Clear Sky Science · zh
为智能手术室打造的专用基础模型
手术室里的更智能帮助
现代手术发生在一个拥挤且高科技的环境中,人员、机器人、摄像机和显示器必须无误地协同工作。本文介绍了 ORQA,这是一种专为手术室设计的新型人工智能。与主要处理文字和简单图像的常见聊天机器人不同,ORQA 被构建为能在手术过程中观察、聆听并解释所发生的一切,从而支持团队、发现隐患并最终提高手术安全性。
为什么现有的人工智能在手术中表现不佳
许多令世界惊叹的人工智能工具是在互联网上的图像、视频和文本上训练的。它们可以解释医学术语或描述常见手术,但手术室的视觉世界截然不同。多台摄像机呈现重叠视角,机器人臂在人体附近移动,器械体积小且表面反光,许多事件同时发生。通用 AI 模型常常漏掉关键细节:它们可能识别出有外科医生在场,但无法定位特定器械、预测机器人下一步动作,或识别无菌区被破坏的情况。作者在测试领先的视觉-语言系统(包括商业模型和一个强大的开源模型)时,发现它们在外科任务上的表现仅略优于基于最常见答案的猜测。
将外科工作流程转化为问答
为了系统地衡量并改进机器对手术的理解,研究人员创建了 ORQA 基准。他们整合了四个包含真实和模拟手术室的丰富数据集,这些数据包括外部摄像视角、外科医生佩戴的视频、三维场景重建、音频、机器人日志等。从这些来源生成了超过一亿条关于手术室内发生情况的问答对。这些问题涵盖 23 类任务,例如在场人数、正在使用的器械、正在进行的动作、器械在三维空间中的位置、是否存在无菌破坏,以及机器人下一步将做什么。通过将这庞大样本池精简为 100 万个多样化的训练示例及独立的测试集,他们为任何声称理解手术的 AI 模型建立了一个共同的衡量标准。
为手术室打造的基础模型
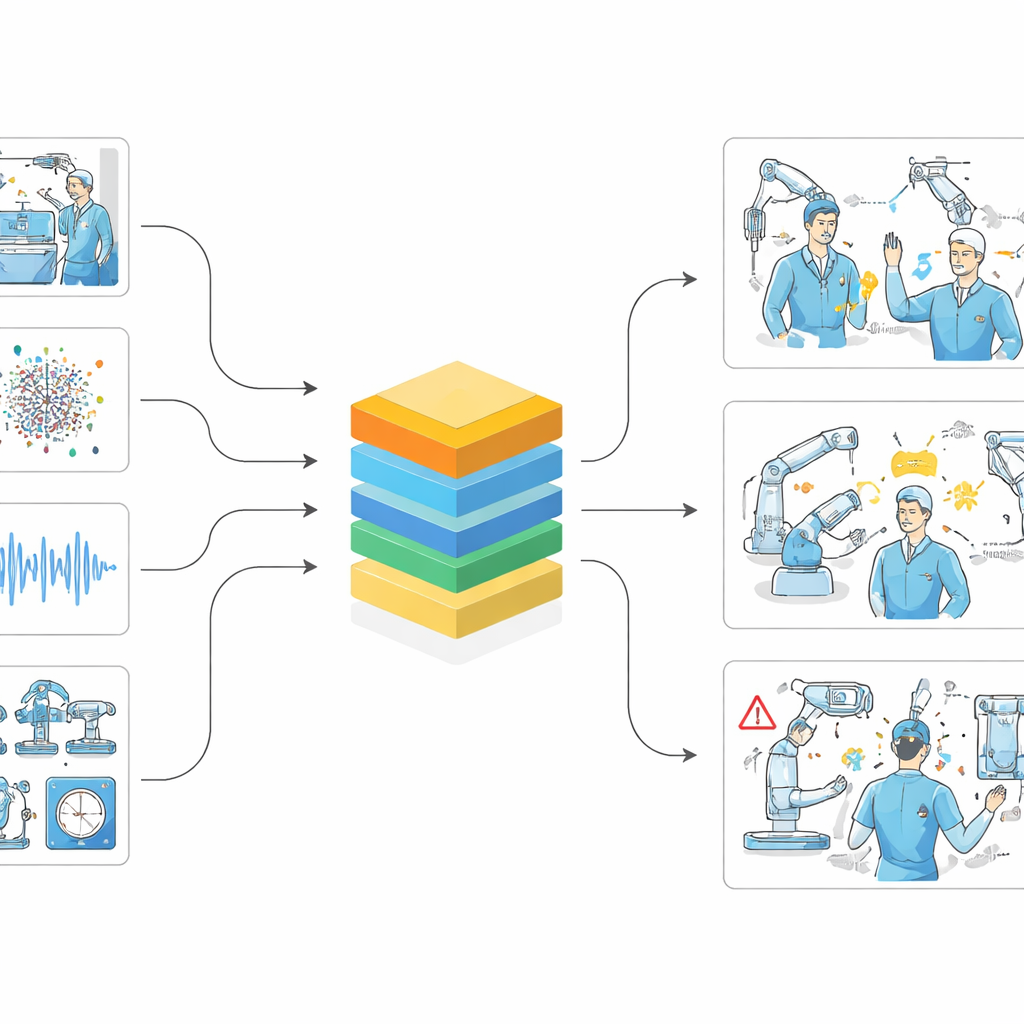
利用该基准,团队训练了 ORQA——一个融合多路手术数据的专用基础模型。单独的编码器分别处理视频帧、三维点云、声音、语音转录、机器人遥测和跟踪数据,并将它们转为共享的数值表示。然后一个大型语言模型在该综合信号上进行推理,以回答关于场景的问题。在 ORQA 基准上,这个针对领域而调优的系统将通用模型的性能提升了一倍多,并且在广泛任务上均有显著改善——识别动作、定位器械、推理距离和角色、以及检查与安全相关的条件。该模型甚至可以扩展记忆结构以跟踪手术随时间的进展,表明通过更丰富的时间建模还可能获得更大提升。
让外科人工智能变得快速且实用
强大的模型通常对于在医院内部实时使用来说过于庞大,医院内的计算设备可能有限且出于隐私原因对远程服务器的网络连接受限。为此,作者采用了一种称为蒸馏的过程,即由大型“教师”模型训练更小的“学生”版本。他们提出了三种紧凑的 ORQA 变体,运行速度提高数倍,同时保留了大部分原始准确性。这些轻量模型可在单张显卡或边缘设备上本地运行,允许在手术室内同时监控多个工位,避免将敏感的患者数据流向云端。结构化且可追溯的输出——例如人员、器械及其交互的列表——也使临床人员更容易检查、审计并信任系统的行为。
这对未来手术意味着什么
简而言之,这项研究表明手术需要其专属的人工智能,必须直接在真实手术的影像与声音上进行训练,而不是依赖通用的网络内容。ORQA 表明,当模型暴露于合适的多模态手术数据时,它能够可靠地跟踪谁在做什么、器械在哪里、手术如何进展以及是否可能发生不安全事件。尽管在此类系统能直接指导手术之前仍有大量工作要做,ORQA 及其基准为更智能的助手、更好的记录,以及最终更自主、更协调的手术室奠定了基础。
引用: Özsoy, E., Pellegrini, C., Bani-Harouni, D. et al. Specialized foundation models for intelligent operating rooms. npj Digit. Med. 9, 362 (2026). https://doi.org/10.1038/s41746-026-02631-4
关键词: 外科人工智能, 手术室, 多模态模型, 医疗机器人, 患者安全