Clear Sky Science · zh
scDecorr:基于特征去相关的表示学习实现多次单细胞实验的自监督对齐
将单细胞数据汇聚的重要性
现代生物学现在可以读取单个细胞中成千上万基因的活性,从而揭示罕见的细胞类型和细微的疾病状态。但这些单细胞实验通常在不同实验室、使用不同仪器和协议进行,这使得它们的结果难以合并。本文提出了 scDecorr,一种新的计算方法,可以自动对齐这些多样的数据集,使相似的细胞聚集在一起,即便它们的测量方式大相径庭。这让研究人员更容易构建丰富的细胞图谱并在不同研究间重复利用数据。
众多数据集,一种通用语言
单细胞 RNA 测序测量每个细胞中哪些基因被激活。从理论上讲,这使科学家能够比较不同器官、患者或疾病状态下的细胞。但在实践中,称为批次效应的技术性差异可能淹没真实的生物学差异。同一类型的细胞可能仅因在另一日处理或使用另一种技术而看起来不同。scDecorr 通过为每个细胞学习一个紧凑的数值“描述”,把行为相似的细胞放在彼此附近,而将不同的细胞分开,从而应对这一问题。关键是,它在不需要专家提供的细胞类型标签的情况下完成这一点,适用于大规模且杂乱的数据集。
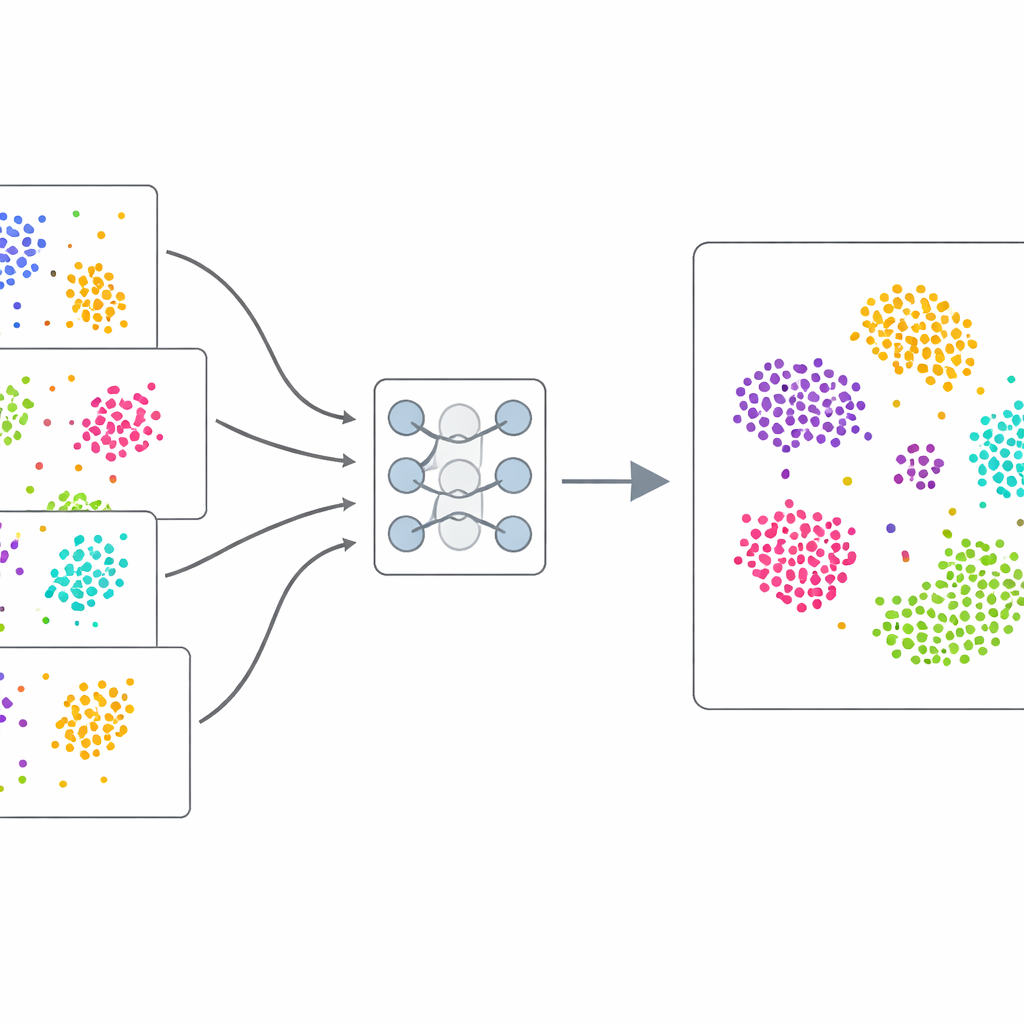
从数据本身学习
scDecorr 不依赖手工标注的示例,而是使用自监督学习:数据自身提供训练信号。对于每个细胞,该方法创建其基因表达模式的两个略微扭曲的副本,例如通过随机丢弃或打乱一些数值。一个双支神经网络处理这两个版本,并被训练为对同一细胞的两个视图产生非常相似的内部摘要,而对不同细胞产生不同的摘要。与此同时,scDecorr 鼓励这些摘要的每个分量携带独特信息,从而避免某个特征简单地重复另一个。这个“去相关”步骤有助于防止模型坍缩到少数占主导的模式上,而是捕获更广泛的生物学信号。
悄然校正技术差异
一个核心挑战在于来自不同研究的细胞遵循略有不同的统计规律。如果简单混合这些数据,模型可能会将技术差异误判为生物学差异。scDecorr 借用领域自适应的想法来解决这一点。所有批次共享相同的编码器网络,但每个批次有各自的归一化层,用以重新缩放特征,使得在该批次内每个维度具有标准形态。随后在每个批次内部单独应用去相关目标,而所有批次仍必须通过相同的编码器。这温和地推动编码器生成在不同实验间遵循共享结构的表示,使得来自不同来源的相似细胞在学习到的空间中自然对齐,而无需任何显式的匹配步骤。
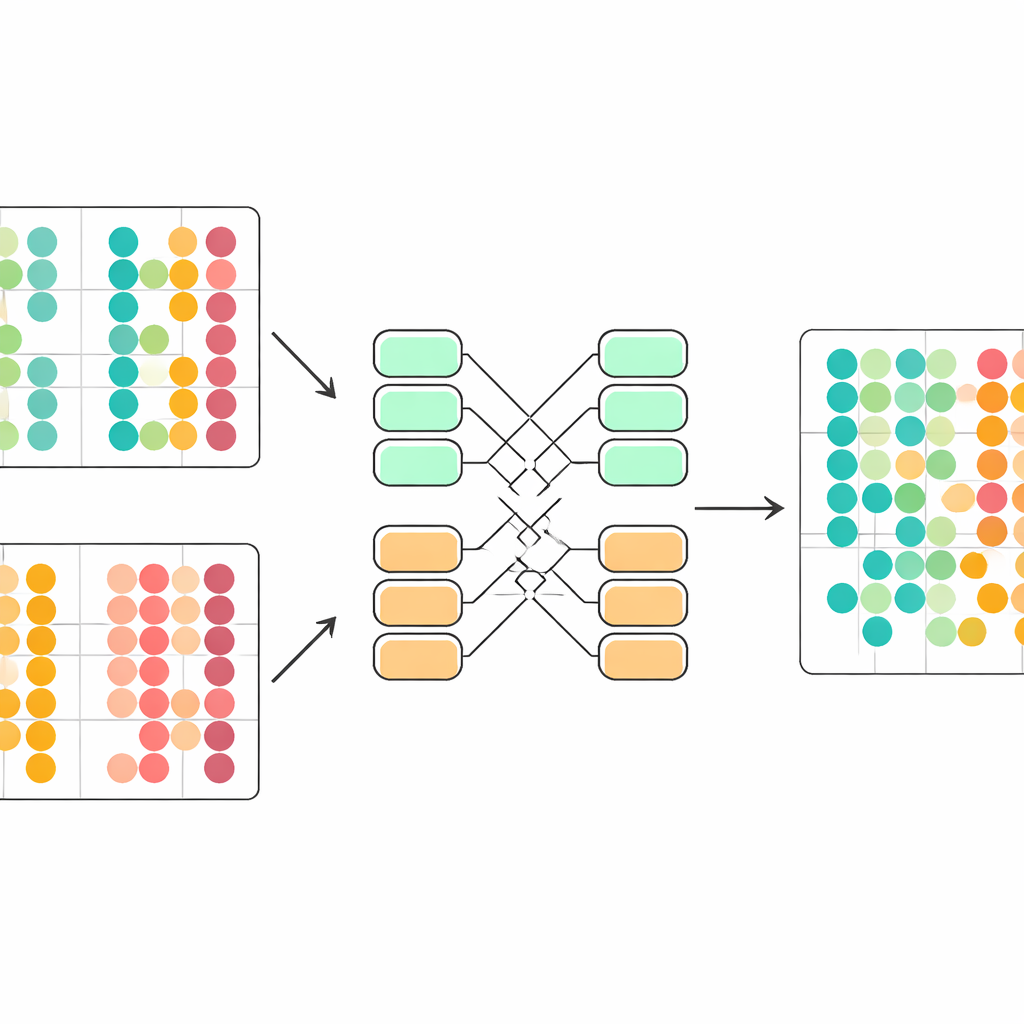
在真实数据集上优于现有工具
作者在五个具有挑战性的单细胞数据集合上对 scDecorr 进行了严格测试,涵盖人类与小鼠组织、跨器官的免疫细胞以及多种测序技术。他们将其与若干广泛使用的整合工具以及主成分分析等简单方法进行了比较。在一项又一项任务中,scDecorr 更好地保留了细胞的真实生物学分组 —— 以标准聚类评分衡量 —— 同时又在混合批次方面足以消除明显的技术分离。它在避免过度校正方面尤其强劲,后者往往将不同细胞类型错误地合并以消除批次效应;此外它倾向于为稀有或批次特异的细胞类型保持清晰边界,而其他方法则会模糊或丢失这些类型。
可靠的细胞标签迁移
除了合并数据集之外,scDecorr 还在标签迁移任务中进行了测试:使用带注释的参考数据集为新的未标注数据指定细胞类型标签。通过在 scDecorr 表示空间中使用简单分类器或聚类,该方法能够跨不同化学处理、平台和研究可靠地恢复已知细胞类型。它常常在分类准确性上超越或匹配现有最佳工具,同时更一致地保留每个数据集内部的细胞类型结构。即便只有部分细胞类型在数据集之间共享,或批次高度不平衡,这一性能仍然成立,尽管作者指出在极度不匹配的设置下对所有方法来说仍然具有挑战性。
对未来细胞图谱的意义
简言之,scDecorr 提供了一种使多样的单细胞实验“说同一种语言”的方法,而不需要通过粗暴的校正抹去重要差异。通过学习丰富的、低维的摘要,这些摘要对噪声具有鲁棒性但又能敏感地反映真实的生物多样性,scDecorr 使得跨组织、技术和研究构建联合细胞地图并用现有数据注释新实验变得更容易。尽管在非常不平衡的数据集上仍有改进空间,scDecorr 提供了一种更谨慎且强大的批次校正替代方案,帮助科学家以更少的技术失真观察真实的细胞景观。
引用: Sanyal, R., Xu, Y., Kim, H. et al. scDecorr: feature decorrelation based representation learning enables self-supervised alignment of multiple single-cell experiments. Sci Rep 16, 13782 (2026). https://doi.org/10.1038/s41598-026-50586-z
关键词: 单细胞 RNA 测序, 数据整合, 自监督学习, 批次效应校正, 细胞图谱