Clear Sky Science · sv
Kontrastiva representationer av strukturerade behandlingar
Varför denna forskning spelar roll för vardagliga beslut
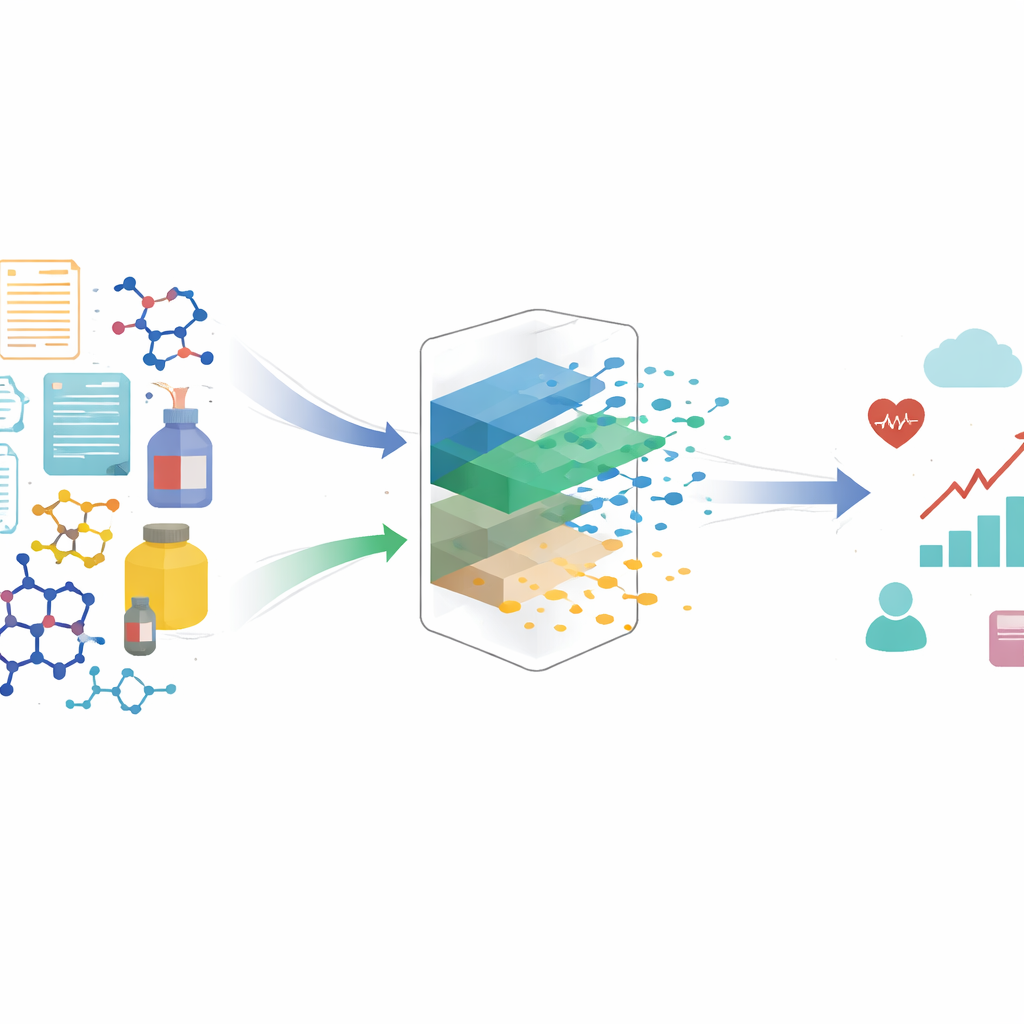
Många av de val som påverkar våra liv styrs av algoritmer: vilka produkter vi ser online, vilka läkemedel som testas, till och med hur medicinska behandlingar utvärderas. Dessa system behandlar ofta komplexa objekt—som en skriven recension, ett molekylärt struktur eller en produktbeskrivning—som om varje detalj är lika viktig. Denna artikel visar att ett sådant förhållningssätt tyst kan förvränga vår förståelse av orsak och verkan, och introducerar en ny metod som hjälper algoritmer att fokusera på det som verkligen driver utfall, inte på distraherande detaljer.
Problemet med att förväxla stil och substans
När forskare eller dataanalytiker uppskattar effekten av en ”behandling” (till exempel att visa en annons, rekommendera en produkt eller ordinera ett läkemedel) antar de ofta att behandlingen kan beskrivas med ett enkelt tal eller en kategori. I verkligheten är behandlingar ofta rika, strukturerade objekt: en hel textrecension, en bild eller en komplex kemisk struktur. Dolda i dessa objekt finns olika aspekter: vissa påverkar faktiskt utfallet (som hur positiv en recension är), medan andra främst ändrar hur objektet ser ut eller låter (som skrivstil). Författarna visar att om vi matar dessa rika behandlingar direkt till standardkausala modeller kan modellerna missta dessa stilistiska eller icke-kausala aspekter för verkliga drivkrafter, även när vi noggrant har mätt alla uppenbara confounders. Resultatet blir snedvridna uppskattningar av vad som verkligen fungerar.
Att skilja meningsfull signal från distraherande brus
För att hantera detta skiljer artikeln mellan ”kausala” dolda faktorer—de delar av en behandling som faktiskt påverkar utfallet—och ”icke-kausala” faktorer, som kan korrelera med utfall men inte faktiskt förändrar dem. För en produktrecension är ton eller sentiment kausalt för försäljning, medan blommande språk och ordval kanske inte är det. För en läkemedelsmolekyl kan vissa strukturella egenskaper driva symtomlindring, medan andra är tillfälliga. Nyckelidén är att den behandling vi observerar är en blandning av båda typerna av faktorer. Om en modell lär sig från denna blandning direkt kan icke-kausala aspekter fungera som ställföreträdare för bakgrundsvariabler och vilseleda effektskattningar. Författarna bevisar matematiskt att för att undvika bias måste man först transformera den komplexa behandlingen till en ny representation som bevarar endast den kausala informationen och förkastar resten.
Lära bättre representationer genom jämförelser
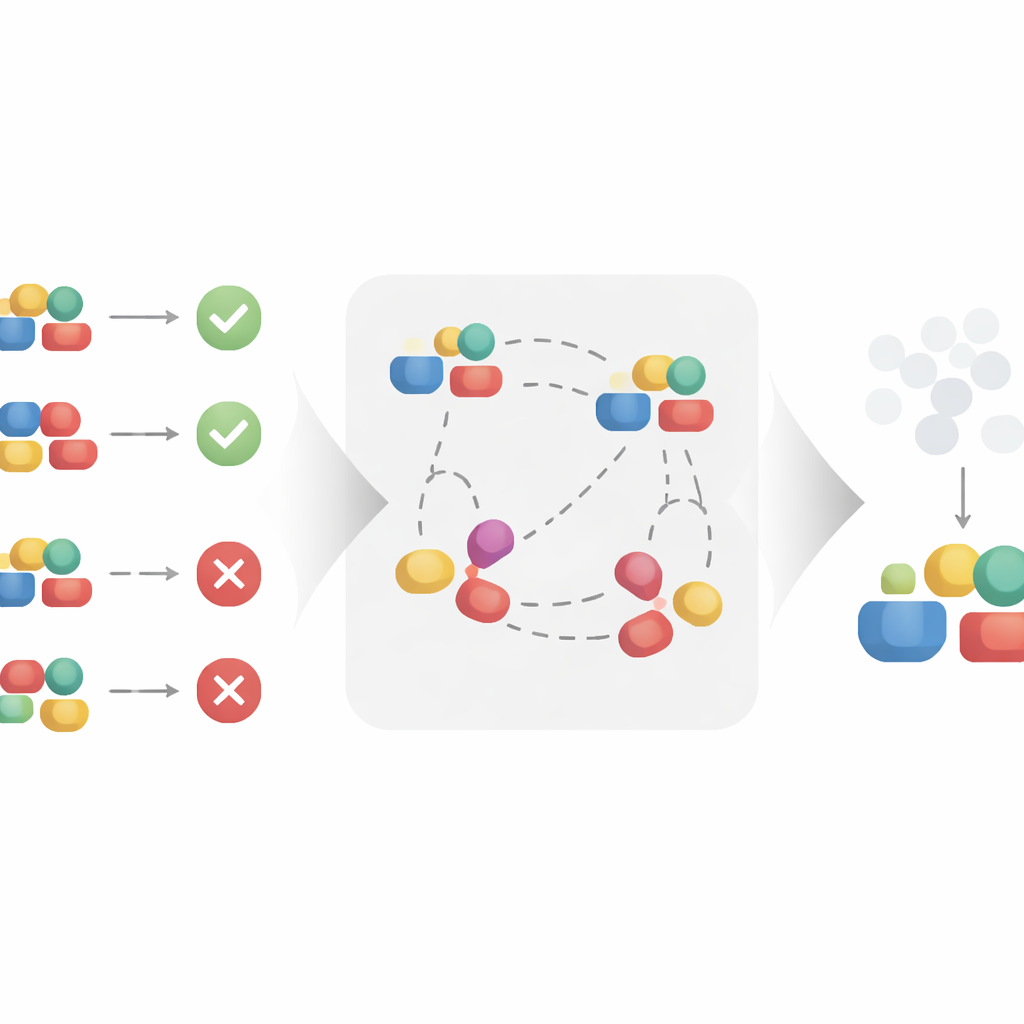
Författarna föreslår en kontrastiv inlärningsmetod för att automatiskt bygga denna renare representation. I stället för att behandla varje behandling isolerat tittar metoden på par av liknande och olikartade exempel. Två behandlingar som förekommer i samma kontext och leder till mycket likartade utfall behandlas som om de delar samma underliggande kausala faktorer, även om deras ytliga detaljer skiljer sig åt. Genom att dra dessa liknande par närmare varandra i ett inlärt representationsrum, och samtidigt skjuta isär par som delar samma kontext men leder till olika utfall, uppmuntras algoritmen att behålla det som är viktigt för utfallet och ignorera ytlig variation. Under rimliga matematiska antaganden bevisar författarna att denna process återvinner exakt den kausala delen av behandlingen och filtrerar bort den icke-kausala delen, vilket gör representationen lämpad för obiaserad kausal effektskattning.
Test av idén i syntetiska och verkliga miljöer
För att pröva om denna teori håller i praktiken tillämpar författarna sin metod på tre typer av data. Först konstruerar de en syntetisk datamängd där de kausala och icke-kausala komponenterna av behandlingen är kända per design. Detta låter dem testa om metoden verkligen kan ignorera icke-kausala delar även när brus läggs till i utfallen. Därefter undersöker de molekyldata, där behandlingarna är kemiska strukturer och utfallen relaterar till egenskaper som effektivitet, samt en dataset för rockrekommendationer där föremålen är produkter på en onlinemarknadsplats. I dessa skilda miljöer jämför de sin kontrastiva modell med standardkausala modeller och med en stark, nyligen föreslagen konkurrent utformad för strukturerade behandlingar. Medan alla metoder kan passa de observerade data någorlunda väl, är det endast den kontrastiva metoden som förblir stabil när de icke-kausala delarna av behandlingen manipuleras, vilket indikerar att den framgångsrikt lärt sig att fokusera på de verkliga kausala drivkrafterna.
Vad detta innebär för smartare, mer rättvisa system
För en allmän läsare är huvudbudskapet att inte alla detaljer i data är jämlikt viktiga. System som styr beslut—från vad du ser i ett köpflöde till vilka läkemedelskandidater som går vidare—kan vilseledas av mönster som ser prediktiva ut men inte är verkligt kausala. Denna artikel visar att genom att lära modeller att jämföra liknande situationer och utfall kan vi bygga representationer av komplexa behandlingar som koncentrerar sig på de verkliga spakarna för förändring. Det leder i sin tur till mer tillförlitliga uppskattningar av ”vad som fungerar”, vilket öppnar dörren för bättre produktrekommendationer, effektivare läkemedelsupptäckt och mer förtroendeingivande AI-system som resonerar om orsak och verkan i stället för ytlig korrelation.
Citering: Corcoll, O., Vlontzos, A., O’Riordan, M. et al. Contrastive representations of structured treatments. npj Artif. Intell. 2, 49 (2026). https://doi.org/10.1038/s44387-026-00105-2
Nyckelord: kausal inferens, representationsinlärning, kontrastiv inlärning, höga-dimensionella behandlingar, maskininlärning