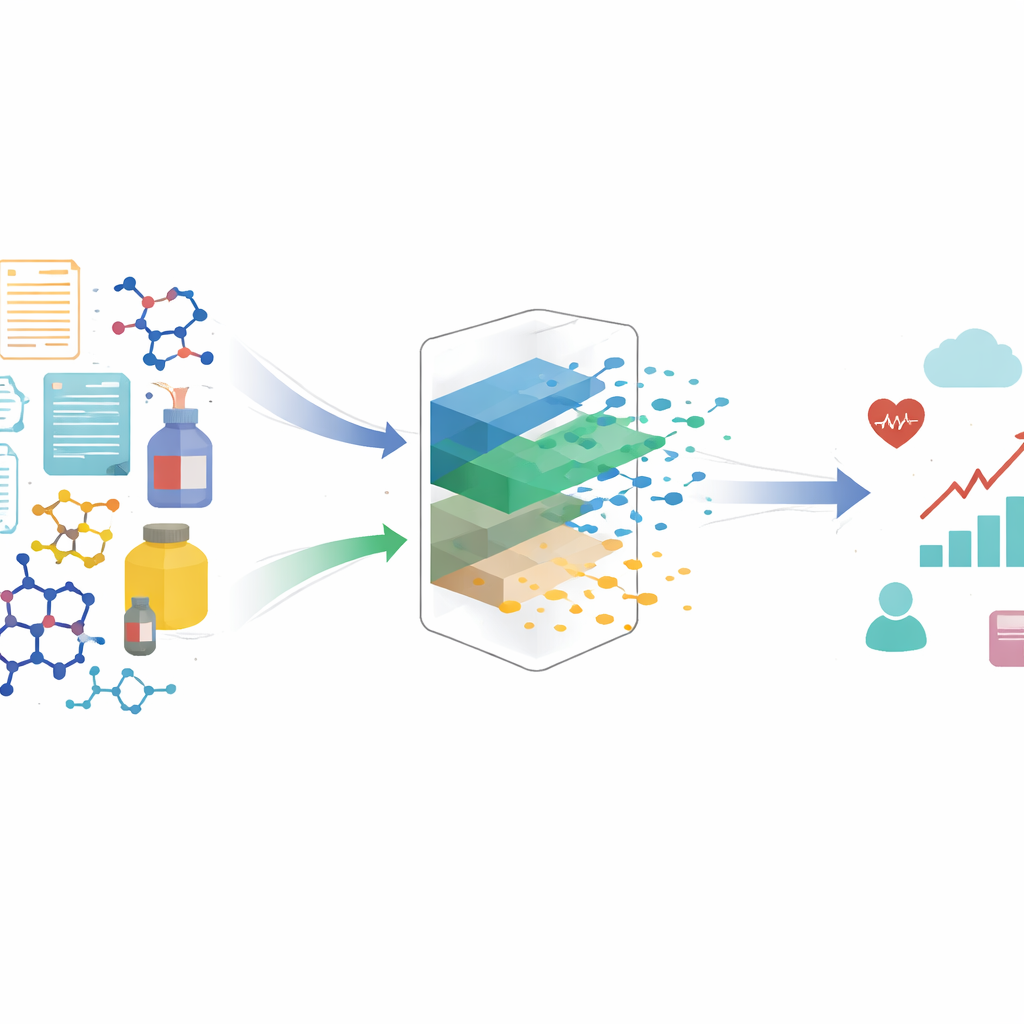
Muchas de las elecciones que afectan nuestras vidas están guiadas por algoritmos: qué productos vemos en línea, qué fármacos se prueban o incluso cómo se evalúan los tratamientos médicos. Estos sistemas a menudo tratan objetos complejos —como una reseña escrita, una molécula o la descripción de un producto— como si cada detalle tuviera la misma importancia. Este artículo muestra que ese enfoque puede distorsionar silenciosamente nuestra comprensión de causa y efecto, y presenta un nuevo método que ayuda a los algoritmos a centrarse en lo que realmente impulsa los resultados, no en detalles que distraen.
El problema de confundir estilo con sustancia
Cuando los científicos o los profesionales de datos estiman el efecto de un “tratamiento” (por ejemplo, mostrar un anuncio, recomendar un producto o prescribir un fármaco), a menudo asumen que el tratamiento puede describirse con un número o una categoría sencilla. En la realidad, los tratamientos son con frecuencia objetos ricos y estructurados: una reseña completa, una imagen o una estructura química compleja. Ocultos dentro de estos objetos hay aspectos distintos: algunos influyen genuinamente en el resultado (por ejemplo, cuán positiva es una reseña), mientras que otros cambian principalmente la apariencia o el tono del objeto (como el estilo de escritura). Los autores muestran que si alimentamos estos tratamientos ricos directamente a modelos causales estándar, los modelos pueden confundir esos aspectos estilísticos o no causales con los verdaderos impulsores del cambio, incluso cuando hemos medido cuidadosamente todos los factores de confusión evidentes. El resultado son estimaciones sesgadas de lo que realmente funciona.
Separar la señal significativa del ruido que distrae
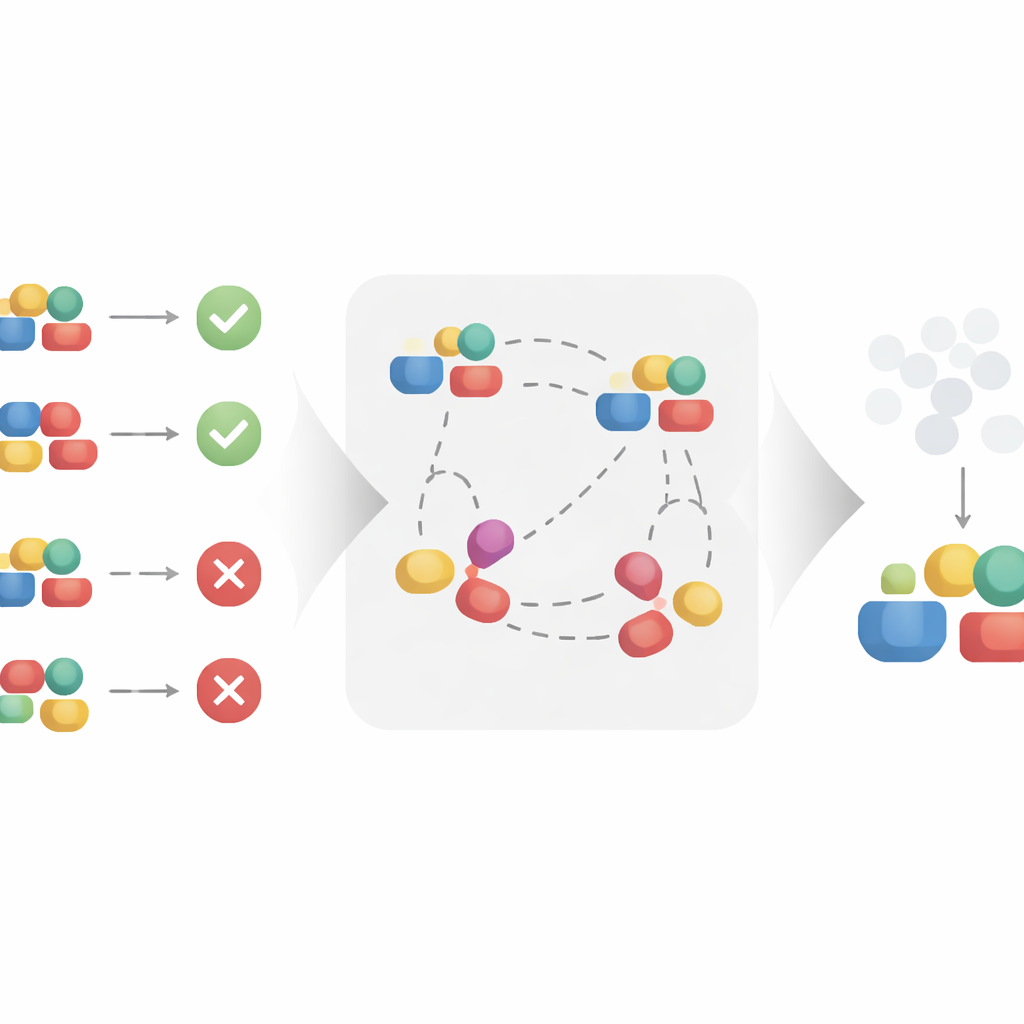
Para abordar esto, el artículo distingue entre factores ocultos “causales”, es decir, las partes de un tratamiento que afectan genuinamente el resultado, y factores “no causales”, que pueden estar correlacionados con los resultados pero no los modifican en realidad. En una reseña de producto, el tono o el sentimiento son causales para las ventas, mientras que los adornos y la elección de palabras pueden no serlo. En una molécula de fármaco, ciertas características estructurales pueden impulsar el alivio de los síntomas, mientras que otras son incidentales. La idea clave es que el tratamiento que observamos es una mezcla de ambos tipos de factores. Si un modelo aprende directamente de esa mezcla, los aspectos no causales pueden actuar como sustitutos de variables de fondo y desviar las estimaciones de efecto. Los autores prueban matemáticamente que, para evitar el sesgo, primero hay que transformar el tratamiento complejo en una nueva representación que preserve solo la información causal y descarte el resto.
Aprender mejores representaciones mediante comparaciones
Los autores proponen un enfoque de aprendizaje contrastivo para construir automáticamente esta representación más limpia. En lugar de tratar cada tratamiento de manera aislada, el método observa pares de ejemplos similares y disímiles. Dos tratamientos que aparecen en el mismo contexto y conducen a resultados muy parecidos se tratan como si compartieran los mismos factores causales subyacentes, incluso si sus detalles superficiales difieren. Al atraer estos pares similares en un espacio de representación aprendido y separar los pares que comparten el mismo contexto pero conducen a resultados distintos, el algoritmo se ve incentivado a conservar lo que importa para el resultado e ignorar la variación superficial. Bajo supuestos matemáticos razonables, los autores demuestran que este proceso recupera exactamente la parte causal del tratamiento y filtra la parte no causal, haciéndolo apropiado para la estimación no sesgada del efecto causal.
Probar la idea en entornos sintéticos y del mundo real
Para comprobar si esta teoría funciona en la práctica, los autores aplican su método a tres tipos de datos. Primero, construyen un conjunto de datos sintético donde los componentes causales y no causales del tratamiento son conocidos por diseño. Esto les permite probar si su método puede realmente ignorar las piezas no causales incluso cuando se añade ruido a los resultados. A continuación, examinan datos de moléculas, donde los tratamientos son estructuras químicas y los resultados se relacionan con propiedades como la efectividad, y un conjunto de recomendaciones de abrigos, donde los elementos son productos en un mercado en línea. En estos distintos escenarios, comparan su modelo contrastivo con modelos causales estándar y con un competidor reciente y potente diseñado para tratamientos estructurados. Si bien todos los métodos pueden ajustar razonablemente bien los datos observados, solo el enfoque contrastivo se mantiene estable cuando se perturban las partes no causales del tratamiento, lo que indica que ha aprendido con éxito a centrarse en los verdaderos impulsores causales.
Lo que esto significa para sistemas más inteligentes y justos
Para un lector general, el mensaje principal es que no todos los detalles en los datos tienen la misma importancia. Los sistemas que guían decisiones —desde lo que ves en un feed de compras hasta qué candidatos a fármacos avanzan— pueden dejarse engañar por patrones que parecen predictivos pero no son verdaderamente causales. Este artículo muestra que, enseñando a los modelos a comparar situaciones y resultados similares, podemos construir representaciones de tratamientos complejos que se concentran en las palancas reales del cambio. A su vez, esto conduce a estimaciones más fiables de “qué funciona”, abriendo la puerta a mejores recomendaciones de productos, un descubrimiento de fármacos más eficiente y sistemas de IA más confiables que razonan sobre causa y efecto en lugar de correlaciones superficiales.
Cita: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
Palabras clave: inferencia causal, aprendizaje de representaciones, aprendizaje contrastivo, tratamientos de alta dimensión, aprendizaje automático