Clear Sky Science · en
Contrastive representations of structured treatments
Why this research matters for everyday decisions
Many of the choices that affect our lives are guided by algorithms: which products we see online, which drugs are tested, even how medical treatments are evaluated. These systems often treat complex objects—like a written review, a molecule, or a product description—as if every detail is equally important. This paper shows that such an approach can quietly distort our understanding of cause and effect, and introduces a new method that helps algorithms focus on what truly drives outcomes, not on distracting details.
The problem of confusing style with substance
When scientists or data scientists estimate the effect of a “treatment” (for example, showing an ad, recommending a product, or prescribing a drug), they often assume that the treatment can be described with a simple number or category. In reality, treatments are frequently rich, structured objects: a full text review, an image, or a complex chemical structure. Hidden inside these objects are different aspects: some genuinely influence the outcome (such as how positive a review is), while others mostly change how the object looks or sounds (such as writing style). The authors show that if we feed these rich treatments directly into standard causal models, the models can mistake these stylistic or non-causal aspects for true drivers of change, even when we have carefully measured all obvious confounding factors. The result is biased estimates of what really works.
Separating the meaningful signal from distracting noise
To tackle this, the paper distinguishes between “causal” hidden factors—those parts of a treatment that genuinely affect the outcome—and “non-causal” factors, which may be correlated with outcomes but do not actually change them. For a product review, tone or sentiment is causal for sales, whereas flourish and word choice might not be. For a drug molecule, certain structural features may drive symptom relief, while others are incidental. The key idea is that the treatment we observe is a mixture of both kinds of factors. If a model learns from this mixture directly, non-causal aspects can act like stand-ins for background variables and mislead effect estimates. The authors mathematically prove that to avoid bias, one must first transform the complex treatment into a new representation that preserves only the causal information and discards the rest.
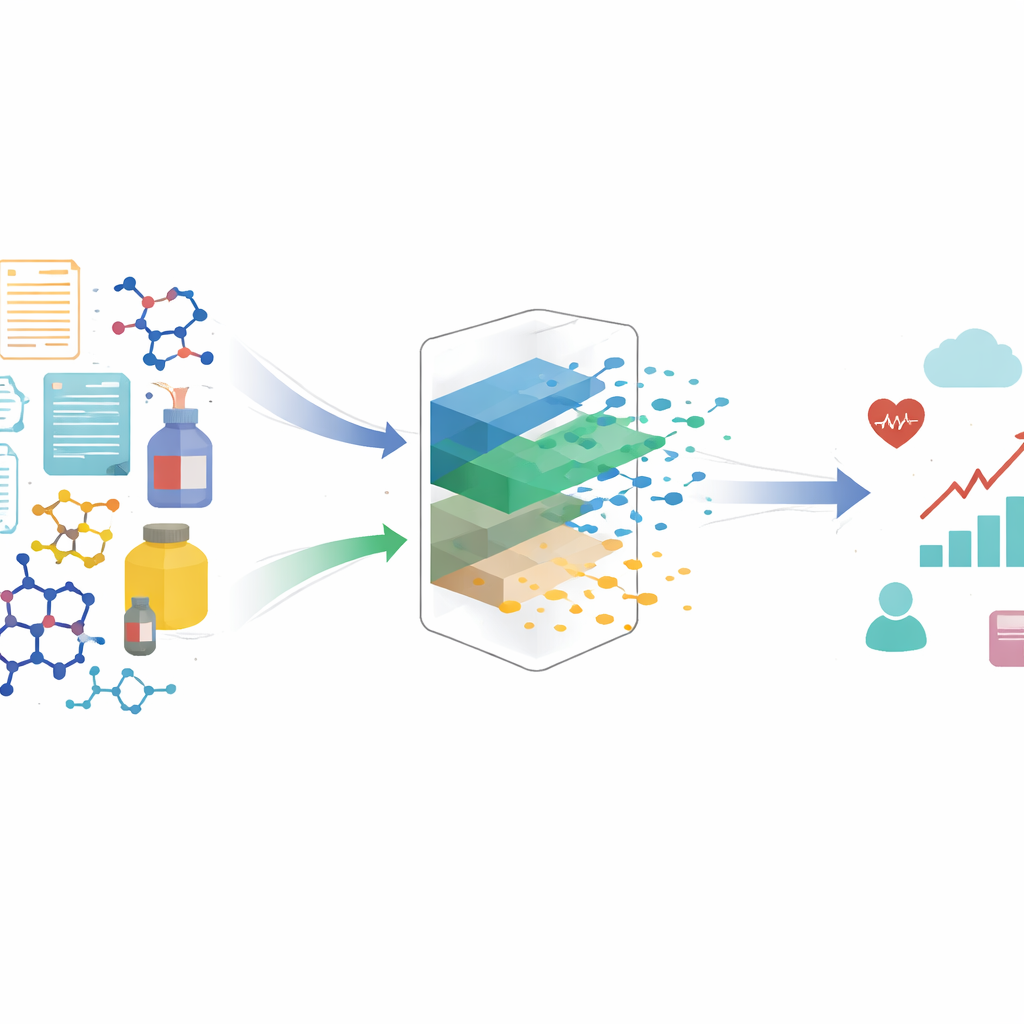
Learning better representations through comparisons
The authors propose a contrastive learning approach to automatically build this cleaner representation. Instead of treating each treatment in isolation, the method looks at pairs of similar and dissimilar examples. Two treatments that appear in the same context and lead to very similar outcomes are treated as if they share the same underlying causal factors, even if their surface details differ. By pulling these similar pairs closer together in a learned representation space, and pushing apart pairs that share the same context but lead to different outcomes, the algorithm is encouraged to keep what matters for the outcome and to ignore superficial variation. Under reasonable mathematical assumptions, the authors prove that this process recovers exactly the causal part of the treatment and filters out the non-causal part, making it suitable for unbiased causal effect estimation.
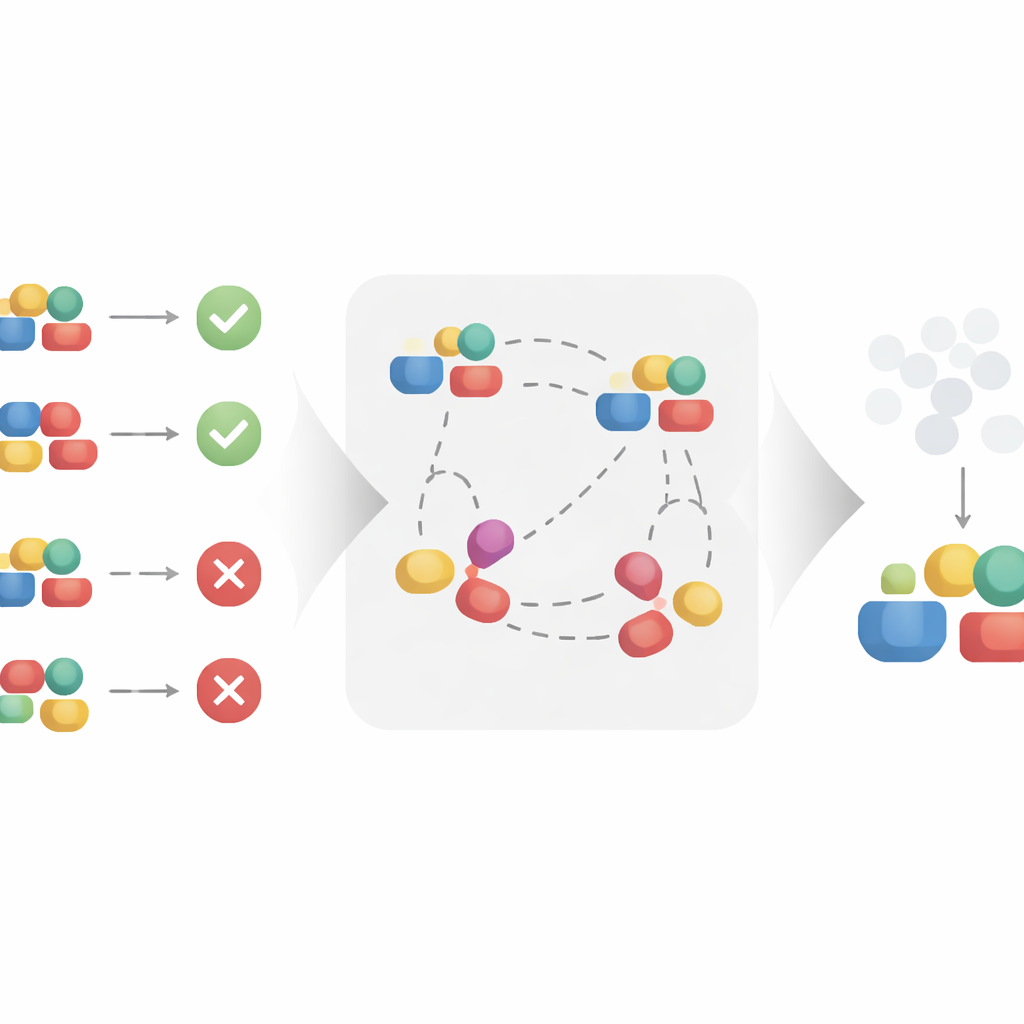
Testing the idea in synthetic and real-world settings
To check whether this theory holds in practice, the authors apply their method to three types of data. First, they construct a synthetic dataset where the causal and non-causal components of the treatment are known by design. This allows them to test whether their method can truly ignore non-causal pieces even when noise is added to the outcomes. Next, they examine molecule data, where treatments are chemical structures and outcomes relate to properties like effectiveness, and a coat recommendation dataset, where items are products in an online marketplace. Across these diverse settings, they compare their contrastive model to standard causal models and to a strong recent competitor designed for structured treatments. While all methods can fit the observed data reasonably well, only the contrastive approach remains stable when the non-causal parts of the treatment are perturbed, indicating that it has successfully learned to focus on the genuine causal drivers.
What this means for smarter, fairer systems
For a general reader, the main message is that not all details in data are created equal. Systems that guide decisions—from what you see in a shopping feed to which drug candidates are advanced—can be misled by patterns that look predictive but are not truly causal. This paper shows that by teaching models to compare similar situations and outcomes, we can build representations of complex treatments that concentrate on the true levers of change. In turn, this leads to more reliable estimates of “what works,” opening the door to better product recommendations, more efficient drug discovery, and more trustworthy AI systems that reason about cause and effect rather than surface-level correlations.
Citation: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
Keywords: causal inference, representation learning, contrastive learning, high-dimensional treatments, machine learning