Clear Sky Science · fr
Représentations contrastives des traitements structurés
Pourquoi cette recherche compte pour les décisions ordinaires
Beaucoup de choix qui influencent nos vies sont guidés par des algorithmes : quels produits nous voyons en ligne, quels médicaments sont testés, voire comment les traitements médicaux sont évalués. Ces systèmes traitent souvent des objets complexes — comme une critique écrite, une molécule ou la description d’un produit — comme si chaque détail avait la même importance. Cet article montre qu’une telle approche peut fausser discrètement notre compréhension de la causalité, et propose une nouvelle méthode qui aide les algorithmes à se concentrer sur ce qui pilote réellement les résultats, et non sur des détails distrayants.
Le problème de la confusion entre style et substance
Lorsque des scientifiques ou des data scientists estiment l’effet d’un “traitement” (par exemple afficher une annonce, recommander un produit ou prescrire un médicament), ils supposent souvent que le traitement se décrit par un nombre simple ou une catégorie. En réalité, les traitements sont fréquemment des objets riches et structurés : une critique complète, une image ou une structure chimique complexe. À l’intérieur de ces objets se cachent différents aspects : certains influencent réellement le résultat (comme le degré de positivité d’une critique), tandis que d’autres modifient surtout l’apparence ou le style (comme le ton ou le choix des mots). Les auteurs montrent que si l’on alimente directement ces traitements riches dans des modèles causaux standard, les modèles peuvent confondre ces aspects stylistiques ou non causaux avec de vrais facteurs explicatifs, même lorsque l’on a mesuré avec soin tous les facteurs de confusion évidents. Le résultat est des estimations biaisées de ce qui fonctionne réellement.
Séparer le signal significatif du bruit distrayant
Pour résoudre ce problème, l’article distingue les facteurs latents “ causaux ” — les parties d’un traitement qui affectent réellement le résultat — des facteurs “ non causaux ”, qui peuvent être corrélés aux résultats sans pour autant les modifier. Pour une critique de produit, le ton ou le sentiment est causal pour les ventes, tandis que les fioritures ou le choix des mots peuvent ne pas l’être. Pour une molécule médicamenteuse, certaines caractéristiques structurelles peuvent provoquer un soulagement des symptômes, tandis que d’autres sont accessoires. L’idée clé est que le traitement observé est un mélange de ces deux types de facteurs. Si un modèle apprend directement à partir de ce mélange, les aspects non causaux peuvent jouer le rôle de substituts pour des variables de fond et induire en erreur les estimations d’effet. Les auteurs prouvent mathématiquement que, pour éviter le biais, il faut d’abord transformer le traitement complexe en une nouvelle représentation qui préserve uniquement l’information causale et écarte le reste.
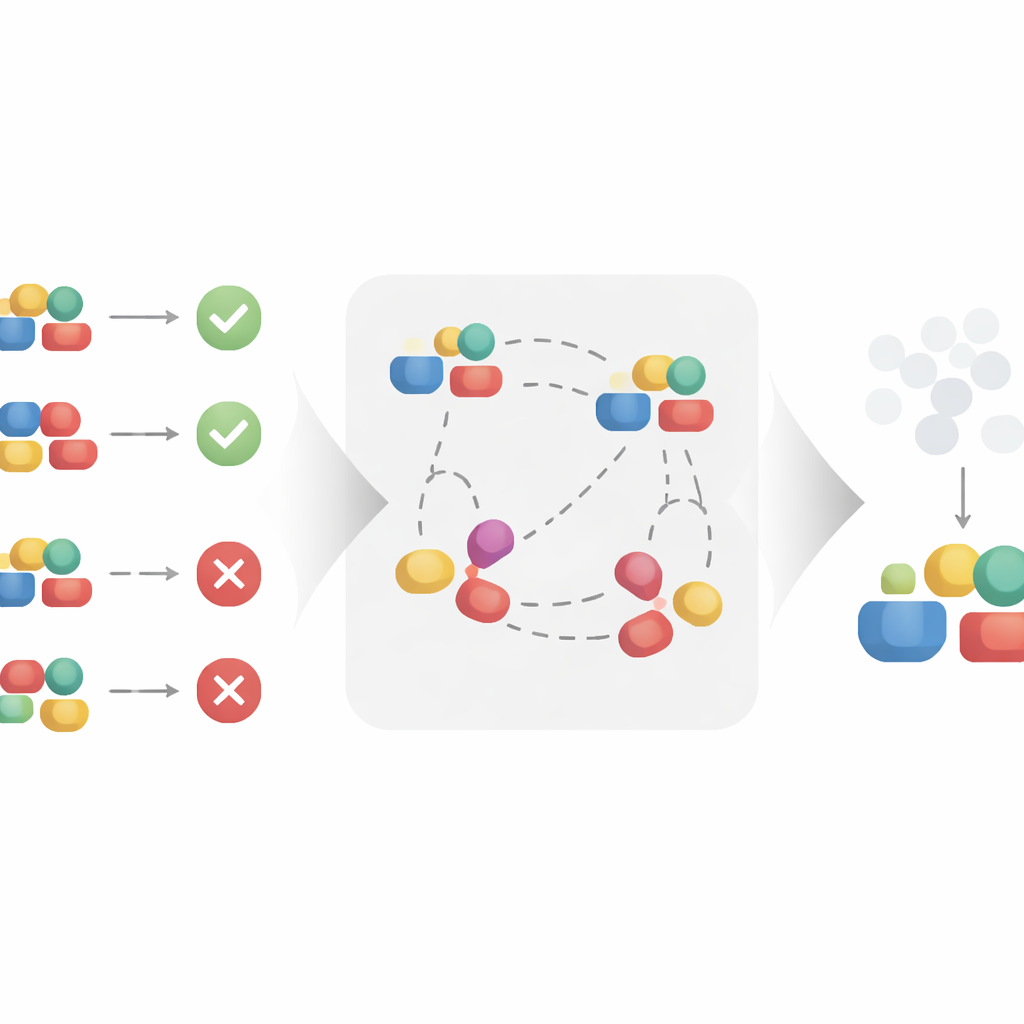
Apprendre de meilleures représentations par comparaison
Les auteurs proposent une approche d’apprentissage contrastif pour construire automatiquement cette représentation plus propre. Plutôt que de traiter chaque traitement isolément, la méthode examine des paires d’exemples similaires et dissemblables. Deux traitements apparaissant dans le même contexte et conduisant à des résultats très proches sont considérés comme partageant les mêmes facteurs causaux sous-jacents, même si leurs détails de surface diffèrent. En rapprochant ces paires similaires dans un espace de représentation appris, et en éloignant les paires qui partagent le même contexte mais mènent à des résultats différents, l’algorithme est encouragé à conserver ce qui compte pour le résultat et à ignorer la variation superficielle. Sous des hypothèses mathématiques raisonnables, les auteurs démontrent que ce procédé récupère exactement la partie causale du traitement et filtre la partie non causale, ce qui le rend adapté à une estimation non biaisée des effets causaux.
Tester l’idée sur des données synthétiques et du monde réel
Pour vérifier si cette théorie fonctionne en pratique, les auteurs appliquent leur méthode à trois types de données. D’abord, ils construisent un jeu de données synthétique où les composantes causales et non causales du traitement sont connues par construction. Cela leur permet de tester si leur méthode peut réellement ignorer les pièces non causales même lorsque du bruit est ajouté aux résultats. Ensuite, ils examinent des données de molécules, où les traitements sont des structures chimiques et les résultats liés à des propriétés comme l’efficacité, et un jeu de données de recommandations de manteaux, où les éléments sont des produits sur une place de marché en ligne. Dans ces contextes variés, ils comparent leur modèle contrastif aux modèles causaux standard et à un concurrent récent performant conçu pour les traitements structurés. Alors que toutes les méthodes peuvent ajuster raisonnablement bien les données observées, seule l’approche contrastive reste stable lorsque les parties non causales du traitement sont perturbées, indiquant qu’elle a appris à se concentrer sur les véritables moteurs causaux.
Ce que cela signifie pour des systèmes plus intelligents et plus équitables
Pour un lecteur général, le message principal est que tous les détails d’un jeu de données ne se valent pas. Les systèmes qui orientent des décisions — de ce que vous voyez dans un fil d’achats à quels candidats-médicaments sont avancés — peuvent être trompés par des motifs qui semblent prédictifs mais qui ne sont pas réellement causaux. Cet article montre qu’en apprenant aux modèles à comparer des situations et des résultats similaires, on peut construire des représentations de traitements complexes qui se concentrent sur les véritables leviers du changement. En retour, cela mène à des estimations plus fiables de « ce qui fonctionne », ouvrant la voie à de meilleures recommandations de produits, à une découverte de médicaments plus efficace et à des systèmes d’IA plus dignes de confiance qui raisonnent en termes de cause à effet plutôt que de simples corrélations de surface.
Citation: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
Mots-clés: inférence causale, apprentissage de représentations, apprentissage contrastif, traitements de haute dimension, apprentissage automatique