Clear Sky Science · nl
Contrastieve representaties van gestructureerde behandelingen
Waarom dit onderzoek belangrijk is voor alledaagse beslissingen
Veel keuzes die ons leven sturen worden gemaakt met algoritmen: welke producten we online te zien krijgen, welke medicijnen worden getest, zelfs hoe medische behandelingen worden beoordeeld. Deze systemen behandelen vaak complexe objecten—zoals een geschreven recensie, een molecuul of een productbeschrijving—alsof elk detail even belangrijk is. Dit artikel laat zien dat zo’n aanpak stilletjes ons begrip van oorzaak en gevolg kan vervormen, en introduceert een nieuwe methode die algoritmen helpt te focussen op wat echt de uitkomsten aanstuurt, niet op afleidende details.
Het probleem van stijl verwarren met inhoud
Wanneer wetenschappers of datawetenschappers het effect van een “behandeling” schatten (bijvoorbeeld het tonen van een advertentie, het aanbevelen van een product of het voorschrijven van een medicijn), gaan ze vaak uit van een eenvoudige numerieke of categorische beschrijving van die behandeling. In werkelijkheid zijn behandelingen vaak rijke, gestructureerde objecten: een volledige tekstrecensie, een afbeelding of een complexe chemische structuur. Verborgen in deze objecten zitten verschillende aspecten: sommige beïnvloeden de uitkomst daadwerkelijk (zoals hoe positief een recensie is), terwijl andere vooral de vorm of stijl veranderen (zoals de schrijfstijl). De auteurs laten zien dat als we deze rijke behandelingen direct in standaard causale modellen stoppen, de modellen deze stilistische of niet-causale aspecten kunnen verwarren met echte aanjagers van verandering, zelfs wanneer we alle voor de hand liggende confounders zorgvuldig hebben gemeten. Het resultaat zijn vertekende schattingen van wat echt werkt.
Het betekenisvolle signaal scheiden van afleidende ruis
Om dit probleem aan te pakken, maakt het artikel onderscheid tussen “causale” verborgen factoren—die onderdelen van een behandeling die daadwerkelijk de uitkomst beïnvloeden—en “niet-causale” factoren, die wel gecorreleerd kunnen zijn met uitkomsten maar deze niet echt veranderen. Voor een productrecensie is de toon of sentiment causaal voor de verkoop, terwijl opsmuk en woordkeuze dat misschien niet zijn. Voor een geneesmiddel kunnen bepaalde structurele kenmerken symptoomverlichting aandrijven, terwijl andere toevallig zijn. Het sleutelidee is dat de geobserveerde behandeling een mengsel van beide soorten factoren is. Als een model direct uit dit mengsel leert, kunnen niet-causale aspecten fungeren als plaatsvervangers voor achtergrondvariabelen en effectschattingen misleiden. De auteurs bewijzen wiskundig dat om bias te voorkomen, men eerst de complexe behandeling moet transformeren naar een nieuwe representatie die alleen de causale informatie behoudt en de rest wegfiltert.
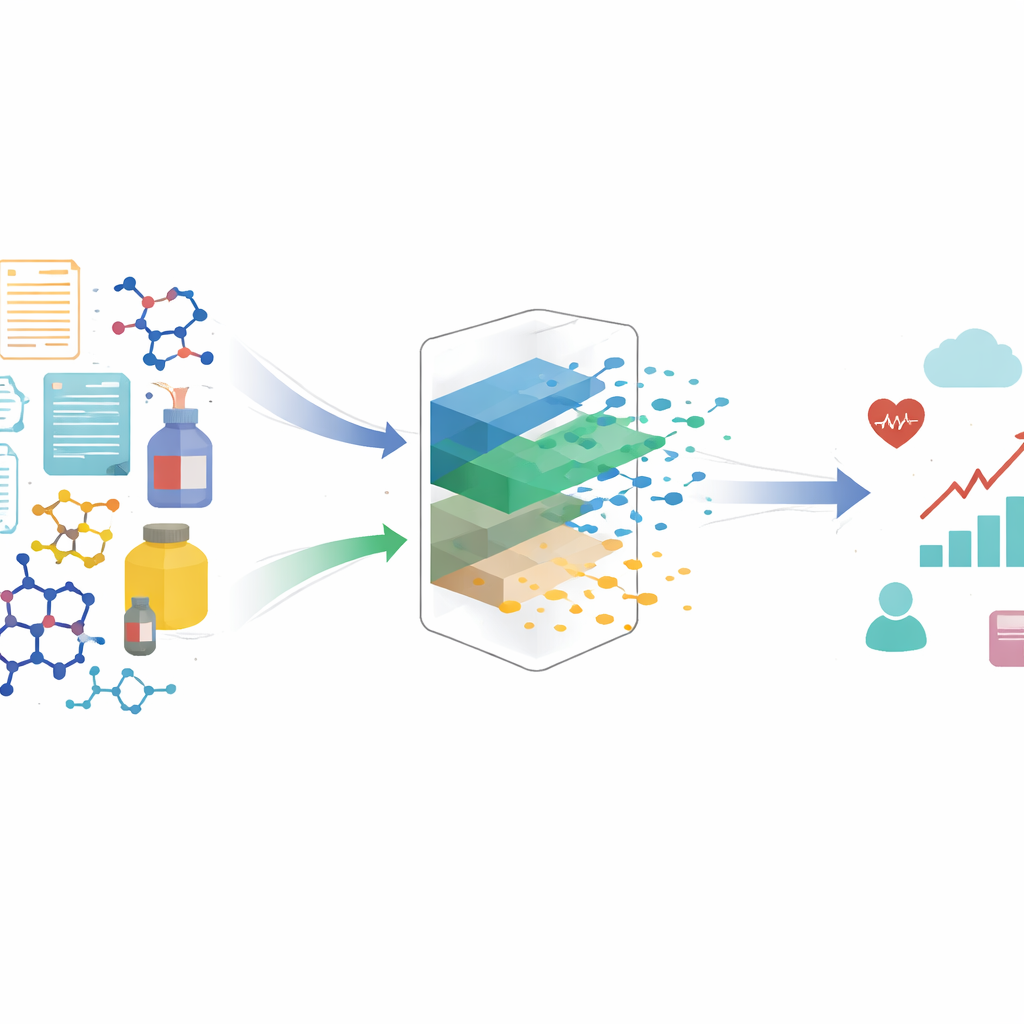
Betere representaties leren via vergelijkingen
De auteurs stellen een contrastieve leerbenadering voor om deze schonere representatie automatisch op te bouwen. In plaats van elke behandeling geïsoleerd te behandelen, bekijkt de methode paren van vergelijkbare en niet-vergelijkbare voorbeelden. Twee behandelingen die in dezelfde context voorkomen en tot zeer vergelijkbare uitkomsten leiden, worden behandeld alsof ze dezelfde onderliggende causale factoren delen, ook als hun uiterlijke details verschillen. Door deze vergelijkbare paren dichter bij elkaar te brengen in een geleerde representatieruimte, en paren die in dezelfde context zitten maar verschillende uitkomsten hebben uit elkaar te duwen, wordt het algoritme aangemoedigd om te behouden wat voor de uitkomst belangrijk is en oppervlakkige variatie te negeren. Onder redelijke wiskundige aannames laten de auteurs zien dat dit proces precies het causale deel van de behandeling terugvindt en het niet-causale deel filtert, waardoor het geschikt is voor onbevooroordeelde schattingen van causale effecten.
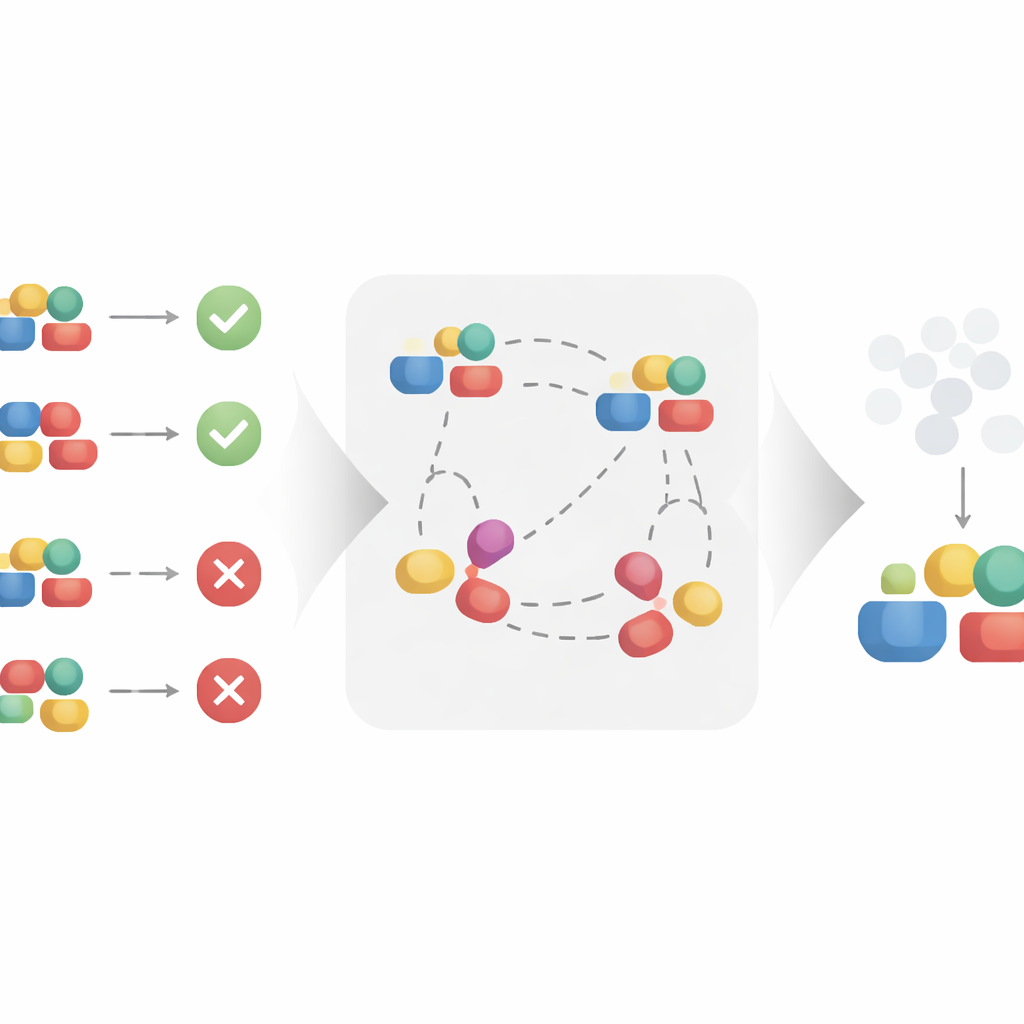
De methode testen in synthetische en realistische situaties
Om na te gaan of deze theorie in de praktijk standhoudt, passen de auteurs hun methode toe op drie soorten data. Eerst construeren ze een synthetische dataset waarin de causale en niet-causale componenten van de behandeling ontwerpgewijs bekend zijn. Dit stelt hen in staat te testen of hun methode niet-causale delen echt kan negeren, zelfs wanneer ruis aan de uitkomsten wordt toegevoegd. Vervolgens onderzoeken ze molecuulgegevens, waarbij behandelingen chemische structuren zijn en uitkomsten betreft eigenschappen zoals effectiviteit, en een dataset voor jasaanbevelingen, waarin items producten op een online marktplaats zijn. In al deze uiteenlopende settings vergelijken ze hun contrastieve model met standaard causale modellen en met een sterke recente concurrent die specifiek voor gestructureerde behandelingen is ontworpen. Hoewel alle methoden de geobserveerde data redelijk goed kunnen fitten, blijft alleen de contrastieve aanpak stabiel wanneer de niet-causale delen van de behandeling worden verstoord, wat erop wijst dat het met succes heeft geleerd zich te concentreren op de echte causale aanjagers.
Wat dit betekent voor slimmere, eerlijkere systemen
Voor een algemeen publiek is de belangrijkste boodschap dat niet alle details in data evenveel betekenen. Systemen die beslissingen sturen—van wat je in een winkelfeed ziet tot welke medicijnkandidaten verder ontwikkeld worden—kunnen misleid worden door patronen die voorspellend lijken maar niet echt causaal zijn. Dit artikel toont aan dat we door modellen te leren vergelijkbare situaties en uitkomsten te vergelijken, representaties van complexe behandelingen kunnen bouwen die zich concentreren op de echte hefboompunten van verandering. Dat leidt op zijn beurt tot betrouwbaardere schattingen van “wat werkt”, en maakt de weg vrij voor betere productaanbevelingen, efficiëntere geneesmiddelengroei en betrouwbaardere AI-systemen die redeneren over oorzaak en gevolg in plaats van oppervlakkige correlaties.
Bronvermelding: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
Trefwoorden: causale inferentie, representatie-leren, contrastief leren, hoog-dimensionale behandelingen, machine learning