Clear Sky Science · ru
Контрастные представления структурированных воздействий
Почему это исследование важно для повседневных решений
Многие решения, влияющие на нашу жизнь, принимаются с участием алгоритмов: какие товары мы видим онлайн, какие лекарства проходят тестирование и даже как оцениваются медицинские процедуры. Такие системы часто рассматривают сложные объекты — например, текстовый отзыв, молекулу или описание товара — так, будто каждая деталь одинаково важна. В статье показано, что такой подход может незаметно исказить наше понимание причинно-следственных связей, и предложен новый метод, помогающий алгоритмам фокусироваться на том, что действительно определяет результаты, а не на отвлекающих деталях.
Проблема смешения стиля и сути
Когда учёные или аналитики оценивают эффект «воздействия» (например, показ рекламы, рекомендация товара или назначение лекарства), они часто предполагают, что воздействие можно описать простым числом или категорией. На практике воздействие часто представляет собой богатый, структурированный объект: полный текст отзыва, изображение или сложная химическая структура. Внутри таких объектов скрыты разные аспекты: одни действительно влияют на результат (например, насколько положителен отзыв), другие в основном меняют внешний вид или звучание (стиль написания). Авторы показывают, что если подавать эти сложные воздействия напрямую в стандартные каузальные модели, модели могут принять стилистические или неконтасальные аспекты за истинные причины изменений, даже при тщательном учёте очевидных факторов смешения. В результате оценки того, что действительно работает, оказываются смещёнными.
Отделение значимого сигнала от отвлекающего шума
Чтобы решить эту проблему, статья различает «каузальные» скрытые факторы — части воздействия, которые действительно влияют на результат — и «некaузальные» факторы, которые могут коррелировать с результатом, но фактически его не меняют. Для отзыва о товаре тональность или сентимент могут быть каузальными для продаж, тогда как вычурность и выбор слов могут не иметь значения. Для молекулы некоторые структурные элементы могут быть ответственны за облегчение симптомов, тогда как другие — случайны. Ключевая идея заключается в том, что наблюдаемое воздействие — это смесь обоих типов факторов. Если модель обучается на этой смеси напрямую, некaузальные аспекты могут выступать в роли суррогатов фоновых переменных и вводить в заблуждение при оценке эффектов. Авторы математически доказывают, что для избегания смещения необходимо сначала преобразовать сложное воздействие в новое представление, которое сохраняет только каузальную информацию и отбрасывает остальное.
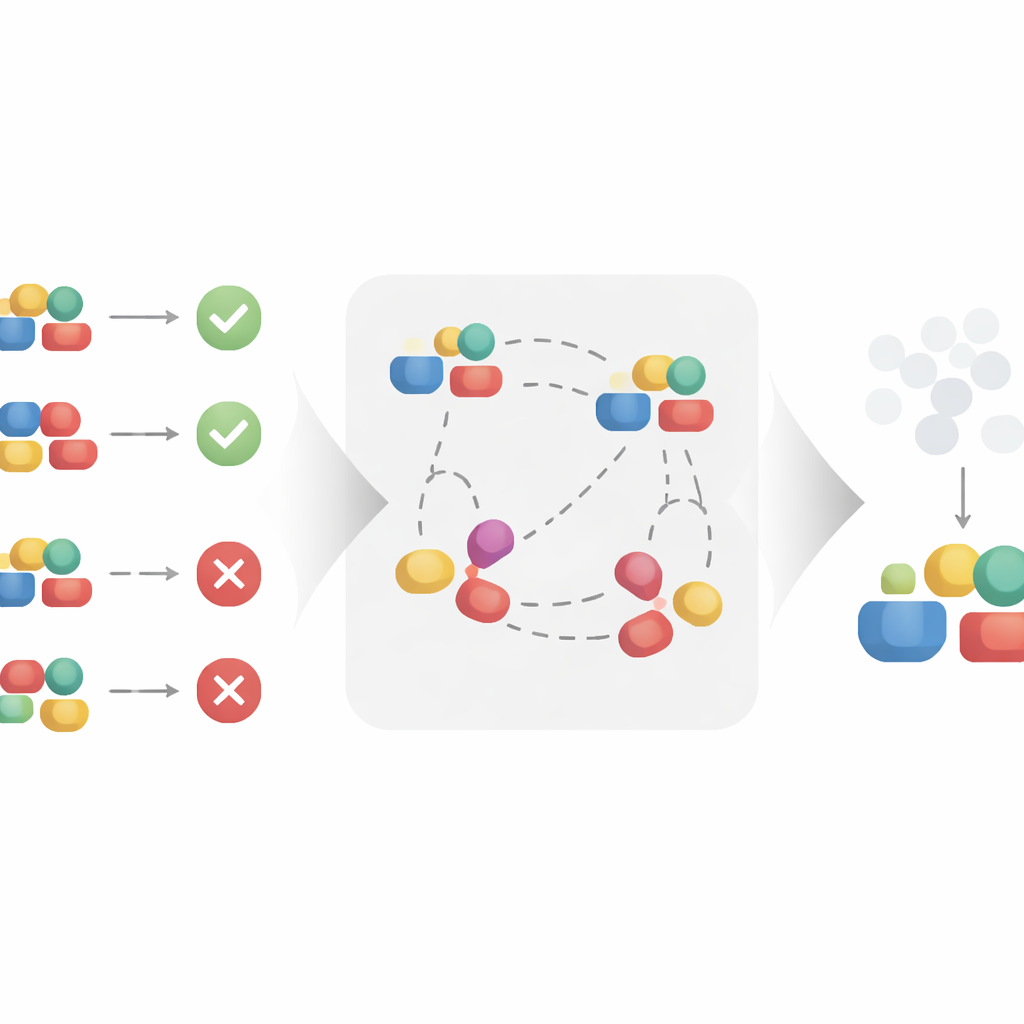
Обучение лучших представлений через сравнения
Авторы предлагают метод контрастивного обучения для автоматического построения такого очищенного представления. Вместо того чтобы рассматривать каждое воздействие по отдельности, метод анализирует пары похожих и непохожих примеров. Два воздействия, появившиеся в одном контексте и приводящие к очень похожим исходам, рассматриваются как имеющие одни и те же скрытые каузальные факторы, даже если их поверхностные детали различаются. Сближая такие похожие пары в пространстве обученных представлений и отталкивая пары, которые имеют тот же контекст, но приводят к разным исходам, алгоритм вынужденно сохраняет то, что важно для результата, и игнорирует поверхностные вариации. При разумных математических допущениях авторы доказывают, что этот процесс восстанавливает именно каузальную часть воздействия и фильтрует некaузальную часть, делая представление пригодным для несмещённой оценки каузального эффекта.
Тестирование идеи на синтетических и реальных данных
Чтобы проверить, работает ли теория на практике, авторы применяют свой метод к трём типам данных. Сначала они конструируют синтетический набор данных, где каузальные и некaузальные компоненты воздействия заранее известны по дизайну. Это позволяет испытать, может ли метод действительно игнорировать некaузальные элементы даже при добавлении шума в результаты. Затем они исследуют данные о молекулах, где воздействия — это химические структуры, а исходы связаны с такими свойствами, как эффективность, и набор данных о рекомендациях пальто, где предметы — товары на онлайн-площадке. В этих разных сценариях они сравнивают свой контрастивный подход со стандартными каузальными моделями и с сильным недавним конкурентом, разработанным для структурированных воздействий. Хотя все методы могут удовлетворительно подгонять наблюдаемые данные, только контрастивный подход остаётся устойчивым при искажении некaузальных частей воздействия, что свидетельствует о том, что он успешно научился фокусироваться на подлинных каузальных драйверах.
Что это означает для более умных и справедливых систем
Для широкой аудитории главный вывод в том, что не все детали данных одинаково важны. Системы, которые определяют решения — от того, что вы видите в ленте покупок до того, какие кандидаты на лекарство продвигаются дальше — могут быть введены в заблуждение паттернами, которые выглядят предсказуемыми, но на самом деле не являются каузальными. В статье показано, что обучая модели сравнивать похожие ситуации и исходы, можно строить представления сложных воздействий, сосредоточенные на истинных рычагИах изменения. Это, в свою очередь, приводит к более надёжным оценкам «что работает», что открывает путь к лучшим рекомендациям товаров, более эффективному открытию лекарств и более доверенным системам ИИ, которые рассуждают о причинах и следствиях, а не о поверхностных корреляциях.
Цитирование: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
Ключевые слова: каузальное вывод, обучение представлений, контрастивное обучение, высокоразмерные воздействия, машинное обучение