Clear Sky Science · de
Kontrastive Repräsentationen strukturierter Behandlungen
Warum diese Forschung für alltägliche Entscheidungen wichtig ist
Viele der Entscheidungen, die unser Leben beeinflussen, werden von Algorithmen gesteuert: welche Produkte wir online sehen, welche Wirkstoffe getestet werden oder wie medizinische Behandlungen bewertet werden. Diese Systeme behandeln komplexe Objekte – wie eine geschriebene Bewertung, ein Molekül oder eine Produktbeschreibung – oft so, als sei jedes Detail gleichermaßen wichtig. Dieser Artikel zeigt, dass ein solches Vorgehen unser Verständnis von Ursache und Wirkung stillschweigend verzerren kann, und stellt eine neue Methode vor, die Algorithmen hilft, sich auf das zu konzentrieren, was Ergebnisse tatsächlich antreibt, statt auf ablenkende Details.
Das Problem, Stil mit Substanz zu verwechseln
Wenn Wissenschaftler oder Datenwissenschaftler den Effekt einer „Behandlung“ schätzen (zum Beispiel eine Anzeige zeigen, ein Produkt empfehlen oder ein Medikament verschreiben), nehmen sie häufig an, die Behandlung lasse sich durch eine einfache Zahl oder Kategorie beschreiben. In Wirklichkeit sind Behandlungen oft reichhaltige, strukturierte Objekte: eine ganze Textbewertung, ein Bild oder eine komplexe chemische Struktur. In diesen Objekten verbergen sich unterschiedliche Aspekte: Einige beeinflussen tatsächlich das Ergebnis (etwa wie positiv eine Bewertung ist), andere verändern vor allem das Erscheinungsbild oder den Stil (etwa Schreibweise). Die Autoren zeigen, dass wenn solche komplexen Behandlungen direkt in Standard-Kausalmodelle eingespeist werden, die Modelle diese stilistischen oder nicht-kausalen Aspekte für wahre Treiber von Veränderungen halten können, selbst wenn alle offensichtlichen Confounder sorgfältig gemessen wurden. Das Ergebnis sind verzerrte Schätzungen dessen, was wirklich wirkt.
Das sinnvolle Signal vom ablenkenden Rauschen trennen
Um dem zu begegnen, unterscheidet der Artikel zwischen „kausalen“ verborgenen Faktoren – jenen Teilen einer Behandlung, die das Ergebnis tatsächlich beeinflussen – und „nicht-kausalen“ Faktoren, die zwar mit dem Ergebnis korrelieren können, es aber nicht verändern. Bei einer Produktbewertung ist Tonfall oder Sentiment kausal für Verkäufe, während Stilmittel und Wortwahl oft nicht kausal sind. Bei einem Wirkstoffmolekül können bestimmte strukturelle Merkmale die Linderung von Symptomen antreiben, während andere zufällig sind. Die zentrale Idee ist, dass die beobachtete Behandlung eine Mischung aus beiden Arten von Faktoren ist. Lernt ein Modell direkt aus dieser Mischung, können nicht-kausale Aspekte als Stellvertreter für Hintergrundvariablen fungieren und Effektabschätzungen in die Irre führen. Die Autoren beweisen mathematisch, dass man zur Vermeidung von Verzerrungen die komplexe Behandlung zuerst in eine neue Repräsentation transformieren muss, die nur die kausale Information bewahrt und den Rest verwirft.
Bessere Repräsentationen durch Vergleiche lernen
Die Autoren schlagen einen kontrastiven Lernansatz vor, um diese sauberere Repräsentation automatisch zu erstellen. Statt jede Behandlung isoliert zu betrachten, betrachtet die Methode Paare ähnlicher und unähnlicher Beispiele. Zwei Behandlungen, die im selben Kontext auftreten und zu sehr ähnlichen Ergebnissen führen, werden so behandelt, als teilten sie dieselben zugrunde liegenden kausalen Faktoren, selbst wenn sich ihre Oberflächenmerkmale unterscheiden. Indem ähnliche Paare im gelernten Repräsentationsraum einander angenähert und Paare, die denselben Kontext teilen, aber zu unterschiedlichen Ergebnissen führen, auseinandergezogen werden, wird der Algorithmus dazu angeregt, das beizubehalten, was für das Ergebnis wichtig ist, und oberflächliche Variation zu ignorieren. Unter vernünftigen mathematischen Annahmen beweisen die Autoren, dass dieser Prozess genau den kausalen Teil der Behandlung rekonstruiert und den nicht-kausalen Teil herausfiltert, wodurch er sich für unverzerrte Kausaleffekt-Schätzungen eignet.
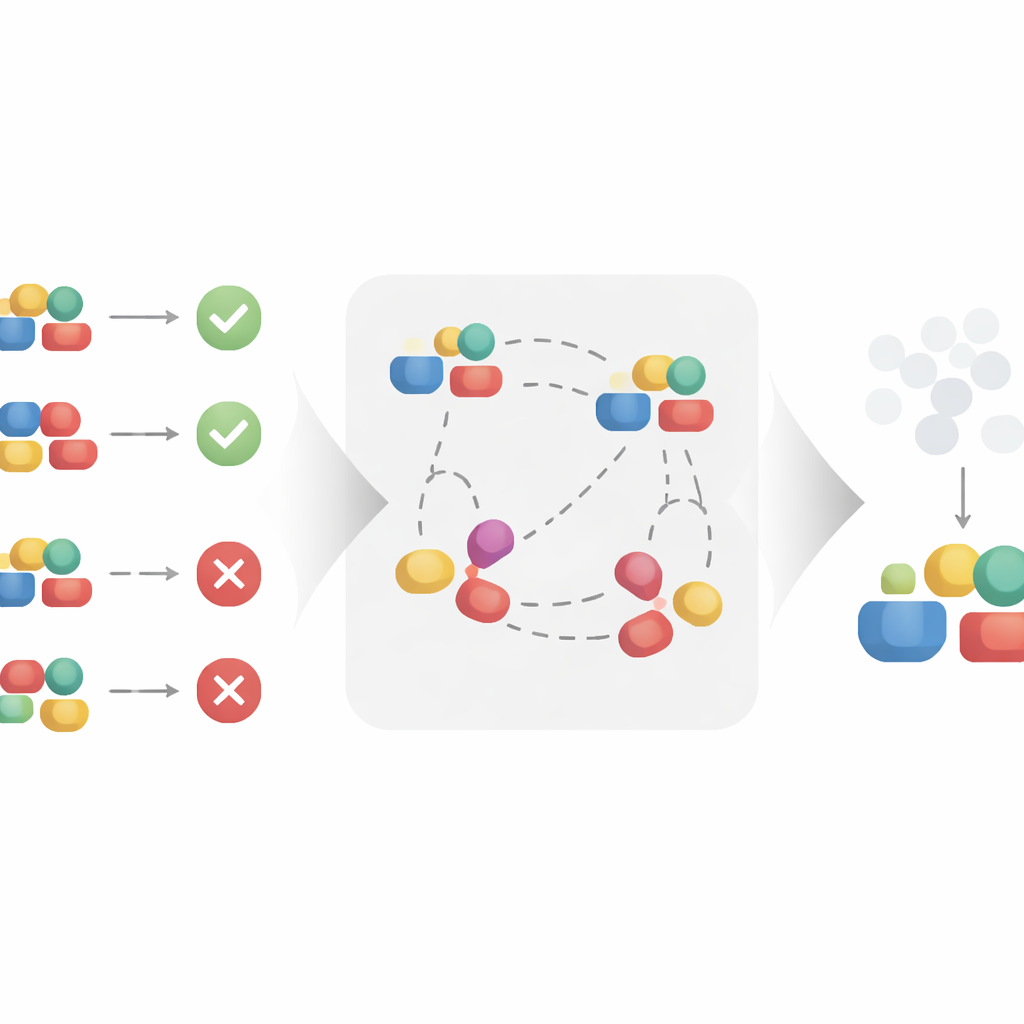
Die Idee in synthetischen und realen Szenarien testen
Um zu prüfen, ob diese Theorie praktisch hält, wenden die Autoren ihre Methode auf drei Datentypen an. Zuerst konstruieren sie einen synthetischen Datensatz, bei dem die kausalen und nicht-kausalen Komponenten der Behandlung per Design bekannt sind. So können sie testen, ob ihre Methode nicht-kausale Teile wirklich ignoriert, selbst wenn Rauschen zu den Ergebnissen hinzugefügt wird. Anschließend untersuchen sie Moleküldaten, bei denen Behandlungen chemische Strukturen sind und Ergebnisse Eigenschaften wie Wirksamkeit betreffen, sowie einen Datensatz zur Mantel-Empfehlung, bei dem Artikel Produkte auf einem Online-Marktplatz sind. In diesen unterschiedlichen Szenarien vergleichen sie ihr kontrastives Modell mit Standard-Kausalmodellen und mit einem starken neueren Konkurrenten, der für strukturierte Behandlungen entwickelt wurde. Während alle Methoden die beobachteten Daten einigermaßen gut anpassen können, bleibt nur der kontrastive Ansatz stabil, wenn die nicht-kausalen Teile der Behandlung gestört werden, was darauf hinweist, dass er erfolgreich gelernt hat, sich auf die tatsächlichen kausalen Treiber zu konzentrieren.
Was das für klügere, gerechtere Systeme bedeutet
Für eine breite Leserschaft lautet die zentrale Botschaft: Nicht alle Details in Daten sind gleichwertig. Systeme, die Entscheidungen steuern – von dem, was Sie in einem Einkaufsfeed sehen, bis zu welchen Medikamentenkandidaten vorangebracht werden – können durch Muster in die Irre geführt werden, die zwar vorhersagend erscheinen, aber nicht wirklich kausal sind. Dieser Artikel zeigt, dass wir Modelle durch das Vergleichen ähnlicher Situationen und Ergebnisse lehren können, Repräsentationen komplexer Behandlungen zu bauen, die sich auf die wahren Stellhebel der Veränderung konzentrieren. Das führt zu verlässlicheren Schätzungen von „was wirkt“ und ebnet den Weg für bessere Produktempfehlungen, effizientere Wirkstoffsuche und vertrauenswürdigere KI-Systeme, die sich an Ursache und Wirkung statt an oberflächlichen Korrelationen orientieren.
Zitation: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
Schlüsselwörter: kausale Inferenz, Repräsentationslernen, kontrastives Lernen, hochdimensionale Behandlungen, maschinelles Lernen